 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWECAR: An End-Edge Collaborative Inference and Training Framework for WiFi-Based Continuous Human Activity Recognition
Mar 09, 2025WiFi-based human activity recognition (HAR) holds significant promise for ubiquitous sensing in smart environments. A critical challenge lies in enabling systems to dynamically adapt to evolving scenarios, learning new activities without catastrophic forgetting of prior knowledge, while adhering to the stringent computational constraints of edge devices. Current approaches struggle to reconcile these requirements due to prohibitive storage demands for retaining historical data and inefficient parameter utilization. We propose WECAR, an end-edge collaborative inference and training framework for WiFi-based continuous HAR, which decouples computational workloads to overcome these limitations. In this framework, edge devices handle model training, lightweight optimization, and updates, while end devices perform efficient inference. WECAR introduces two key innovations, i.e., dynamic continual learning with parameter efficiency and hierarchical distillation for end deployment. For the former, we propose a transformer-based architecture enhanced by task-specific dynamic model expansion and stability-aware selective retraining. For the latter, we propose a dual-phase distillation mechanism that includes multi-head self-attention relation distillation and prefix relation distillation. We implement WECAR based on heterogeneous hardware using Jetson Nano as edge devices and the ESP32 as end devices, respectively. Our experiments across three public WiFi datasets reveal that WECAR not only outperforms several state-of-the-art methods in performance and parameter efficiency, but also achieves a substantial reduction in the model's parameter count post-optimization without sacrificing accuracy. This validates its practicality for resource-constrained environments.
ConSense: Continually Sensing Human Activity with WiFi via Growing and Picking
Feb 18, 2025WiFi-based human activity recognition (HAR) holds significant application potential across various fields. To handle dynamic environments where new activities are continuously introduced, WiFi-based HAR systems must adapt by learning new concepts without forgetting previously learned ones. Furthermore, retaining knowledge from old activities by storing historical exemplar is impractical for WiFi-based HAR due to privacy concerns and limited storage capacity of edge devices. In this work, we propose ConSense, a lightweight and fast-adapted exemplar-free class incremental learning framework for WiFi-based HAR. The framework leverages the transformer architecture and involves dynamic model expansion and selective retraining to preserve previously learned knowledge while integrating new information. Specifically, during incremental sessions, small-scale trainable parameters that are trained specifically on the data of each task are added in the multi-head self-attention layer. In addition, a selective retraining strategy that dynamically adjusts the weights in multilayer perceptron based on the performance stability of neurons across tasks is used. Rather than training the entire model, the proposed strategies of dynamic model expansion and selective retraining reduce the overall computational load while balancing stability on previous tasks and plasticity on new tasks. Evaluation results on three public WiFi datasets demonstrate that ConSense not only outperforms several competitive approaches but also requires fewer parameters, highlighting its practical utility in class-incremental scenarios for HAR.
Efficient Federated Learning Using Dynamic Update and Adaptive Pruning with Momentum on Shared Server Data
Aug 11, 2024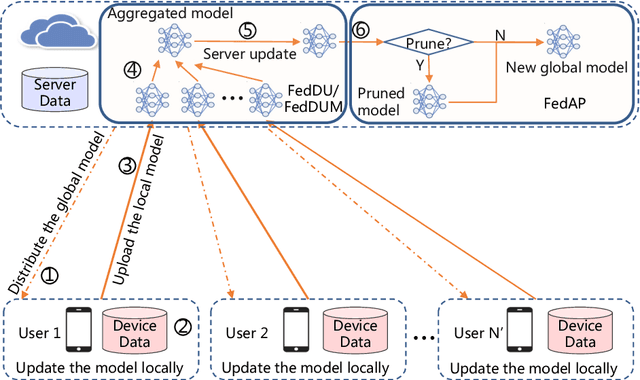

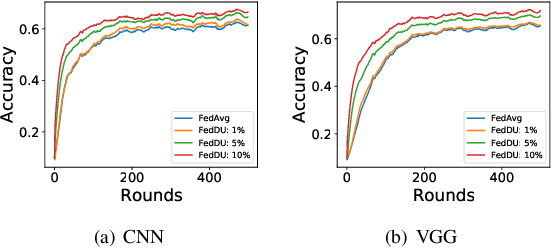
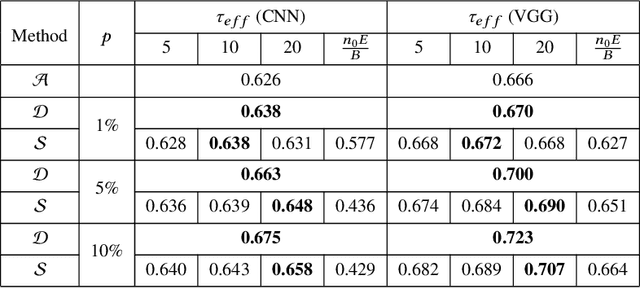
Despite achieving remarkable performance, Federated Learning (FL) encounters two important problems, i.e., low training efficiency and limited computational resources. In this paper, we propose a new FL framework, i.e., FedDUMAP, with three original contributions, to leverage the shared insensitive data on the server in addition to the distributed data in edge devices so as to efficiently train a global model. First, we propose a simple dynamic server update algorithm, which takes advantage of the shared insensitive data on the server while dynamically adjusting the update steps on the server in order to speed up the convergence and improve the accuracy. Second, we propose an adaptive optimization method with the dynamic server update algorithm to exploit the global momentum on the server and each local device for superior accuracy. Third, we develop a layer-adaptive model pruning method to carry out specific pruning operations, which is adapted to the diverse features of each layer so as to attain an excellent trade-off between effectiveness and efficiency. Our proposed FL model, FedDUMAP, combines the three original techniques and has a significantly better performance compared with baseline approaches in terms of efficiency (up to 16.9 times faster), accuracy (up to 20.4% higher), and computational cost (up to 62.6% smaller).
Efficient Asynchronous Federated Learning with Sparsification and Quantization
Jan 06, 2024While data is distributed in multiple edge devices, Federated Learning (FL) is attracting more and more attention to collaboratively train a machine learning model without transferring raw data. FL generally exploits a parameter server and a large number of edge devices during the whole process of the model training, while several devices are selected in each round. However, straggler devices may slow down the training process or even make the system crash during training. Meanwhile, other idle edge devices remain unused. As the bandwidth between the devices and the server is relatively low, the communication of intermediate data becomes a bottleneck. In this paper, we propose Time-Efficient Asynchronous federated learning with Sparsification and Quantization, i.e., TEASQ-Fed. TEASQ-Fed can fully exploit edge devices to asynchronously participate in the training process by actively applying for tasks. We utilize control parameters to choose an appropriate number of parallel edge devices, which simultaneously execute the training tasks. In addition, we introduce a caching mechanism and weighted averaging with respect to model staleness to further improve the accuracy. Furthermore, we propose a sparsification and quantitation approach to compress the intermediate data to accelerate the training. The experimental results reveal that TEASQ-Fed improves the accuracy (up to 16.67% higher) while accelerating the convergence of model training (up to twice faster).
Multi-Job Intelligent Scheduling with Cross-Device Federated Learning
Nov 24, 2022
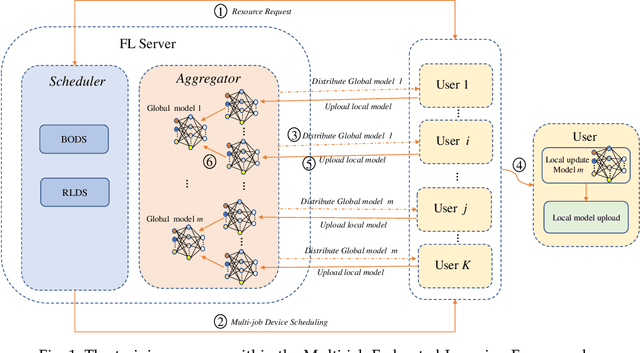
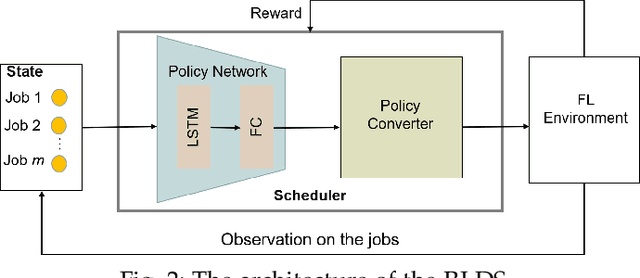
Recent years have witnessed a large amount of decentralized data in various (edge) devices of end-users, while the decentralized data aggregation remains complicated for machine learning jobs because of regulations and laws. As a practical approach to handling decentralized data, Federated Learning (FL) enables collaborative global machine learning model training without sharing sensitive raw data. The servers schedule devices to jobs within the training process of FL. In contrast, device scheduling with multiple jobs in FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework, which enables the training process of multiple jobs in parallel. The multi-job FL framework is composed of a system model and a scheduling method. The system model enables a parallel training process of multiple jobs, with a cost model based on the data fairness and the training time of diverse devices during the parallel training process. We propose a novel intelligent scheduling approach based on multiple scheduling methods, including an original reinforcement learning-based scheduling method and an original Bayesian optimization-based scheduling method, which corresponds to a small cost while scheduling devices to multiple jobs. We conduct extensive experimentation with diverse jobs and datasets. The experimental results reveal that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 12.73 times faster) and accuracy (up to 46.4% higher).
FedDUAP: Federated Learning with Dynamic Update and Adaptive Pruning Using Shared Data on the Server
Apr 25, 2022
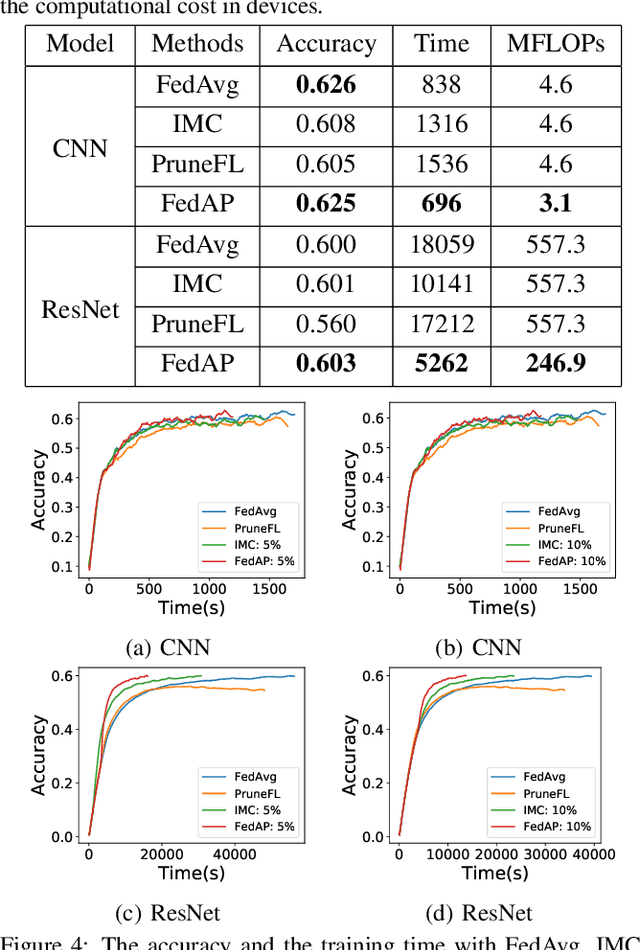
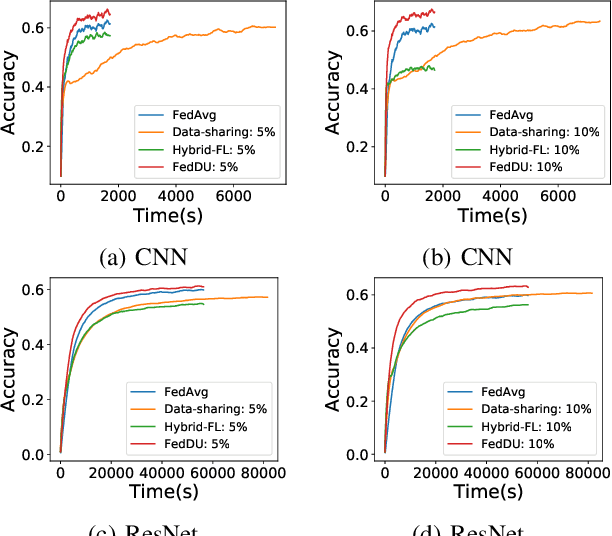
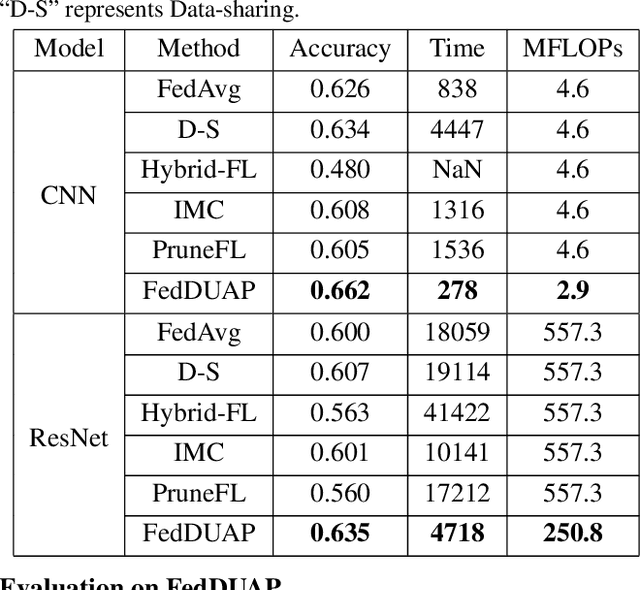
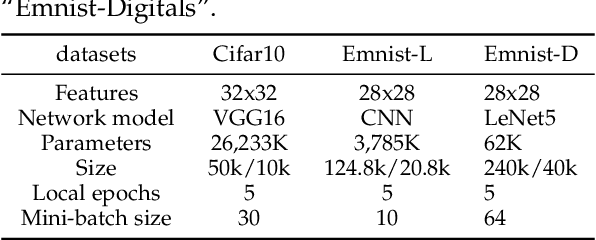
Despite achieving remarkable performance, Federated Learning (FL) suffers from two critical challenges, i.e., limited computational resources and low training efficiency. In this paper, we propose a novel FL framework, i.e., FedDUAP, with two original contributions, to exploit the insensitive data on the server and the decentralized data in edge devices to further improve the training efficiency. First, a dynamic server update algorithm is designed to exploit the insensitive data on the server, in order to dynamically determine the optimal steps of the server update for improving the convergence and accuracy of the global model. Second, a layer-adaptive model pruning method is developed to perform unique pruning operations adapted to the different dimensions and importance of multiple layers, to achieve a good balance between efficiency and effectiveness. By integrating the two original techniques together, our proposed FL model, FedDUAP, significantly outperforms baseline approaches in terms of accuracy (up to 4.8% higher), efficiency (up to 2.8 times faster), and computational cost (up to 61.9% smaller).
Efficient Device Scheduling with Multi-Job Federated Learning
Dec 15, 2021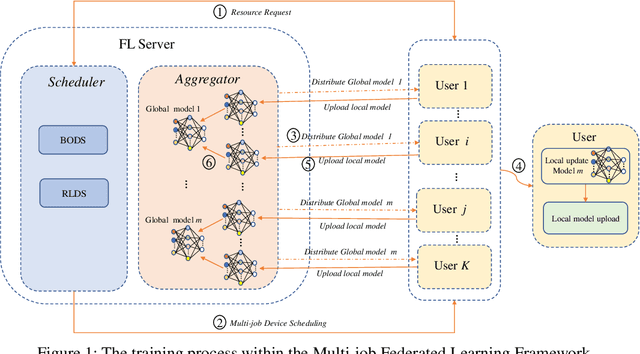
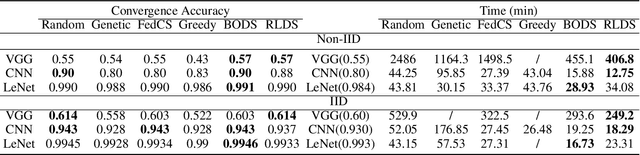
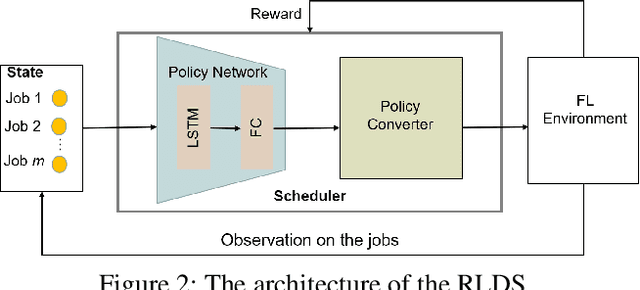
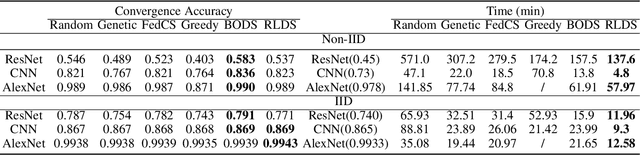
Recent years have witnessed a large amount of decentralized data in multiple (edge) devices of end-users, while the aggregation of the decentralized data remains difficult for machine learning jobs due to laws or regulations. Federated Learning (FL) emerges as an effective approach to handling decentralized data without sharing the sensitive raw data, while collaboratively training global machine learning models. The servers in FL need to select (and schedule) devices during the training process. However, the scheduling of devices for multiple jobs with FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework to enable the parallel training process of multiple jobs. The framework consists of a system model and two scheduling methods. In the system model, we propose a parallel training process of multiple jobs, and construct a cost model based on the training time and the data fairness of various devices during the training process of diverse jobs. We propose a reinforcement learning-based method and a Bayesian optimization-based method to schedule devices for multiple jobs while minimizing the cost. We conduct extensive experimentation with multiple jobs and datasets. The experimental results show that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 8.67 times faster) and accuracy (up to 44.6% higher).