 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
May 25, 2026Audio-visual generation is rapidly advancing from short clips to minute-long content, while existing evaluation protocols remain largely confined to short-form settings. Existing benchmarks primarily focus on 5--10 second text-conditioned generation and rarely support unified evaluation across text, image, and video conditioning modalities. Moreover, they provide limited insight into how identity consistency, narrative coherence, and audio-visual alignment degrade over extended temporal horizons. To bridge this gap, we introduce LongAV-Compass, a systematic benchmark for minute-long audio-visual generation. LongAV-Compass contains 284 curated test cases spanning text-to-audio-video (T2AV), image-to-audio-video (I2AV), and video-to-audio-video (V2AV), organized by application scenario and generation complexity. The benchmark combines taxonomy-guided benchmark construction with a unified evaluation framework that integrates MLLM-assisted assessment with complementary perceptual and multimodal metrics, including DINO-v2, ArcFace, CLIP, and ImageBind. The framework evaluates more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Through experiments on 11 representative models together with human-alignment validation, LongAV-Compass provides a diagnostic testbed for analyzing the limitations of current systems in sustaining coherent, semantically aligned, and temporally consistent minute-scale audio-visual generation across diverse input modalities.
SkillTester: Benchmarking Utility and Security of Agent Skills
Mar 28, 2026This technical report presents SkillTester, a tool for evaluating the utility and security of agent skills. Its evaluation framework combines paired baseline and with-skill execution conditions with a separate security probe suite. Grounded in a comparative utility principle and a user-facing simplicity principle, the framework normalizes raw execution artifacts into a utility score, a security score, and a three-level security status label. More broadly, it can be understood as a comparative quality-assurance harness for agent skills in an agent-first world. The public service is deployed at https://skilltester.ai, and the broader project is maintained at https://github.com/skilltester-ai/skilltester.
A Simple Baseline for Unifying Understanding, Generation, and Editing via Vanilla Next-token Prediction
Mar 05, 2026In this work, we introduce Wallaroo, a simple autoregressive baseline that leverages next-token prediction to unify multi-modal understanding, image generation, and editing at the same time. Moreover, Wallaroo supports multi-resolution image input and output, as well as bilingual support for both Chinese and English. We decouple the visual encoding into separate pathways and apply a four-stage training strategy to reshape the model's capabilities. Experiments are conducted on various benchmarks where Wallaroo produces competitive performance or exceeds other unified models, suggesting the great potential of autoregressive models in unifying multi-modality understanding and generation. Our code is available at https://github.com/JiePKU/Wallaroo.
Your Inference Request Will Become a Black Box: Confidential Inference for Cloud-based Large Language Models
Feb 27, 2026The increasing reliance on cloud-hosted Large Language Models (LLMs) exposes sensitive client data, such as prompts and responses, to potential privacy breaches by service providers. Existing approaches fail to ensure privacy, maintain model performance, and preserve computational efficiency simultaneously. To address this challenge, we propose Talaria, a confidential inference framework that partitions the LLM pipeline to protect client data without compromising the cloud's model intellectual property or inference quality. Talaria executes sensitive, weight-independent operations within a client-controlled Confidential Virtual Machine (CVM) while offloading weight-dependent computations to the cloud GPUs. The interaction between these environments is secured by our Reversible Masked Outsourcing (ReMO) protocol, which uses a hybrid masking technique to reversibly obscure intermediate data before outsourcing computations. Extensive evaluations show that Talaria can defend against state-of-the-art token inference attacks, reducing token reconstruction accuracy from over 97.5% to an average of 1.34%, all while being a lossless mechanism that guarantees output identical to the original model without significantly decreasing efficiency and scalability. To the best of our knowledge, this is the first work that ensures clients' prompts and responses remain inaccessible to the cloud, while also preserving model privacy, performance, and efficiency.
Efficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
Effective Online 3D Bin Packing with Lookahead Parcels Using Monte Carlo Tree Search
Jan 06, 2026Online 3D Bin Packing (3D-BP) with robotic arms is crucial for reducing transportation and labor costs in modern logistics. While Deep Reinforcement Learning (DRL) has shown strong performance, it often fails to adapt to real-world short-term distribution shifts, which arise as different batches of goods arrive sequentially, causing performance drops. We argue that the short-term lookahead information available in modern logistics systems is key to mitigating this issue, especially during distribution shifts. We formulate online 3D-BP with lookahead parcels as a Model Predictive Control (MPC) problem and adapt the Monte Carlo Tree Search (MCTS) framework to solve it. Our framework employs a dynamic exploration prior that automatically balances a learned RL policy and a robust random policy based on the lookahead characteristics. Additionally, we design an auxiliary reward to penalize long-term spatial waste from individual placements. Extensive experiments on real-world datasets show that our method consistently outperforms state-of-the-art baselines, achieving over 10\% gains under distributional shifts, 4\% average improvement in online deployment, and up to more than 8\% in the best case--demonstrating the effectiveness of our framework.
VeFIA: An Efficient Inference Auditing Framework for Vertical Federated Collaborative Software
Jul 03, 2025



Vertical Federated Learning (VFL) is a distributed AI software deployment mechanism for cross-silo collaboration without accessing participants' data. However, existing VFL work lacks a mechanism to audit the execution correctness of the inference software of the data party. To address this problem, we design a Vertical Federated Inference Auditing (VeFIA) framework. VeFIA helps the task party to audit whether the data party's inference software is executed as expected during large-scale inference without leaking the data privacy of the data party or introducing additional latency to the inference system. The core of VeFIA is that the task party can use the inference results from a framework with Trusted Execution Environments (TEE) and the coordinator to validate the correctness of the data party's computation results. VeFIA guarantees that, as long as the abnormal inference exceeds 5.4%, the task party can detect execution anomalies in the inference software with a probability of 99.99%, without incurring any additional online inference latency. VeFIA's random sampling validation achieves 100% positive predictive value, negative predictive value, and true positive rate in detecting abnormal inference. To the best of our knowledge, this is the first paper to discuss the correctness of inference software execution in VFL.
Auditing Data Provenance in Real-world Text-to-Image Diffusion Models for Privacy and Copyright Protection
Jun 13, 2025Text-to-image diffusion model since its propose has significantly influenced the content creation due to its impressive generation capability. However, this capability depends on large-scale text-image datasets gathered from web platforms like social media, posing substantial challenges in copyright compliance and personal privacy leakage. Though there are some efforts devoted to explore approaches for auditing data provenance in text-to-image diffusion models, existing work has unrealistic assumptions that can obtain model internal knowledge, e.g., intermediate results, or the evaluation is not reliable. To fill this gap, we propose a completely black-box auditing framework called Feature Semantic Consistency-based Auditing (FSCA). It utilizes two types of semantic connections within the text-to-image diffusion model for auditing, eliminating the need for access to internal knowledge. To demonstrate the effectiveness of our FSCA framework, we perform extensive experiments on LAION-mi dataset and COCO dataset, and compare with eight state-of-the-art baseline approaches. The results show that FSCA surpasses previous baseline approaches across various metrics and different data distributions, showcasing the superiority of our FSCA. Moreover, we introduce a recall balance strategy and a threshold adjustment strategy, which collectively allows FSCA to reach up a user-level accuracy of 90% in a real-world auditing scenario with only 10 samples/user, highlighting its strong auditing potential in real-world applications. Our code is made available at https://github.com/JiePKU/FSCA.
ChatPD: An LLM-driven Paper-Dataset Networking System
May 28, 2025
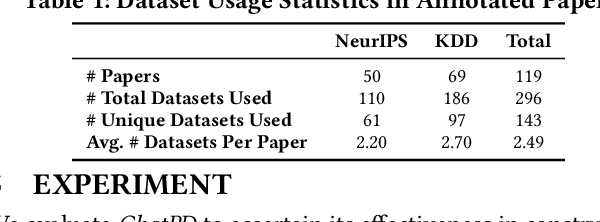


Scientific research heavily depends on suitable datasets for method validation, but existing academic platforms with dataset management like PapersWithCode suffer from inefficiencies in their manual workflow. To overcome this bottleneck, we present a system, called ChatPD, that utilizes Large Language Models (LLMs) to automate dataset information extraction from academic papers and construct a structured paper-dataset network. Our system consists of three key modules: \textit{paper collection}, \textit{dataset information extraction}, and \textit{dataset entity resolution} to construct paper-dataset networks. Specifically, we propose a \textit{Graph Completion and Inference} strategy to map dataset descriptions to their corresponding entities. Through extensive experiments, we demonstrate that ChatPD not only outperforms the existing platform PapersWithCode in dataset usage extraction but also achieves about 90\% precision and recall in entity resolution tasks. Moreover, we have deployed ChatPD to continuously extract which datasets are used in papers, and provide a dataset discovery service, such as task-specific dataset queries and similar dataset recommendations. We open source ChatPD and the current paper-dataset network on this [GitHub repository]{https://github.com/ChatPD-web/ChatPD}.
ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.