 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom EMR Data to Clinical Insight: An LLM-Driven Framework for Automated Pre-Consultation Questionnaire Generation
Aug 01, 2025

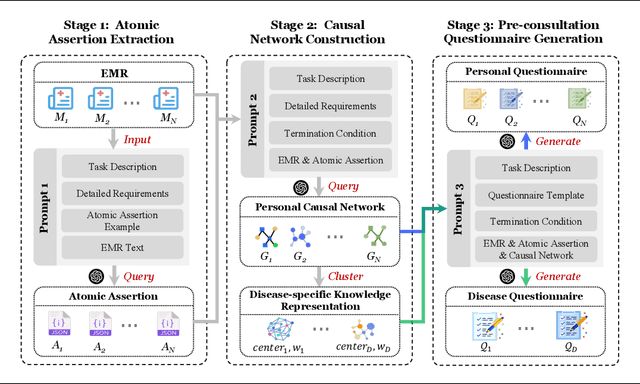

Pre-consultation is a critical component of effective healthcare delivery. However, generating comprehensive pre-consultation questionnaires from complex, voluminous Electronic Medical Records (EMRs) is a challenging task. Direct Large Language Model (LLM) approaches face difficulties in this task, particularly regarding information completeness, logical order, and disease-level synthesis. To address this issue, we propose a novel multi-stage LLM-driven framework: Stage 1 extracts atomic assertions (key facts with timing) from EMRs; Stage 2 constructs personal causal networks and synthesizes disease knowledge by clustering representative networks from an EMR corpus; Stage 3 generates tailored personal and standardized disease-specific questionnaires based on these structured representations. This framework overcomes limitations of direct methods by building explicit clinical knowledge. Evaluated on a real-world EMR dataset and validated by clinical experts, our method demonstrates superior performance in information coverage, diagnostic relevance, understandability, and generation time, highlighting its practical potential to enhance patient information collection.
ChatPD: An LLM-driven Paper-Dataset Networking System
May 28, 2025


Scientific research heavily depends on suitable datasets for method validation, but existing academic platforms with dataset management like PapersWithCode suffer from inefficiencies in their manual workflow. To overcome this bottleneck, we present a system, called ChatPD, that utilizes Large Language Models (LLMs) to automate dataset information extraction from academic papers and construct a structured paper-dataset network. Our system consists of three key modules: \textit{paper collection}, \textit{dataset information extraction}, and \textit{dataset entity resolution} to construct paper-dataset networks. Specifically, we propose a \textit{Graph Completion and Inference} strategy to map dataset descriptions to their corresponding entities. Through extensive experiments, we demonstrate that ChatPD not only outperforms the existing platform PapersWithCode in dataset usage extraction but also achieves about 90\% precision and recall in entity resolution tasks. Moreover, we have deployed ChatPD to continuously extract which datasets are used in papers, and provide a dataset discovery service, such as task-specific dataset queries and similar dataset recommendations. We open source ChatPD and the current paper-dataset network on this [GitHub repository]{https://github.com/ChatPD-web/ChatPD}.
Cognitive Activation and Chaotic Dynamics in Large Language Models: A Quasi-Lyapunov Analysis of Reasoning Mechanisms
Mar 15, 2025The human-like reasoning capabilities exhibited by Large Language Models (LLMs) challenge the traditional neural network theory's understanding of the flexibility of fixed-parameter systems. This paper proposes the "Cognitive Activation" theory, revealing the essence of LLMs' reasoning mechanisms from the perspective of dynamic systems: the model's reasoning ability stems from a chaotic process of dynamic information extraction in the parameter space. By introducing the Quasi-Lyapunov Exponent (QLE), we quantitatively analyze the chaotic characteristics of the model at different layers. Experiments show that the model's information accumulation follows a nonlinear exponential law, and the Multilayer Perceptron (MLP) accounts for a higher proportion in the final output than the attention mechanism. Further experiments indicate that minor initial value perturbations will have a substantial impact on the model's reasoning ability, confirming the theoretical analysis that large language models are chaotic systems. This research provides a chaos theory framework for the interpretability of LLMs' reasoning and reveals potential pathways for balancing creativity and reliability in model design.
Exploring Gaze Pattern in Autistic Children: Clustering, Visualization, and Prediction
Sep 18, 2024

Autism Spectrum Disorder (ASD) significantly affects the social and communication abilities of children, and eye-tracking is commonly used as a diagnostic tool by identifying associated atypical gaze patterns. Traditional methods demand manual identification of Areas of Interest in gaze patterns, lowering the performance of gaze behavior analysis in ASD subjects. To tackle this limitation, we propose a novel method to automatically analyze gaze behaviors in ASD children with superior accuracy. To be specific, we first apply and optimize seven clustering algorithms to automatically group gaze points to compare ASD subjects with typically developing peers. Subsequently, we extract 63 significant features to fully describe the patterns. These features can describe correlations between ASD diagnosis and gaze patterns. Lastly, using these features as prior knowledge, we train multiple predictive machine learning models to predict and diagnose ASD based on their gaze behaviors. To evaluate our method, we apply our method to three ASD datasets. The experimental and visualization results demonstrate the improvements of clustering algorithms in the analysis of unique gaze patterns in ASD children. Additionally, these predictive machine learning models achieved state-of-the-art prediction performance ($81\%$ AUC) in the field of automatically constructed gaze point features for ASD diagnosis. Our code is available at \url{https://github.com/username/projectname}.
Cross-center Early Sepsis Recognition by Medical Knowledge Guided Collaborative Learning for Data-scarce Hospitals
Feb 11, 2023There are significant regional inequities in health resources around the world. It has become one of the most focused topics to improve health services for data-scarce hospitals and promote health equity through knowledge sharing among medical institutions. Because electronic medical records (EMRs) contain sensitive personal information, privacy protection is unavoidable and essential for multi-hospital collaboration. In this paper, for a common disease in ICU patients, sepsis, we propose a novel cross-center collaborative learning framework guided by medical knowledge, SofaNet, to achieve early recognition of this disease. The Sepsis-3 guideline, published in 2016, defines that sepsis can be diagnosed by satisfying both suspicion of infection and Sequential Organ Failure Assessment (SOFA) greater than or equal to 2. Based on this knowledge, SofaNet adopts a multi-channel GRU structure to predict SOFA values of different systems, which can be seen as an auxiliary task to generate better health status representations for sepsis recognition. Moreover, we only achieve feature distribution alignment in the hidden space during cross-center collaborative learning, which ensures secure and compliant knowledge transfer without raw data exchange. Extensive experiments on two open clinical datasets, MIMIC-III and Challenge, demonstrate that SofaNet can benefit early sepsis recognition when hospitals only have limited EMRs.
A Unified Knowledge Graph Service for Developing Domain Language Models in AI Software
Dec 10, 2022Natural Language Processing (NLP) is one of the core techniques in AI software. As AI is being applied to more and more domains, how to efficiently develop high-quality domain-specific language models becomes a critical question in AI software engineering. Existing domain-specific language model development processes mostly focus on learning a domain-specific pre-trained language model (PLM); when training the domain task-specific language model based on PLM, only a direct (and often unsatisfactory) fine-tuning strategy is adopted commonly. By enhancing the task-specific training procedure with domain knowledge graphs, we propose KnowledgeDA, a unified and low-code domain language model development service. Given domain-specific task texts input by a user, KnowledgeDA can automatically generate a domain-specific language model following three steps: (i) localize domain knowledge entities in texts via an embedding-similarity approach; (ii) generate augmented samples by retrieving replaceable domain entity pairs from two views of both knowledge graph and training data; (iii) select high-quality augmented samples for fine-tuning via confidence-based assessment. We implement a prototype of KnowledgeDA to learn language models for two domains, healthcare and software development. Experiments on five domain-specific NLP tasks verify the effectiveness and generalizability of KnowledgeDA. (Code is publicly available at https://github.com/RuiqingDing/KnowledgeDA.)
Semi-supervised Optimal Transport with Self-paced Ensemble for Cross-hospital Sepsis Early Detection
Jun 18, 2021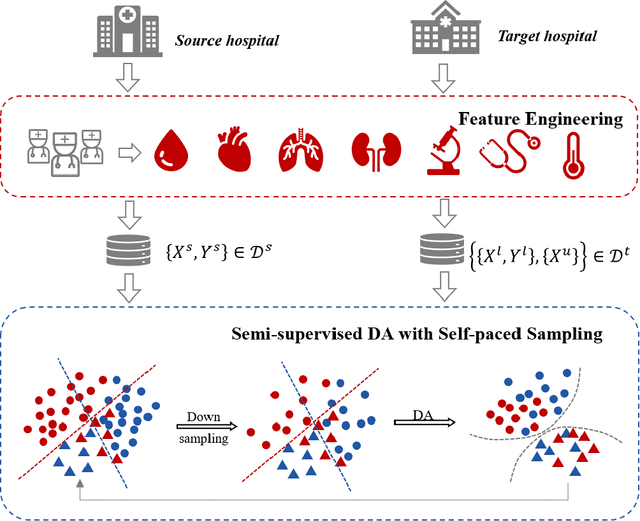


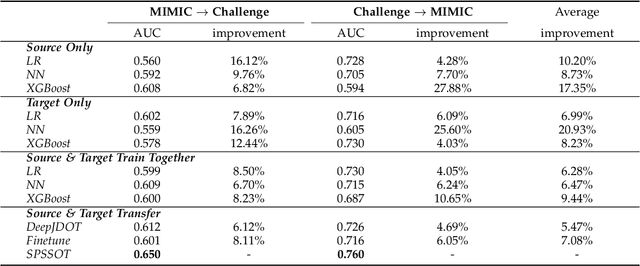
The utilization of computer technology to solve problems in medical scenarios has attracted considerable attention in recent years, which still has great potential and space for exploration. Among them, machine learning has been widely used in the prediction, diagnosis and even treatment of Sepsis. However, state-of-the-art methods require large amounts of labeled medical data for supervised learning. In real-world applications, the lack of labeled data will cause enormous obstacles if one hospital wants to deploy a new Sepsis detection system. Different from the supervised learning setting, we need to use known information (e.g., from another hospital with rich labeled data) to help build a model with acceptable performance, i.e., transfer learning. In this paper, we propose a semi-supervised optimal transport with self-paced ensemble framework for Sepsis early detection, called SPSSOT, to transfer knowledge from the other that has rich labeled data. In SPSSOT, we first extract the same clinical indicators from the source domain (e.g., hospital with rich labeled data) and the target domain (e.g., hospital with little labeled data), then we combine the semi-supervised domain adaptation based on optimal transport theory with self-paced under-sampling to avoid a negative transfer possibly caused by covariate shift and class imbalance. On the whole, SPSSOT is an end-to-end transfer learning method for Sepsis early detection which can automatically select suitable samples from two domains respectively according to the number of iterations and align feature space of two domains. Extensive experiments on two open clinical datasets demonstrate that comparing with other methods, our proposed SPSSOT, can significantly improve the AUC values with only 1% labeled data in the target domain in two transfer learning scenarios, MIMIC $rightarrow$ Challenge and Challenge $rightarrow$ MIMIC.
CreditPrint: Credit Investigation via Geographic Footprints by Deep Learning
Oct 19, 2019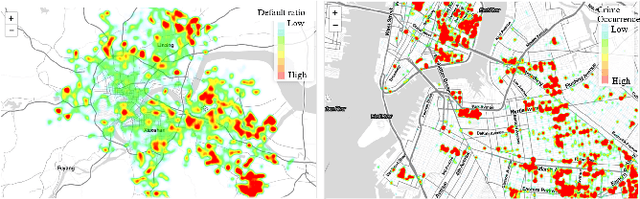
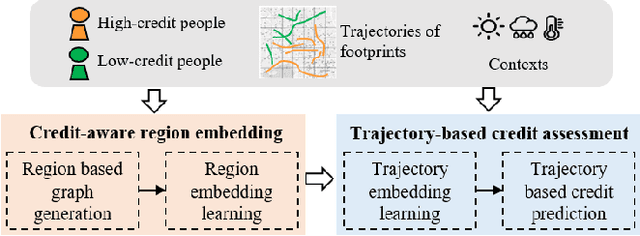

Credit investigation is critical for financial services. Whereas, traditional methods are often restricted as the employed data hardly provide sufficient, timely and reliable information. With the prevalence of smart mobile devices, peoples' geographic footprints can be automatically and constantly collected nowadays, which provides an unprecedented opportunity for credit investigations. Inspired by the observation that locations are somehow related to peoples' credit level, this research aims to enhance credit investigation with users' geographic footprints. To this end, a two-stage credit investigation framework is designed, namely CreditPrint. In the first stage, CreditPrint explores regions' credit characteristics and learns a credit-aware embedding for each region by considering both each region's individual characteristics and cross-region relationships with graph convolutional networks. In the second stage, a hierarchical attention-based credit assessment network is proposed to aggregate the credit indications from a user's multiple trajectories covering diverse regions. The results on real-life user mobility datasets show that CreditPrint can increase the credit investigation accuracy by up to 10% compared to baseline methods.