 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM100: An Orchestrated Dataflow Architecture Powering General AI Computing
Apr 20, 2026As deep learning-based AI technologies gain momentum, the demand for general-purpose AI computing architectures continues to grow. While GPGPU-based architectures offer versatility for diverse AI workloads, they often fall short in efficiency and cost-effectiveness. Various Domain-Specific Architectures (DSAs) excel at particular AI tasks but struggle to extend across broader applications or adapt to the rapidly evolving AI landscape. M100 is Li Auto's response: a performant, cost-effective architecture for AI inference in Autonomous Driving (AD), Large Language Models (LLMs), and intelligent human interactions, domains crucial to today's most competitive automobile platforms. M100 employs a dataflow parallel architecture, where compiler-architecture co-design orchestrates not only computation but, more critically, data movement across time and space. Leveraging dataflow computing efficiency, our hardware-software co-design improves system performance while reducing hardware complexity and cost. M100 largely eliminates caching: tensor computations are driven by compiler- and runtime-managed data streams flowing between computing elements and on/off-chip memories, yielding greater efficiency and scalability than cache-based systems. Another key principle was selecting the right operational granularity for scheduling, issuing, and execution across compiler, firmware, and hardware. Recognizing commonalities in AI workloads, we chose the tensor as the fundamental data element. M100 demonstrates general AI computing capability across diverse inference applications, including UniAD (for AD) and LLaMA (for LLMs). Benchmarks show M100 outperforms GPGPU architectures in AD applications with higher utilization, representing a promising direction for future general AI computing.
Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs
Feb 10, 2026Vision-Language-Action Models (VLAs) have emerged as a key paradigm of Physical AI and are increasingly deployed in autonomous vehicles, robots, and smart spaces. In these resource-constrained on-device settings, selecting an appropriate large language model (LLM) backbone is a critical challenge: models must balance accuracy with strict inference latency and hardware efficiency constraints. This makes hardware-software co-design a game-changing requirement for on-device LLM deployment, where each hardware platform demands a tailored architectural solution. We propose a hardware co-design law that jointly captures model accuracy and inference performance. Specifically, we model training loss as an explicit function of architectural hyperparameters and characterise inference latency via roofline modelling. We empirically evaluate 1,942 candidate architectures on NVIDIA Jetson Orin, training 170 selected models for 10B tokens each to fit a scaling law relating architecture to training loss. By coupling this scaling law with latency modelling, we establish a direct accuracy-latency correspondence and identify the Pareto frontier for hardware co-designed LLMs. We further formulate architecture search as a joint optimisation over precision and performance, deriving feasible design regions under industrial hardware and application budgets. Our approach reduces architecture selection from months to days. At the same latency as Qwen2.5-0.5B on the target hardware, our co-designed architecture achieves 19.42% lower perplexity on WikiText-2. To our knowledge, this is the first principled and operational framework for hardware co-design scaling laws in on-device LLM deployment. We will make the code and related checkpoints publicly available.
MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources
Jan 29, 2026Scaling has powered recent advances in vision foundation models, yet extending this paradigm to metric depth estimation remains challenging due to heterogeneous sensor noise, camera-dependent biases, and metric ambiguity in noisy cross-source 3D data. We introduce Metric Anything, a simple and scalable pretraining framework that learns metric depth from noisy, diverse 3D sources without manually engineered prompts, camera-specific modeling, or task-specific architectures. Central to our approach is the Sparse Metric Prompt, created by randomly masking depth maps, which serves as a universal interface that decouples spatial reasoning from sensor and camera biases. Using about 20M image-depth pairs spanning reconstructed, captured, and rendered 3D data across 10000 camera models, we demonstrate-for the first time-a clear scaling trend in the metric depth track. The pretrained model excels at prompt-driven tasks such as depth completion, super-resolution and Radar-camera fusion, while its distilled prompt-free student achieves state-of-the-art results on monocular depth estimation, camera intrinsics recovery, single/multi-view metric 3D reconstruction, and VLA planning. We also show that using pretrained ViT of Metric Anything as a visual encoder significantly boosts Multimodal Large Language Model capabilities in spatial intelligence. These results show that metric depth estimation can benefit from the same scaling laws that drive modern foundation models, establishing a new path toward scalable and efficient real-world metric perception. We open-source MetricAnything at http://metric-anything.github.io/metric-anything-io/ to support community research.
UniRec: Unified Multimodal Encoding for LLM-Based Recommendations
Jan 27, 2026Large language models have recently shown promise for multimodal recommendation, particularly with text and image inputs. Yet real-world recommendation signals extend far beyond these modalities. To reflect this, we formalize recommendation features into four modalities: text, images, categorical features, and numerical attributes, and highlight the unique challenges this heterogeneity poses for LLMs in understanding multimodal information. In particular, these challenges arise not only across modalities but also within them, as attributes such as price, rating, and time may all be numeric yet carry distinct semantic meanings. Beyond this intra-modality ambiguity, another major challenge is the nested structure of recommendation signals, where user histories are sequences of items, each associated with multiple attributes. To address these challenges, we propose UniRec, a unified multimodal encoder for LLM-based recommendation. UniRec first employs modality-specific encoders to produce consistent embeddings across heterogeneous signals. It then adopts a triplet representation, comprising attribute name, type, and value, to separate schema from raw inputs and preserve semantic distinctions. Finally, a hierarchical Q-Former models the nested structure of user interactions while maintaining their layered organization. Across multiple real-world benchmarks, UniRec outperforms state-of-the-art multimodal and LLM-based recommenders by up to 15%, and extensive ablation studies further validate the contributions of each component.
AFD-SLU: Adaptive Feature Distillation for Spoken Language Understanding
Sep 05, 2025Spoken Language Understanding (SLU) is a core component of conversational systems, enabling machines to interpret user utterances. Despite its importance, developing effective SLU systems remains challenging due to the scarcity of labeled training data and the computational burden of deploying Large Language Models (LLMs) in real-world applications. To further alleviate these issues, we propose an Adaptive Feature Distillation framework that transfers rich semantic representations from a General Text Embeddings (GTE)-based teacher model to a lightweight student model. Our method introduces a dynamic adapter equipped with a Residual Projection Neural Network (RPNN) to align heterogeneous feature spaces, and a Dynamic Distillation Coefficient (DDC) that adaptively modulates the distillation strength based on real-time feedback from intent and slot prediction performance. Experiments on the Chinese profile-based ProSLU benchmark demonstrate that AFD-SLU achieves state-of-the-art results, with 95.67% intent accuracy, 92.02% slot F1 score, and 85.50% overall accuracy.
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
Aug 23, 2025Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen-2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3.
A Scalable Pretraining Framework for Link Prediction with Efficient Adaptation
Aug 06, 2025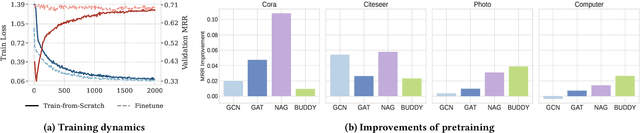

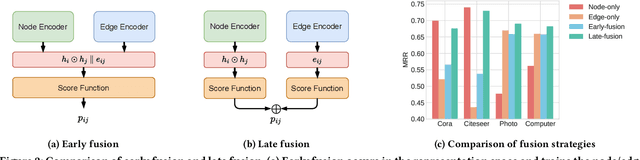

Link Prediction (LP) is a critical task in graph machine learning. While Graph Neural Networks (GNNs) have significantly advanced LP performance recently, existing methods face key challenges including limited supervision from sparse connectivity, sensitivity to initialization, and poor generalization under distribution shifts. We explore pretraining as a solution to address these challenges. Unlike node classification, LP is inherently a pairwise task, which requires the integration of both node- and edge-level information. In this work, we present the first systematic study on the transferability of these distinct modules and propose a late fusion strategy to effectively combine their outputs for improved performance. To handle the diversity of pretraining data and avoid negative transfer, we introduce a Mixture-of-Experts (MoE) framework that captures distinct patterns in separate experts, facilitating seamless application of the pretrained model on diverse downstream datasets. For fast adaptation, we develop a parameter-efficient tuning strategy that allows the pretrained model to adapt to unseen datasets with minimal computational overhead. Experiments on 16 datasets across two domains demonstrate the effectiveness of our approach, achieving state-of-the-art performance on low-resource link prediction while obtaining competitive results compared to end-to-end trained methods, with over 10,000x lower computational overhead.
Higher-order Structure Boosts Link Prediction on Temporal Graphs
May 21, 2025Temporal Graph Neural Networks (TGNNs) have gained growing attention for modeling and predicting structures in temporal graphs. However, existing TGNNs primarily focus on pairwise interactions while overlooking higher-order structures that are integral to link formation and evolution in real-world temporal graphs. Meanwhile, these models often suffer from efficiency bottlenecks, further limiting their expressive power. To tackle these challenges, we propose a Higher-order structure Temporal Graph Neural Network, which incorporates hypergraph representations into temporal graph learning. In particular, we develop an algorithm to identify the underlying higher-order structures, enhancing the model's ability to capture the group interactions. Furthermore, by aggregating multiple edge features into hyperedge representations, HTGN effectively reduces memory cost during training. We theoretically demonstrate the enhanced expressiveness of our approach and validate its effectiveness and efficiency through extensive experiments on various real-world temporal graphs. Experimental results show that HTGN achieves superior performance on dynamic link prediction while reducing memory costs by up to 50\% compared to existing methods.
Discovering Fine-Grained Visual-Concept Relations by Disentangled Optimal Transport Concept Bottleneck Models
May 12, 2025



Concept Bottleneck Models (CBMs) try to make the decision-making process transparent by exploring an intermediate concept space between the input image and the output prediction. Existing CBMs just learn coarse-grained relations between the whole image and the concepts, less considering local image information, leading to two main drawbacks: i) they often produce spurious visual-concept relations, hence decreasing model reliability; and ii) though CBMs could explain the importance of every concept to the final prediction, it is still challenging to tell which visual region produces the prediction. To solve these problems, this paper proposes a Disentangled Optimal Transport CBM (DOT-CBM) framework to explore fine-grained visual-concept relations between local image patches and concepts. Specifically, we model the concept prediction process as a transportation problem between the patches and concepts, thereby achieving explicit fine-grained feature alignment. We also incorporate orthogonal projection losses within the modality to enhance local feature disentanglement. To further address the shortcut issues caused by statistical biases in the data, we utilize the visual saliency map and concept label statistics as transportation priors. Thus, DOT-CBM can visualize inversion heatmaps, provide more reliable concept predictions, and produce more accurate class predictions. Comprehensive experiments demonstrate that our proposed DOT-CBM achieves SOTA performance on several tasks, including image classification, local part detection and out-of-distribution generalization.
HICEScore: A Hierarchical Metric for Image Captioning Evaluation
Jul 26, 2024



Image captioning evaluation metrics can be divided into two categories, reference-based metrics and reference-free metrics. However, reference-based approaches may struggle to evaluate descriptive captions with abundant visual details produced by advanced multimodal large language models, due to their heavy reliance on limited human-annotated references. In contrast, previous reference-free metrics have been proven effective via CLIP cross-modality similarity. Nonetheless, CLIP-based metrics, constrained by their solution of global image-text compatibility, often have a deficiency in detecting local textual hallucinations and are insensitive to small visual objects. Besides, their single-scale designs are unable to provide an interpretable evaluation process such as pinpointing the position of caption mistakes and identifying visual regions that have not been described. To move forward, we propose a novel reference-free metric for image captioning evaluation, dubbed Hierarchical Image Captioning Evaluation Score (HICE-S). By detecting local visual regions and textual phrases, HICE-S builds an interpretable hierarchical scoring mechanism, breaking through the barriers of the single-scale structure of existing reference-free metrics. Comprehensive experiments indicate that our proposed metric achieves the SOTA performance on several benchmarks, outperforming existing reference-free metrics like CLIP-S and PAC-S, and reference-based metrics like METEOR and CIDEr. Moreover, several case studies reveal that the assessment process of HICE-S on detailed captions closely resembles interpretable human judgments.Our code is available at https://github.com/joeyz0z/HICE.