 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable and Effective Alternative to Graph Transformers
Jun 17, 2024



Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.
Cooperative Minibatching in Graph Neural Networks
Oct 22, 2023



Significant computational resources are required to train Graph Neural Networks (GNNs) at a large scale, and the process is highly data-intensive. One of the most effective ways to reduce resource requirements is minibatch training coupled with graph sampling. GNNs have the unique property that items in a minibatch have overlapping data. However, the commonly implemented Independent Minibatching approach assigns each Processing Element (PE) its own minibatch to process, leading to duplicated computations and input data access across PEs. This amplifies the Neighborhood Explosion Phenomenon (NEP), which is the main bottleneck limiting scaling. To reduce the effects of NEP in the multi-PE setting, we propose a new approach called Cooperative Minibatching. Our approach capitalizes on the fact that the size of the sampled subgraph is a concave function of the batch size, leading to significant reductions in the amount of work per seed vertex as batch sizes increase. Hence, it is favorable for processors equipped with a fast interconnect to work on a large minibatch together as a single larger processor, instead of working on separate smaller minibatches, even though global batch size is identical. We also show how to take advantage of the same phenomenon in serial execution by generating dependent consecutive minibatches. Our experimental evaluations show up to 4x bandwidth savings for fetching vertex embeddings, by simply increasing this dependency without harming model convergence. Combining our proposed approaches, we achieve up to 64% speedup over Independent Minibatching on single-node multi-GPU systems.
(LA)yer-neigh(BOR) Sampling: Defusing Neighborhood Explosion in GNNs
Oct 24, 2022Graph Neural Networks have recently received a significant attention, however, training them at a large scale still remains a challenge. Minibatch training coupled with sampling is used to alleviate this challenge. Even so existing approaches either suffer from the neighborhood explosion phenomenon or do not have good performance. To deal with these issues, we propose a new sampling algorithm called LAyer-neighBOR sampling (LABOR). It is designed to be a direct replacement for Neighborhood Sampling with the same fanout hyperparameter while sampling much fewer vertices, without sacrificing quality. By design, the variance of the estimator of each vertex matches Neighbor Sampling from the point of view of a single vertex. In our experiments, we demonstrate the superiority of our approach when it comes to model convergence behaviour against Neighbor Sampling and also the other Layer Sampling approaches under the same limited vertex sampling budget constraints.
More Recent Advances in (Hyper)Graph Partitioning
May 28, 2022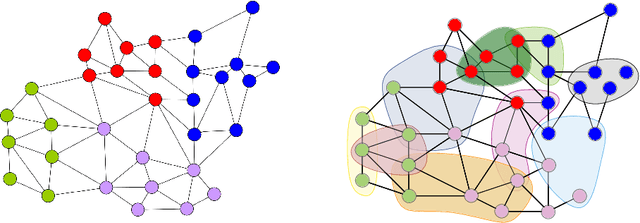

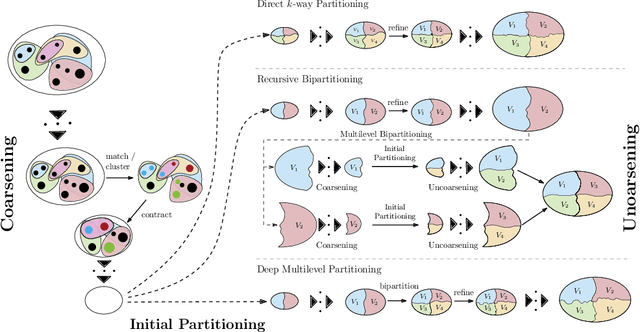

In recent years, significant advances have been made in the design and evaluation of balanced (hyper)graph partitioning algorithms. We survey trends of the last decade in practical algorithms for balanced (hyper)graph partitioning together with future research directions. Our work serves as an update to a previous survey on the topic. In particular, the survey extends the previous survey by also covering hypergraph partitioning and streaming algorithms, and has an additional focus on parallel algorithms.
MG-GCN: Scalable Multi-GPU GCN Training Framework
Oct 17, 2021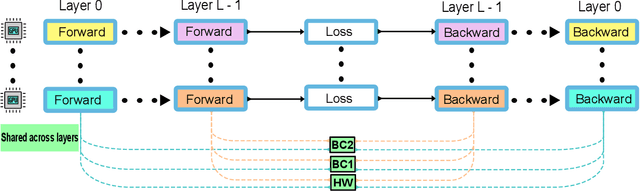
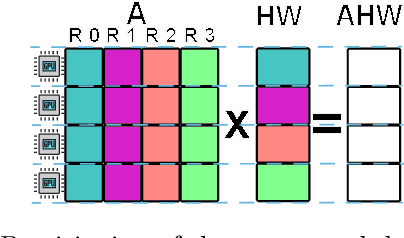
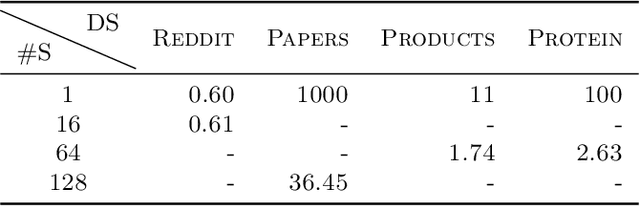
Full batch training of Graph Convolutional Network (GCN) models is not feasible on a single GPU for large graphs containing tens of millions of vertices or more. Recent work has shown that, for the graphs used in the machine learning community, communication becomes a bottleneck and scaling is blocked outside of the single machine regime. Thus, we propose MG-GCN, a multi-GPU GCN training framework taking advantage of the high-speed communication links between the GPUs present in multi-GPU systems. MG-GCN employs multiple High-Performance Computing optimizations, including efficient re-use of memory buffers to reduce the memory footprint of training GNN models, as well as communication and computation overlap. These optimizations enable execution on larger datasets, that generally do not fit into memory of a single GPU in state-of-the-art implementations. Furthermore, they contribute to achieve superior speedup compared to the state-of-the-art. For example, MG-GCN achieves super-linear speedup with respect to DGL, on the Reddit graph on both DGX-1 (V100) and DGX-A100.