 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluStRE: Streaming Graph Clustering with Multi-Stage Refinement
Feb 08, 2025We present CluStRE, a novel streaming graph clustering algorithm that balances computational efficiency with high-quality clustering using multi-stage refinement. Unlike traditional in-memory clustering approaches, CluStRE processes graphs in a streaming setting, significantly reducing memory overhead while leveraging re-streaming and evolutionary heuristics to improve solution quality. Our method dynamically constructs a quotient graph, enabling modularity-based optimization while efficiently handling large-scale graphs. We introduce multiple configurations of CluStRE to provide trade-offs between speed, memory consumption, and clustering quality. Experimental evaluations demonstrate that CluStRE improves solution quality by 89.8%, operates 2.6 times faster, and uses less than two-thirds of the memory required by the state-of-the-art streaming clustering algorithm on average. Moreover, our strongest mode enhances solution quality by up to 150% on average. With this, CluStRE achieves comparable solution quality to in-memory algorithms, i.e. over 96% of the quality of clustering approaches, including Louvain, effectively bridging the gap between streaming and traditional clustering methods.
Improved Exact and Heuristic Algorithms for Maximum Weight Clique
Feb 01, 2023We propose improved exact and heuristic algorithms for solving the maximum weight clique problem, a well-known problem in graph theory with many applications. Our algorithms interleave successful techniques from related work with novel data reduction rules that use local graph structure to identify and remove vertices and edges while retaining the optimal solution. We evaluate our algorithms on a range of synthetic and real-world graphs, and find that they outperform the current state of the art on most inputs. Our data reductions always produce smaller reduced graphs than existing data reductions alone. As a result, our exact algorithm, MWCRedu, finds solutions orders of magnitude faster on naturally weighted, medium-sized map labeling graphs and random hyperbolic graphs. Our heuristic algorithm, MWCPeel, outperforms its competitors on these instances, but is slightly less effective on extremely dense or large instances.
Attention-based Multiple Instance Learning for Survival Prediction on Lung Cancer Tissue Microarrays
Dec 15, 2022

Attention-based multiple instance learning (AMIL) algorithms have proven to be successful in utilizing gigapixel whole-slide images (WSIs) for a variety of different computational pathology tasks such as outcome prediction and cancer subtyping problems. We extended an AMIL approach to the task of survival prediction by utilizing the classical Cox partial likelihood as a loss function, converting the AMIL model into a nonlinear proportional hazards model. We applied the model to tissue microarray (TMA) slides of 330 lung cancer patients. The results show that AMIL approaches can handle very small amounts of tissue from a TMA and reach similar C-index performance compared to established survival prediction methods trained with highly discriminative clinical factors such as age, cancer grade, and cancer stage
More Recent Advances in (Hyper)Graph Partitioning
May 28, 2022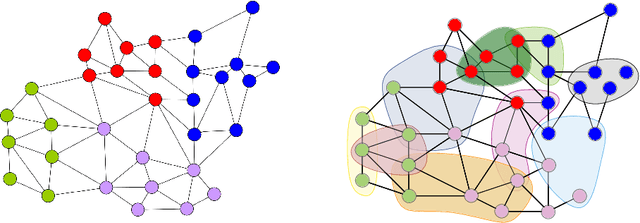

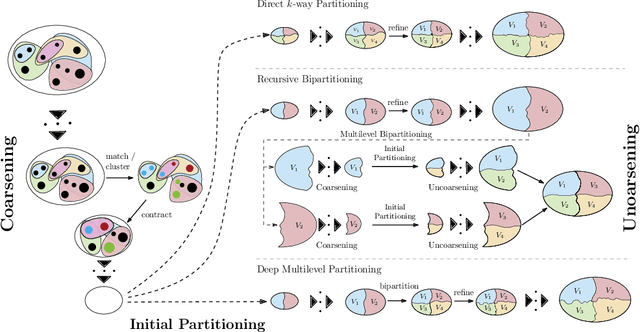

In recent years, significant advances have been made in the design and evaluation of balanced (hyper)graph partitioning algorithms. We survey trends of the last decade in practical algorithms for balanced (hyper)graph partitioning together with future research directions. Our work serves as an update to a previous survey on the topic. In particular, the survey extends the previous survey by also covering hypergraph partitioning and streaming algorithms, and has an additional focus on parallel algorithms.
Local Motif Clustering via (Hyper)Graph Partitioning
May 11, 2022



A widely-used operation on graphs is local clustering, i.e., extracting a well-characterized community around a seed node without the need to process the whole graph. Recently local motif clustering has been proposed: it looks for a local cluster based on the distribution of motifs. Since this local clustering perspective is relatively new, most approaches proposed for it are extensions of statistical and numerical methods previously used for edge-based local clustering, while the available combinatorial approaches are still few and relatively simple. In this work, we build a hypergraph and a graph model which both represent the motif-distribution around the seed node. We solve these models using sophisticated combinatorial algorithms designed for (hyper)graph partitioning. In extensive experiments with the triangle motif, we observe that our algorithm computes communities with a motif conductance value being one third on average in comparison against the communities computed by the state-of-the-art tool MAPPR while being 6.3 times faster on average.
Weakly Supervised Semantic Segmentation of Remote Sensing Images for Tree Species Classification Based on Explanation Methods
Jan 19, 2022

The collection of a high number of pixel-based labeled training samples for tree species identification is time consuming and costly in operational forestry applications. To address this problem, in this paper we investigate the effectiveness of explanation methods for deep neural networks in performing weakly supervised semantic segmentation using only image-level labels. Specifically, we consider four methods:i) class activation maps (CAM); ii) gradient-based CAM; iii) pixel correlation module; and iv) self-enhancing maps (SEM). We compare these methods with each other using both quantitative and qualitative measures of their segmentation accuracy, as well as their computational requirements. Experimental results obtained on an aerial image archive show that:i) considered explanation techniques are highly relevant for the identification of tree species with weak supervision; and ii) the SEM outperforms the other considered methods. The code for this paper is publicly available at https://git.tu-berlin.de/rsim/rs_wsss.
Boosting Data Reduction for the Maximum Weight Independent Set Problem Using Increasing Transformations
Aug 13, 2020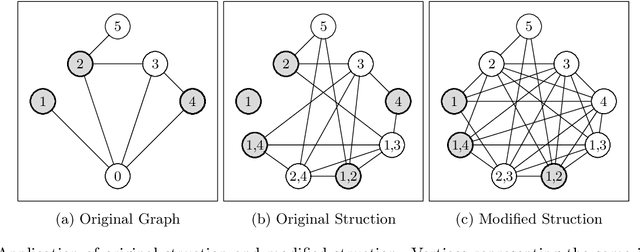
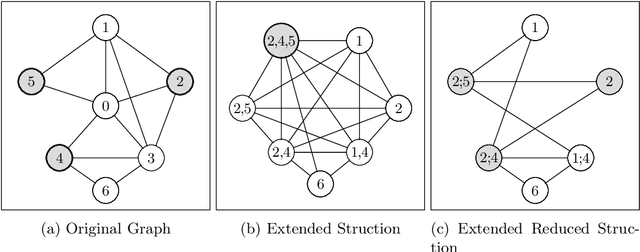
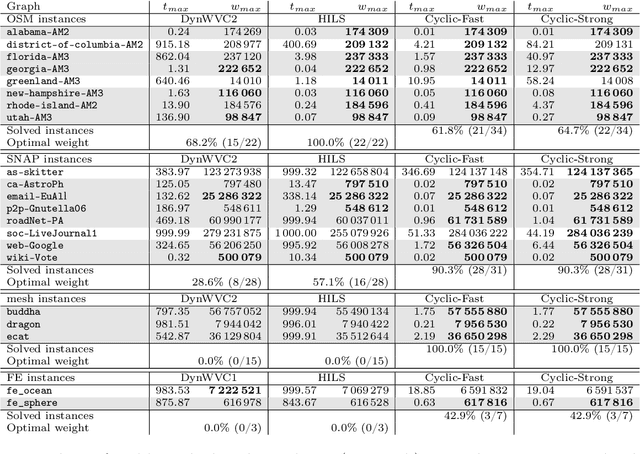
Given a vertex-weighted graph, the maximum weight independent set problem asks for a pair-wise non-adjacent set of vertices such that the sum of their weights is maximum. The branch-and-reduce paradigm is the de facto standard approach to solve the problem to optimality in practice. In this paradigm, data reduction rules are applied to decrease the problem size. These data reduction rules ensure that given an optimum solution on the new (smaller) input, one can quickly construct an optimum solution on the original input. We introduce new generalized data reduction and transformation rules for the problem. A key feature of our work is that some transformation rules can increase the size of the input. Surprisingly, these so-called increasing transformations can simplify the problem and also open up the reduction space to yield even smaller irreducible graphs later throughout the algorithm. In experiments, our algorithm computes significantly smaller irreducible graphs on all except one instance, solves more instances to optimality than previously possible, is up to two orders of magnitude faster than the best state-of-the-art solver, and finds higher-quality solutions than heuristic solvers DynWVC and HILS on many instances. While the increasing transformations are only efficient enough for preprocessing at this time, we see this as a critical initial step towards a new branch-and-transform paradigm.
Multilevel Acyclic Hypergraph Partitioning
Feb 06, 2020



A directed acyclic hypergraph is a generalized concept of a directed acyclic graph, where each hyperedge can contain an arbitrary number of tails and heads. Directed hypergraphs can be used to model data flow and execution dependencies in streaming applications. Thus, hypergraph partitioning algorithms can be used to obtain efficient parallelizations for multiprocessor architectures. However, an acyclicity constraint on the partition is necessary when mapping streaming applications to embedded multiprocessors due to resource restrictions on this type of hardware. The acyclic hypergraph partitioning problem is to partition the hypernodes of a directed acyclic hypergraph into a given number of blocks of roughly equal size such that the corresponding quotient graph is acyclic while minimizing an objective function on the partition. Here, we contribute the first n-level algorithm for the acyclic hypergraph partitioning problem. Our focus is on acyclic hypergraphs where hyperedges can have one head and arbitrary many tails. Based on this, we engineer a memetic algorithm to further reduce communication cost, as well as to improve scheduling makespan on embedded multiprocessor architectures. Experiments indicate that our algorithm outperforms previous algorithms that focus on the directed acyclic graph case which have previously been employed in the application domain. Moreover, our experiments indicate that using the directed hypergraph model for this type of application yields a significantly smaller makespan.
Scalable Graph Algorithms
Nov 30, 2019



Processing large complex networks recently attracted considerable interest. Complex graphs are useful in a wide range of applications from technological networks to biological systems like the human brain. Sometimes these networks are composed of billions of entities that give rise to emerging properties and structures. Analyzing these structures aids us in gaining new insights about our surroundings. As huge networks become abundant, there is a need for scalable algorithms to perform analysis. A prominent example is the PageRank algorithm, which is one of the measures used by web search engines such as Google to rank web pages displayed to the user. In order to find these patterns, massive amounts of data have to be acquired and processed. Designing and evaluating scalable graph algorithms to handle these data sets is a crucial task on the road to understanding the underlying systems. This habilitation thesis is a summary a broad spectrum of scalable graph algorithms that I developed over the last six years with many coauthors. In general, this research is based on four pillars: multilevel algorithms, practical kernelization, parallelization and memetic algorithms that are highly interconnected. Experiments conducted indicate that our algorithms find better solutions and/or are much more scalable than the previous state-of-the-art.
Faster Support Vector Machines
Oct 10, 2018



The time complexity of support vector machines (SVMs) prohibits training on huge data sets with millions of samples. Recently, multilevel approaches to train SVMs have been developed to allow for time efficient training on huge data sets. While regular SVMs perform the entire training in one - time consuming - optimization step, multilevel SVMs first build a hierarchy of problems decreasing in size that resemble the original problem and then train an SVM model for each hierarchy level benefiting from the solved models of previous levels. We present a faster multilevel support vector machine that uses a label propagation algorithm to construct the problem hierarchy. Extensive experiments show that our new algorithm achieves speed-ups up to two orders of magnitude while having similar or better classification quality over state-of-the-art algorithms.