 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Data Reduction for the Maximum Weight Independent Set Problem Using Increasing Transformations
Aug 13, 2020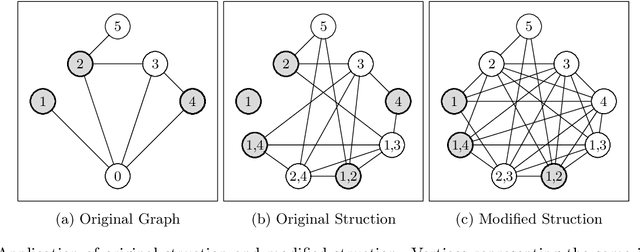
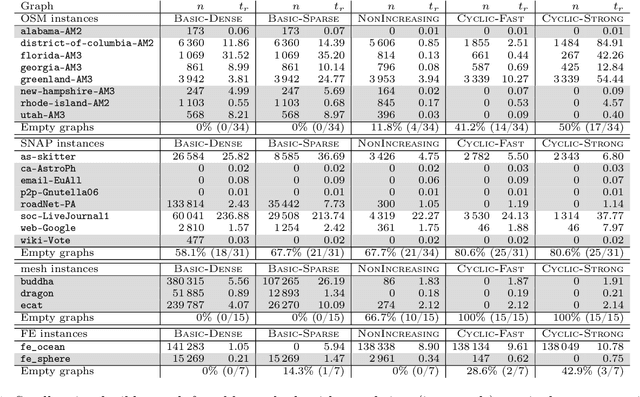
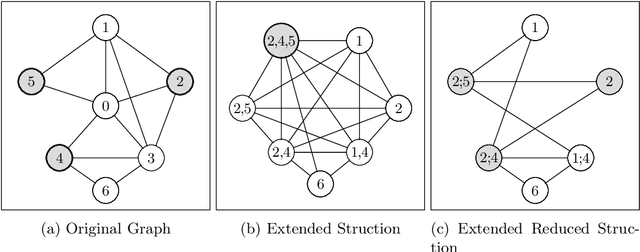
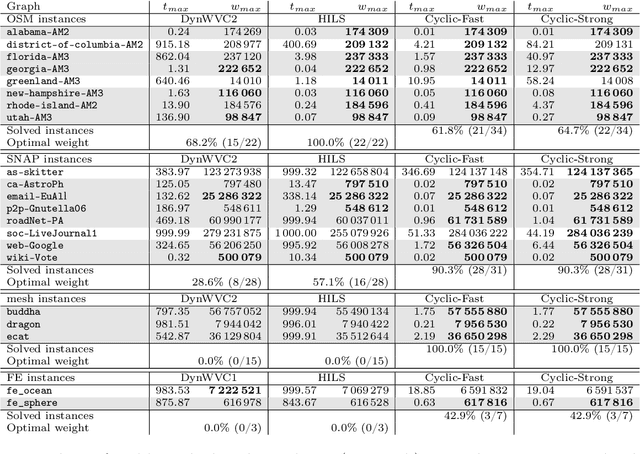
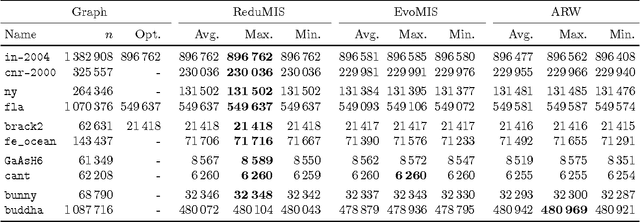
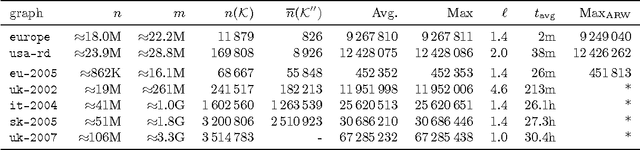
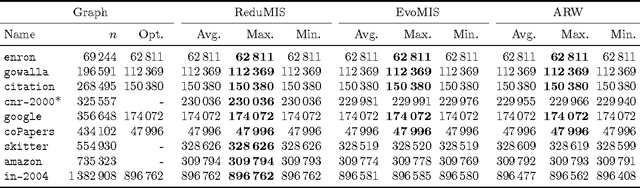
Given a vertex-weighted graph, the maximum weight independent set problem asks for a pair-wise non-adjacent set of vertices such that the sum of their weights is maximum. The branch-and-reduce paradigm is the de facto standard approach to solve the problem to optimality in practice. In this paradigm, data reduction rules are applied to decrease the problem size. These data reduction rules ensure that given an optimum solution on the new (smaller) input, one can quickly construct an optimum solution on the original input. We introduce new generalized data reduction and transformation rules for the problem. A key feature of our work is that some transformation rules can increase the size of the input. Surprisingly, these so-called increasing transformations can simplify the problem and also open up the reduction space to yield even smaller irreducible graphs later throughout the algorithm. In experiments, our algorithm computes significantly smaller irreducible graphs on all except one instance, solves more instances to optimality than previously possible, is up to two orders of magnitude faster than the best state-of-the-art solver, and finds higher-quality solutions than heuristic solvers DynWVC and HILS on many instances. While the increasing transformations are only efficient enough for preprocessing at this time, we see this as a critical initial step towards a new branch-and-transform paradigm.
Finding Near-Optimal Independent Sets at Scale
Sep 02, 2015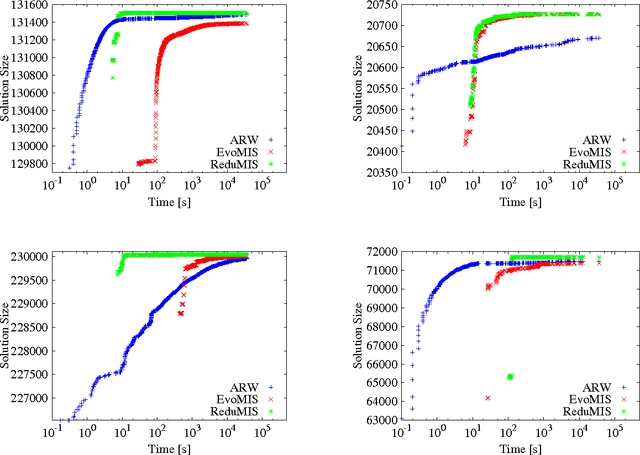
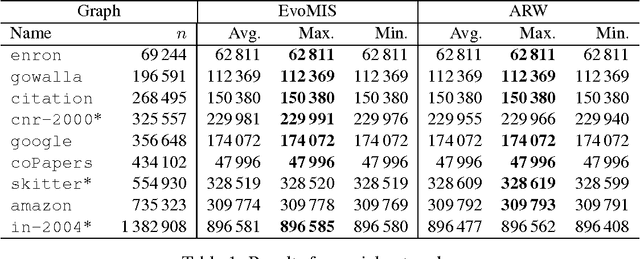
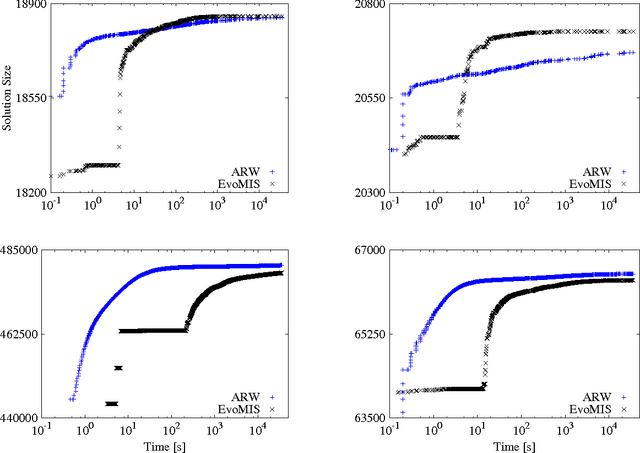
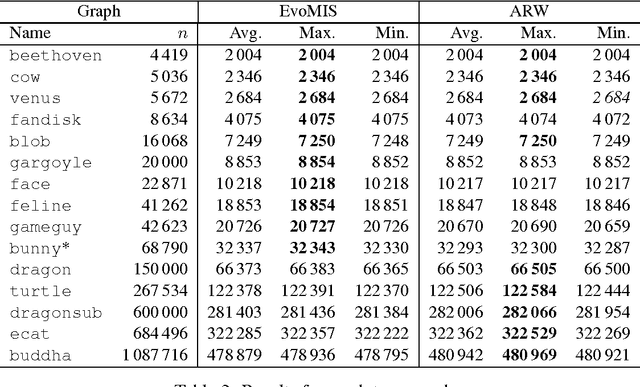
The independent set problem is NP-hard and particularly difficult to solve in large sparse graphs. In this work, we develop an advanced evolutionary algorithm, which incorporates kernelization techniques to compute large independent sets in huge sparse networks. A recent exact algorithm has shown that large networks can be solved exactly by employing a branch-and-reduce technique that recursively kernelizes the graph and performs branching. However, one major drawback of their algorithm is that, for huge graphs, branching still can take exponential time. To avoid this problem, we recursively choose vertices that are likely to be in a large independent set (using an evolutionary approach), then further kernelize the graph. We show that identifying and removing vertices likely to be in large independent sets opens up the reduction space---which not only speeds up the computation of large independent sets drastically, but also enables us to compute high-quality independent sets on much larger instances than previously reported in the literature.
Graph Partitioning for Independent Sets
Feb 05, 2015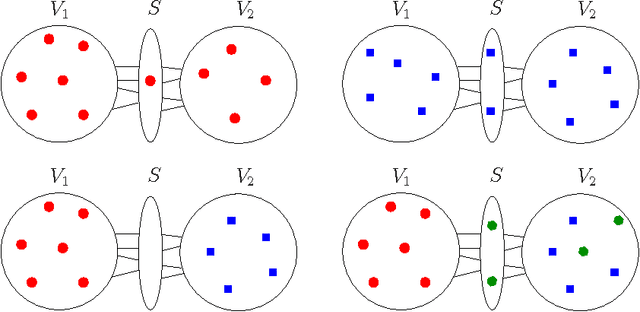
Computing maximum independent sets in graphs is an important problem in computer science. In this paper, we develop an evolutionary algorithm to tackle the problem. The core innovations of the algorithm are very natural combine operations based on graph partitioning and local search algorithms. More precisely, we employ a state-of-the-art graph partitioner to derive operations that enable us to quickly exchange whole blocks of given independent sets. To enhance newly computed offsprings we combine our operators with a local search algorithm. Our experimental evaluation indicates that we are able to outperform state-of-the-art algorithms on a variety of instances.