 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Recent Advances in (Hyper)Graph Partitioning
May 28, 2022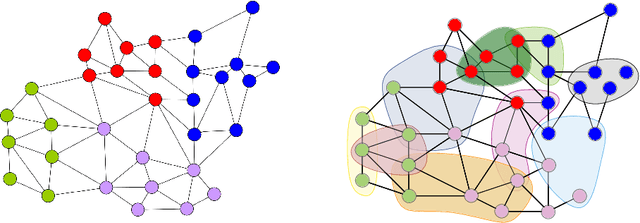

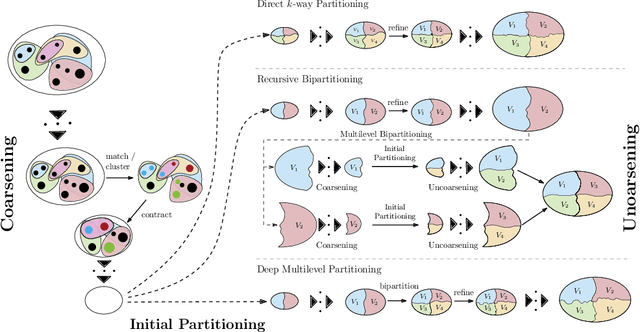

In recent years, significant advances have been made in the design and evaluation of balanced (hyper)graph partitioning algorithms. We survey trends of the last decade in practical algorithms for balanced (hyper)graph partitioning together with future research directions. Our work serves as an update to a previous survey on the topic. In particular, the survey extends the previous survey by also covering hypergraph partitioning and streaming algorithms, and has an additional focus on parallel algorithms.
Multilevel Acyclic Hypergraph Partitioning
Feb 06, 2020



A directed acyclic hypergraph is a generalized concept of a directed acyclic graph, where each hyperedge can contain an arbitrary number of tails and heads. Directed hypergraphs can be used to model data flow and execution dependencies in streaming applications. Thus, hypergraph partitioning algorithms can be used to obtain efficient parallelizations for multiprocessor architectures. However, an acyclicity constraint on the partition is necessary when mapping streaming applications to embedded multiprocessors due to resource restrictions on this type of hardware. The acyclic hypergraph partitioning problem is to partition the hypernodes of a directed acyclic hypergraph into a given number of blocks of roughly equal size such that the corresponding quotient graph is acyclic while minimizing an objective function on the partition. Here, we contribute the first n-level algorithm for the acyclic hypergraph partitioning problem. Our focus is on acyclic hypergraphs where hyperedges can have one head and arbitrary many tails. Based on this, we engineer a memetic algorithm to further reduce communication cost, as well as to improve scheduling makespan on embedded multiprocessor architectures. Experiments indicate that our algorithm outperforms previous algorithms that focus on the directed acyclic graph case which have previously been employed in the application domain. Moreover, our experiments indicate that using the directed hypergraph model for this type of application yields a significantly smaller makespan.
Faster Support Vector Machines
Oct 10, 2018



The time complexity of support vector machines (SVMs) prohibits training on huge data sets with millions of samples. Recently, multilevel approaches to train SVMs have been developed to allow for time efficient training on huge data sets. While regular SVMs perform the entire training in one - time consuming - optimization step, multilevel SVMs first build a hierarchy of problems decreasing in size that resemble the original problem and then train an SVM model for each hierarchy level benefiting from the solved models of previous levels. We present a faster multilevel support vector machine that uses a label propagation algorithm to construct the problem hierarchy. Extensive experiments show that our new algorithm achieves speed-ups up to two orders of magnitude while having similar or better classification quality over state-of-the-art algorithms.