 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Decoding for Hallucination-Resistant Multimodal Large Language Models
Feb 24, 2026Multimodal Large Language Models (MLLMs) deliver detailed responses on vision-language tasks, yet remain susceptible to object hallucination (introducing objects not present in the image), undermining reliability in practice. Prior efforts often rely on heuristic penalties, post-hoc correction, or generic decoding tweaks, which do not directly intervene in the mechanisms that trigger object hallucination and thus yield limited gains. To address this challenge, we propose a causal decoding framework that applies targeted causal interventions during generation to curb spurious object mentions. By reshaping the decoding dynamics to attenuate spurious dependencies, our approach reduces false object tokens while maintaining descriptive quality. Across captioning and QA benchmarks, our framework substantially lowers object-hallucination rates and achieves state-of-the-art faithfulness without degrading overall output quality.
UniRec: Unified Multimodal Encoding for LLM-Based Recommendations
Jan 27, 2026Large language models have recently shown promise for multimodal recommendation, particularly with text and image inputs. Yet real-world recommendation signals extend far beyond these modalities. To reflect this, we formalize recommendation features into four modalities: text, images, categorical features, and numerical attributes, and highlight the unique challenges this heterogeneity poses for LLMs in understanding multimodal information. In particular, these challenges arise not only across modalities but also within them, as attributes such as price, rating, and time may all be numeric yet carry distinct semantic meanings. Beyond this intra-modality ambiguity, another major challenge is the nested structure of recommendation signals, where user histories are sequences of items, each associated with multiple attributes. To address these challenges, we propose UniRec, a unified multimodal encoder for LLM-based recommendation. UniRec first employs modality-specific encoders to produce consistent embeddings across heterogeneous signals. It then adopts a triplet representation, comprising attribute name, type, and value, to separate schema from raw inputs and preserve semantic distinctions. Finally, a hierarchical Q-Former models the nested structure of user interactions while maintaining their layered organization. Across multiple real-world benchmarks, UniRec outperforms state-of-the-art multimodal and LLM-based recommenders by up to 15%, and extensive ablation studies further validate the contributions of each component.
A Scalable Pretraining Framework for Link Prediction with Efficient Adaptation
Aug 06, 2025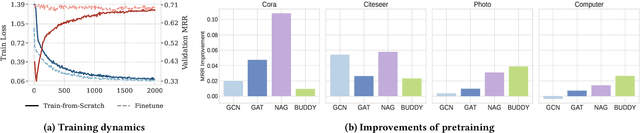

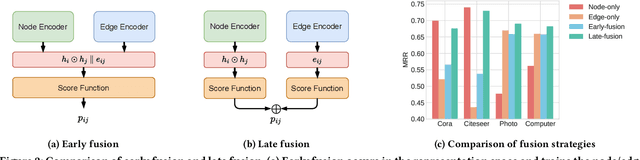

Link Prediction (LP) is a critical task in graph machine learning. While Graph Neural Networks (GNNs) have significantly advanced LP performance recently, existing methods face key challenges including limited supervision from sparse connectivity, sensitivity to initialization, and poor generalization under distribution shifts. We explore pretraining as a solution to address these challenges. Unlike node classification, LP is inherently a pairwise task, which requires the integration of both node- and edge-level information. In this work, we present the first systematic study on the transferability of these distinct modules and propose a late fusion strategy to effectively combine their outputs for improved performance. To handle the diversity of pretraining data and avoid negative transfer, we introduce a Mixture-of-Experts (MoE) framework that captures distinct patterns in separate experts, facilitating seamless application of the pretrained model on diverse downstream datasets. For fast adaptation, we develop a parameter-efficient tuning strategy that allows the pretrained model to adapt to unseen datasets with minimal computational overhead. Experiments on 16 datasets across two domains demonstrate the effectiveness of our approach, achieving state-of-the-art performance on low-resource link prediction while obtaining competitive results compared to end-to-end trained methods, with over 10,000x lower computational overhead.
Higher-order Structure Boosts Link Prediction on Temporal Graphs
May 21, 2025Temporal Graph Neural Networks (TGNNs) have gained growing attention for modeling and predicting structures in temporal graphs. However, existing TGNNs primarily focus on pairwise interactions while overlooking higher-order structures that are integral to link formation and evolution in real-world temporal graphs. Meanwhile, these models often suffer from efficiency bottlenecks, further limiting their expressive power. To tackle these challenges, we propose a Higher-order structure Temporal Graph Neural Network, which incorporates hypergraph representations into temporal graph learning. In particular, we develop an algorithm to identify the underlying higher-order structures, enhancing the model's ability to capture the group interactions. Furthermore, by aggregating multiple edge features into hyperedge representations, HTGN effectively reduces memory cost during training. We theoretically demonstrate the enhanced expressiveness of our approach and validate its effectiveness and efficiency through extensive experiments on various real-world temporal graphs. Experimental results show that HTGN achieves superior performance on dynamic link prediction while reducing memory costs by up to 50\% compared to existing methods.
Unified Semantic and ID Representation Learning for Deep Recommenders
Feb 23, 2025



Effective recommendation is crucial for large-scale online platforms. Traditional recommendation systems primarily rely on ID tokens to uniquely identify items, which can effectively capture specific item relationships but suffer from issues such as redundancy and poor performance in cold-start scenarios. Recent approaches have explored using semantic tokens as an alternative, yet they face challenges, including item duplication and inconsistent performance gains, leaving the potential advantages of semantic tokens inadequately examined. To address these limitations, we propose a Unified Semantic and ID Representation Learning framework that leverages the complementary strengths of both token types. In our framework, ID tokens capture unique item attributes, while semantic tokens represent shared, transferable characteristics. Additionally, we analyze the role of cosine similarity and Euclidean distance in embedding search, revealing that cosine similarity is more effective in decoupling accumulated embeddings, while Euclidean distance excels in distinguishing unique items. Our framework integrates cosine similarity in earlier layers and Euclidean distance in the final layer to optimize representation learning. Experiments on three benchmark datasets show that our method significantly outperforms state-of-the-art baselines, with improvements ranging from 6\% to 17\% and a reduction in token size by over 80%. These results demonstrate the effectiveness of combining ID and semantic tokenization to enhance the generalization ability of recommender systems.
RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
Feb 17, 2025Retrieval-Augmented Generation (RAG) enhances the performance of LLMs across various tasks by retrieving relevant information from external sources, particularly on text-based data. For structured data, such as knowledge graphs, GraphRAG has been widely used to retrieve relevant information. However, recent studies have revealed that structuring implicit knowledge from text into graphs can benefit certain tasks, extending the application of GraphRAG from graph data to general text-based data. Despite their successful extensions, most applications of GraphRAG for text data have been designed for specific tasks and datasets, lacking a systematic evaluation and comparison between RAG and GraphRAG on widely used text-based benchmarks. In this paper, we systematically evaluate RAG and GraphRAG on well-established benchmark tasks, such as Question Answering and Query-based Summarization. Our results highlight the distinct strengths of RAG and GraphRAG across different tasks and evaluation perspectives. Inspired by these observations, we investigate strategies to integrate their strengths to improve downstream tasks. Additionally, we provide an in-depth discussion of the shortcomings of current GraphRAG approaches and outline directions for future research.
Session-Level Dynamic Ad Load Optimization using Offline Robust Reinforcement Learning
Jan 09, 2025



Session-level dynamic ad load optimization aims to personalize the density and types of delivered advertisements in real time during a user's online session by dynamically balancing user experience quality and ad monetization. Traditional causal learning-based approaches struggle with key technical challenges, especially in handling confounding bias and distribution shifts. In this paper, we develop an offline deep Q-network (DQN)-based framework that effectively mitigates confounding bias in dynamic systems and demonstrates more than 80% offline gains compared to the best causal learning-based production baseline. Moreover, to improve the framework's robustness against unanticipated distribution shifts, we further enhance our framework with a novel offline robust dueling DQN approach. This approach achieves more stable rewards on multiple OpenAI-Gym datasets as perturbations increase, and provides an additional 5% offline gains on real-world ad delivery data. Deployed across multiple production systems, our approach has achieved outsized topline gains. Post-launch online A/B tests have shown double-digit improvements in the engagement-ad score trade-off efficiency, significantly enhancing our platform's capability to serve both consumers and advertisers.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
Learning Graph Quantized Tokenizers for Transformers
Oct 17, 2024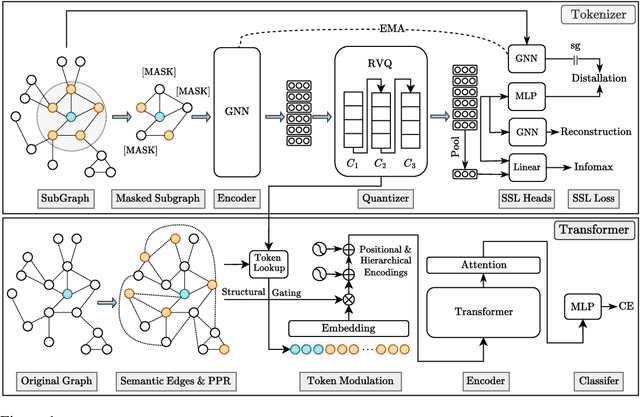
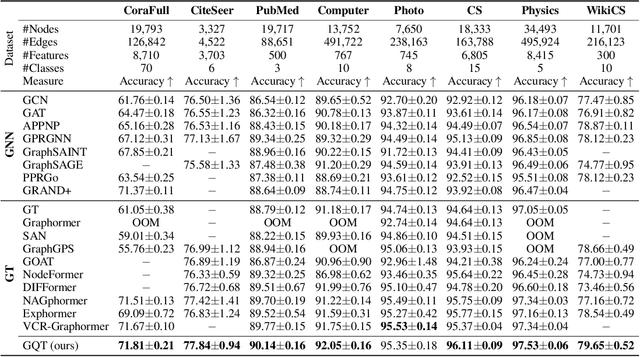
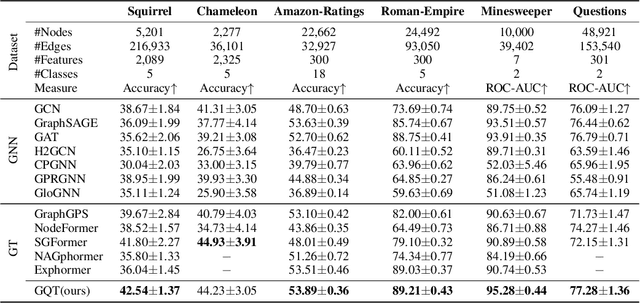
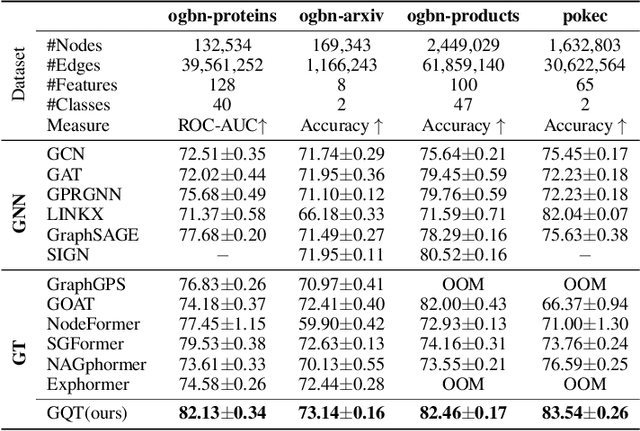
Transformers serve as the backbone architectures of Foundational Models, where a domain-specific tokenizer helps them adapt to various domains. Graph Transformers (GTs) have recently emerged as a leading model in geometric deep learning, outperforming Graph Neural Networks (GNNs) in various graph learning tasks. However, the development of tokenizers for graphs has lagged behind other modalities, with existing approaches relying on heuristics or GNNs co-trained with Transformers. To address this, we introduce GQT (\textbf{G}raph \textbf{Q}uantized \textbf{T}okenizer), which decouples tokenizer training from Transformer training by leveraging multi-task graph self-supervised learning, yielding robust and generalizable graph tokens. Furthermore, the GQT utilizes Residual Vector Quantization (RVQ) to learn hierarchical discrete tokens, resulting in significantly reduced memory requirements and improved generalization capabilities. By combining the GQT with token modulation, a Transformer encoder achieves state-of-the-art performance on 16 out of 18 benchmarks, including large-scale homophilic and heterophilic datasets. The code is available at: https://github.com/limei0307/graph-tokenizer
A Scalable and Effective Alternative to Graph Transformers
Jun 17, 2024



Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.