 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems
Apr 14, 2026Large language models (LLMs) have transformed AI research thanks to their powerful internal capabilities and knowledge. However, existing LLMs still fail to effectively incorporate the massive external knowledge when interacting with the world. Although retrieval-augmented LLMs are proposed to mitigate the issue, they are still fundamentally constrained by the context length of LLMs, as they can only retrieve top-K raw data chunks from the external knowledge base which often consists of millions of data chunks. Here we propose Thought-Retriever, a novel model-agnostic algorithm that helps LLMs generate output conditioned on arbitrarily long external data, without being constrained by the context length or number of retrieved data chunks. Our key insight is to let an LLM fully leverage its intermediate responses generated when solving past user queries (thoughts), filtering meaningless and redundant thoughts, organizing them in thought memory, and retrieving the relevant thoughts when addressing new queries. This effectively equips LLM-based agents with a self-evolving long-term memory that grows more capable through continuous interaction. Besides algorithmic innovation, we further meticulously prepare a novel benchmark, AcademicEval, which requires an LLM to faithfully leverage ultra-long context to answer queries based on real-world academic papers. Extensive experiments on AcademicEval and two other public datasets validate that Thought-Retriever remarkably outperforms state-of-the-art baselines, achieving an average increase of at least 7.6% in F1 score and 16% in win rate across various tasks. More importantly, we further demonstrate two exciting findings: (1) Thought-Retriever can indeed help LLM self-evolve after solving more user queries; (2) Thought-Retriever learns to leverage deeper thoughts to answer more abstract user queries.
UniRec: Unified Multimodal Encoding for LLM-Based Recommendations
Jan 27, 2026Large language models have recently shown promise for multimodal recommendation, particularly with text and image inputs. Yet real-world recommendation signals extend far beyond these modalities. To reflect this, we formalize recommendation features into four modalities: text, images, categorical features, and numerical attributes, and highlight the unique challenges this heterogeneity poses for LLMs in understanding multimodal information. In particular, these challenges arise not only across modalities but also within them, as attributes such as price, rating, and time may all be numeric yet carry distinct semantic meanings. Beyond this intra-modality ambiguity, another major challenge is the nested structure of recommendation signals, where user histories are sequences of items, each associated with multiple attributes. To address these challenges, we propose UniRec, a unified multimodal encoder for LLM-based recommendation. UniRec first employs modality-specific encoders to produce consistent embeddings across heterogeneous signals. It then adopts a triplet representation, comprising attribute name, type, and value, to separate schema from raw inputs and preserve semantic distinctions. Finally, a hierarchical Q-Former models the nested structure of user interactions while maintaining their layered organization. Across multiple real-world benchmarks, UniRec outperforms state-of-the-art multimodal and LLM-based recommenders by up to 15%, and extensive ablation studies further validate the contributions of each component.
Unified Semantic and ID Representation Learning for Deep Recommenders
Feb 23, 2025



Effective recommendation is crucial for large-scale online platforms. Traditional recommendation systems primarily rely on ID tokens to uniquely identify items, which can effectively capture specific item relationships but suffer from issues such as redundancy and poor performance in cold-start scenarios. Recent approaches have explored using semantic tokens as an alternative, yet they face challenges, including item duplication and inconsistent performance gains, leaving the potential advantages of semantic tokens inadequately examined. To address these limitations, we propose a Unified Semantic and ID Representation Learning framework that leverages the complementary strengths of both token types. In our framework, ID tokens capture unique item attributes, while semantic tokens represent shared, transferable characteristics. Additionally, we analyze the role of cosine similarity and Euclidean distance in embedding search, revealing that cosine similarity is more effective in decoupling accumulated embeddings, while Euclidean distance excels in distinguishing unique items. Our framework integrates cosine similarity in earlier layers and Euclidean distance in the final layer to optimize representation learning. Experiments on three benchmark datasets show that our method significantly outperforms state-of-the-art baselines, with improvements ranging from 6\% to 17\% and a reduction in token size by over 80%. These results demonstrate the effectiveness of combining ID and semantic tokenization to enhance the generalization ability of recommender systems.
Paper Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance
Sep 06, 2024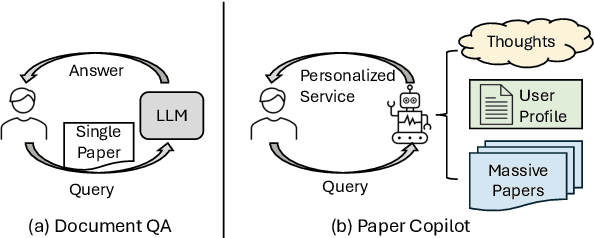
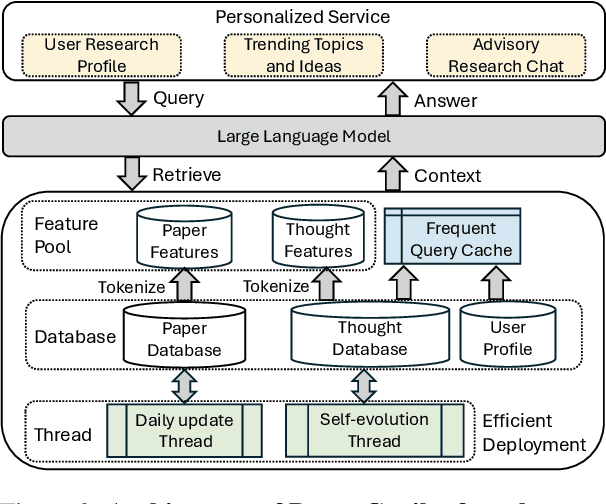
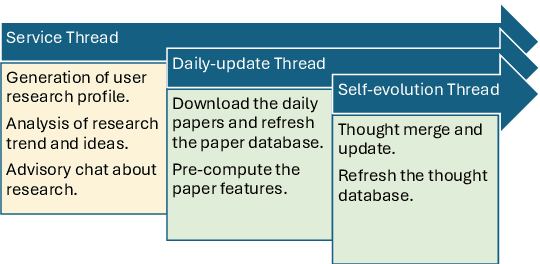
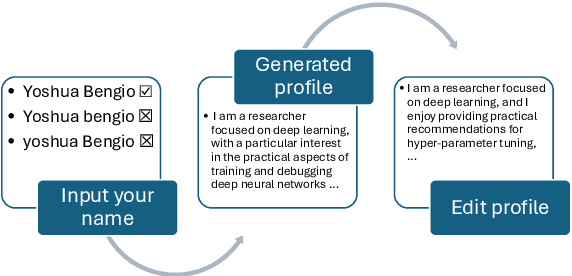
As scientific research proliferates, researchers face the daunting task of navigating and reading vast amounts of literature. Existing solutions, such as document QA, fail to provide personalized and up-to-date information efficiently. We present Paper Copilot, a self-evolving, efficient LLM system designed to assist researchers, based on thought-retrieval, user profile and high performance optimization. Specifically, Paper Copilot can offer personalized research services, maintaining a real-time updated database. Quantitative evaluation demonstrates that Paper Copilot saves 69.92\% of time after efficient deployment. This paper details the design and implementation of Paper Copilot, highlighting its contributions to personalized academic support and its potential to streamline the research process.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
How Far Are We From AGI
May 16, 2024



The evolution of artificial intelligence (AI) has profoundly impacted human society, driving significant advancements in multiple sectors. Yet, the escalating demands on AI have highlighted the limitations of AI's current offerings, catalyzing a movement towards Artificial General Intelligence (AGI). AGI, distinguished by its ability to execute diverse real-world tasks with efficiency and effectiveness comparable to human intelligence, reflects a paramount milestone in AI evolution. While existing works have summarized specific recent advancements of AI, they lack a comprehensive discussion of AGI's definitions, goals, and developmental trajectories. Different from existing survey papers, this paper delves into the pivotal questions of our proximity to AGI and the strategies necessary for its realization through extensive surveys, discussions, and original perspectives. We start by articulating the requisite capability frameworks for AGI, integrating the internal, interface, and system dimensions. As the realization of AGI requires more advanced capabilities and adherence to stringent constraints, we further discuss necessary AGI alignment technologies to harmonize these factors. Notably, we emphasize the importance of approaching AGI responsibly by first defining the key levels of AGI progression, followed by the evaluation framework that situates the status-quo, and finally giving our roadmap of how to reach the pinnacle of AGI. Moreover, to give tangible insights into the ubiquitous impact of the integration of AI, we outline existing challenges and potential pathways toward AGI in multiple domains. In sum, serving as a pioneering exploration into the current state and future trajectory of AGI, this paper aims to foster a collective comprehension and catalyze broader public discussions among researchers and practitioners on AGI.
Inverse Learning with Extremely Sparse Feedback for Recommendation
Nov 20, 2023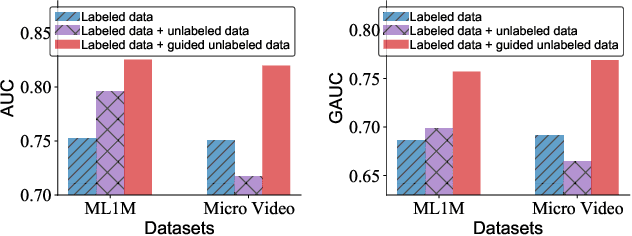
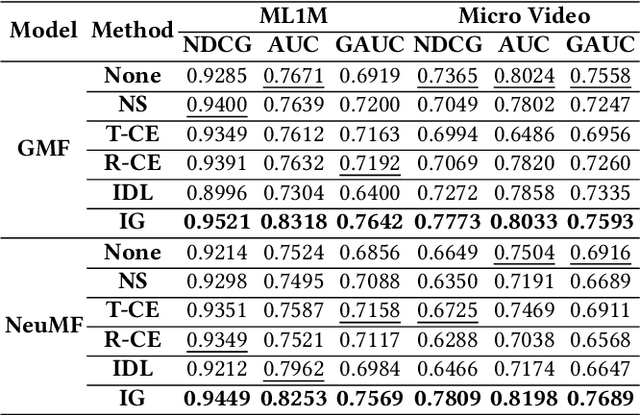
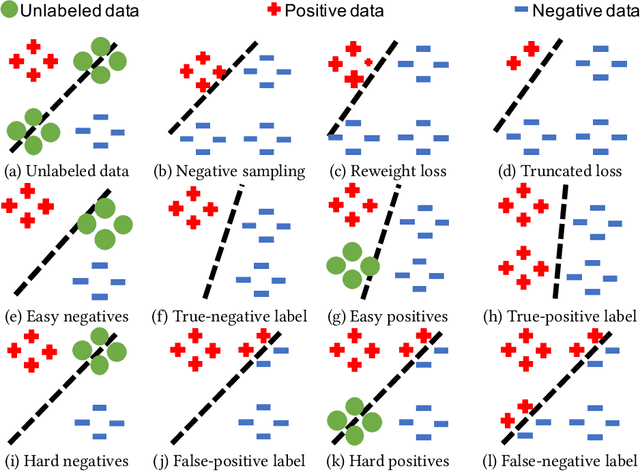

Modern personalized recommendation services often rely on user feedback, either explicit or implicit, to improve the quality of services. Explicit feedback refers to behaviors like ratings, while implicit feedback refers to behaviors like user clicks. However, in the scenario of full-screen video viewing experiences like Tiktok and Reels, the click action is absent, resulting in unclear feedback from users, hence introducing noises in modeling training. Existing approaches on de-noising recommendation mainly focus on positive instances while ignoring the noise in a large amount of sampled negative feedback. In this paper, we propose a meta-learning method to annotate the unlabeled data from loss and gradient perspectives, which considers the noises in both positive and negative instances. Specifically, we first propose an Inverse Dual Loss (IDL) to boost the true label learning and prevent the false label learning. Then we further propose an Inverse Gradient (IG) method to explore the correct updating gradient and adjust the updating based on meta-learning. Finally, we conduct extensive experiments on both benchmark and industrial datasets where our proposed method can significantly improve AUC by 9.25% against state-of-the-art methods. Further analysis verifies the proposed inverse learning framework is model-agnostic and can improve a variety of recommendation backbones. The source code, along with the best hyper-parameter settings, is available at this link: https://github.com/Guanyu-Lin/InverseLearning.
Mixed Attention Network for Cross-domain Sequential Recommendation
Nov 14, 2023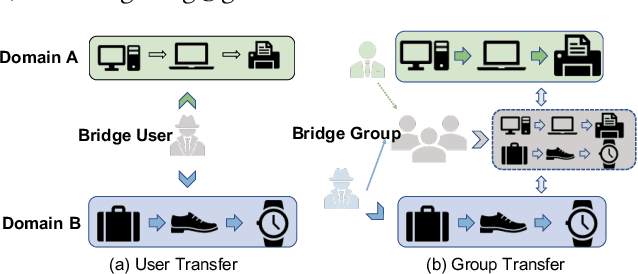
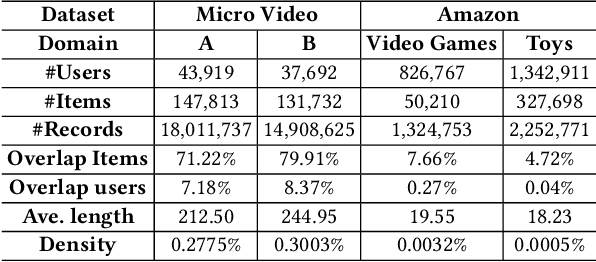
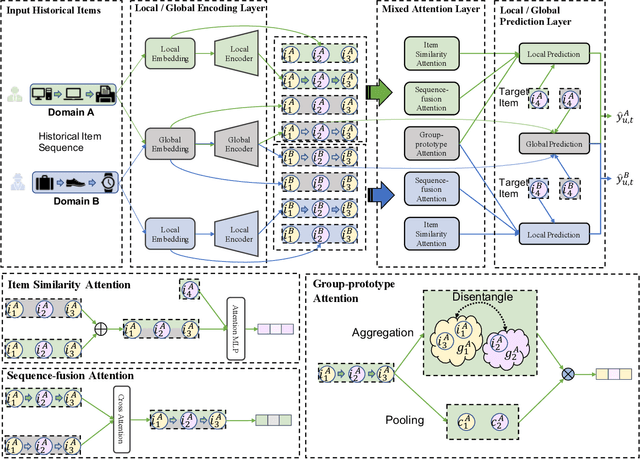
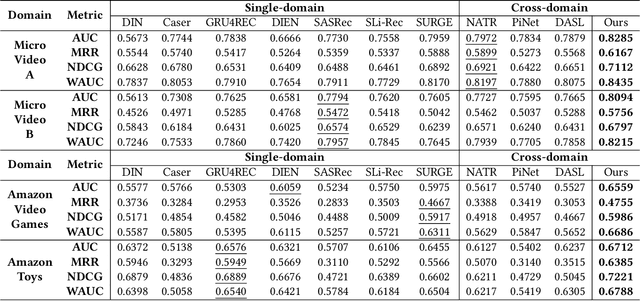
In modern recommender systems, sequential recommendation leverages chronological user behaviors to make effective next-item suggestions, which suffers from data sparsity issues, especially for new users. One promising line of work is the cross-domain recommendation, which trains models with data across multiple domains to improve the performance in data-scarce domains. Recent proposed cross-domain sequential recommendation models such as PiNet and DASL have a common drawback relying heavily on overlapped users in different domains, which limits their usage in practical recommender systems. In this paper, we propose a Mixed Attention Network (MAN) with local and global attention modules to extract the domain-specific and cross-domain information. Firstly, we propose a local/global encoding layer to capture the domain-specific/cross-domain sequential pattern. Then we propose a mixed attention layer with item similarity attention, sequence-fusion attention, and group-prototype attention to capture the local/global item similarity, fuse the local/global item sequence, and extract the user groups across different domains, respectively. Finally, we propose a local/global prediction layer to further evolve and combine the domain-specific and cross-domain interests. Experimental results on two real-world datasets (each with two domains) demonstrate the superiority of our proposed model. Further study also illustrates that our proposed method and components are model-agnostic and effective, respectively. The code and data are available at https://github.com/Guanyu-Lin/MAN.
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Jun 24, 2023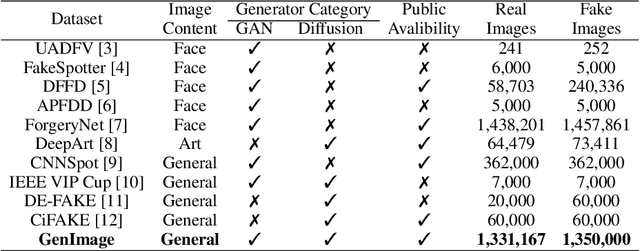

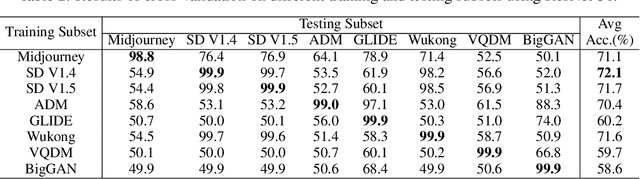
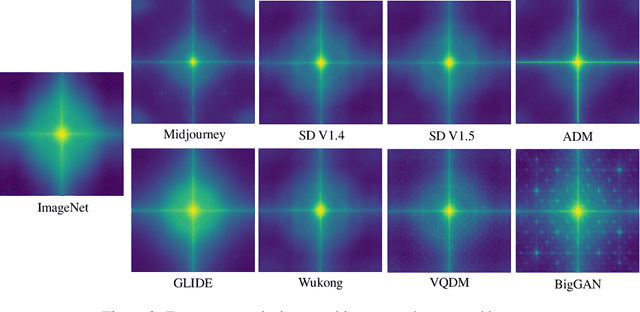
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can effectively expedite the development and evaluation of superior AI-generated image detectors in comparison to prevailing methodologies.
Dual-interest Factorization-heads Attention for Sequential Recommendation
Feb 10, 2023



Accurate user interest modeling is vital for recommendation scenarios. One of the effective solutions is the sequential recommendation that relies on click behaviors, but this is not elegant in the video feed recommendation where users are passive in receiving the streaming contents and return skip or no-skip behaviors. Here skip and no-skip behaviors can be treated as negative and positive feedback, respectively. With the mixture of positive and negative feedback, it is challenging to capture the transition pattern of behavioral sequence. To do so, FeedRec has exploited a shared vanilla Transformer, which may be inelegant because head interaction of multi-heads attention does not consider different types of feedback. In this paper, we propose Dual-interest Factorization-heads Attention for Sequential Recommendation (short for DFAR) consisting of feedback-aware encoding layer, dual-interest disentangling layer and prediction layer. In the feedback-aware encoding layer, we first suppose each head of multi-heads attention can capture specific feedback relations. Then we further propose factorization-heads attention which can mask specific head interaction and inject feedback information so as to factorize the relation between different types of feedback. Additionally, we propose a dual-interest disentangling layer to decouple positive and negative interests before performing disentanglement on their representations. Finally, we evolve the positive and negative interests by corresponding towers whose outputs are contrastive by BPR loss. Experiments on two real-world datasets show the superiority of our proposed method against state-of-the-art baselines. Further ablation study and visualization also sustain its effectiveness. We release the source code here: https://github.com/tsinghua-fib-lab/WWW2023-DFAR.