 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSPO: Direct Semantic Preference Optimization for Real-World Image Super-Resolution
Apr 21, 2025



Recent advances in diffusion models have improved Real-World Image Super-Resolution (Real-ISR), but existing methods lack human feedback integration, risking misalignment with human preference and may leading to artifacts, hallucinations and harmful content generation. To this end, we are the first to introduce human preference alignment into Real-ISR, a technique that has been successfully applied in Large Language Models and Text-to-Image tasks to effectively enhance the alignment of generated outputs with human preferences. Specifically, we introduce Direct Preference Optimization (DPO) into Real-ISR to achieve alignment, where DPO serves as a general alignment technique that directly learns from the human preference dataset. Nevertheless, unlike high-level tasks, the pixel-level reconstruction objectives of Real-ISR are difficult to reconcile with the image-level preferences of DPO, which can lead to the DPO being overly sensitive to local anomalies, leading to reduced generation quality. To resolve this dichotomy, we propose Direct Semantic Preference Optimization (DSPO) to align instance-level human preferences by incorporating semantic guidance, which is through two strategies: (a) semantic instance alignment strategy, implementing instance-level alignment to ensure fine-grained perceptual consistency, and (b) user description feedback strategy, mitigating hallucinations through semantic textual feedback on instance-level images. As a plug-and-play solution, DSPO proves highly effective in both one-step and multi-step SR frameworks.
Multi-Granularity Semantic Revision for Large Language Model Distillation
Jul 14, 2024



Knowledge distillation plays a key role in compressing the Large Language Models (LLMs), which boosts a small-size student model under large teacher models' guidance. However, existing LLM distillation methods overly rely on student-generated outputs, which may introduce generation errors and misguide the distillation process. Moreover, the distillation loss functions introduced in previous art struggle to align the most informative part due to the complex distribution of LLMs' outputs. To address these problems, we propose a multi-granularity semantic revision method for LLM distillation. At the sequence level, we propose a sequence correction and re-generation (SCRG) strategy. SCRG first calculates the semantic cognitive difference between the teacher and student to detect the error token, then corrects it with the teacher-generated one, and re-generates the sequence to reduce generation errors and enhance generation diversity. At the token level, we design a distribution adaptive clipping Kullback-Leibler (DAC-KL) loss as the distillation objective function. DAC-KL loss exploits a learnable sub-network to adaptively extract semantically dense areas from the teacher's output, avoiding the interference of redundant information in the distillation process. Finally, at the span level, we leverage the span priors of a sequence to compute the probability correlations within spans, and constrain the teacher and student's probability correlations to be consistent, further enhancing the transfer of semantic information. Extensive experiments across different model families with parameters ranging from 0.1B to 13B demonstrate the superiority of our method compared to existing methods.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024
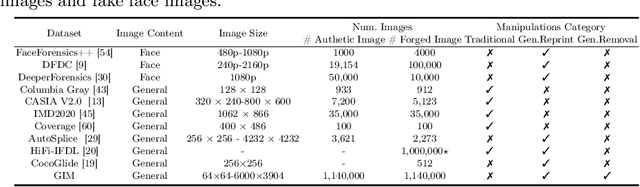
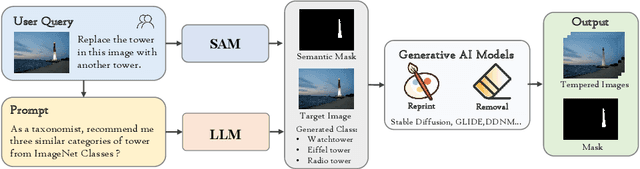
The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.
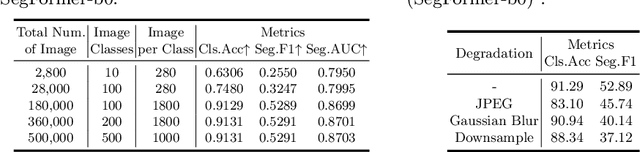
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Jun 24, 2023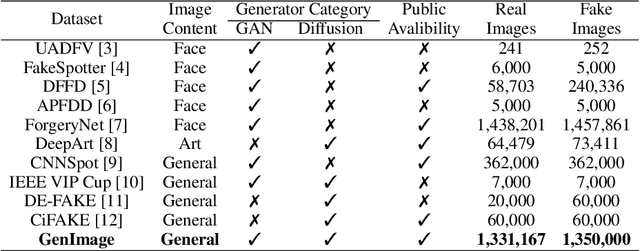

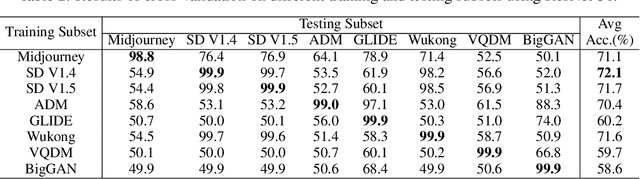
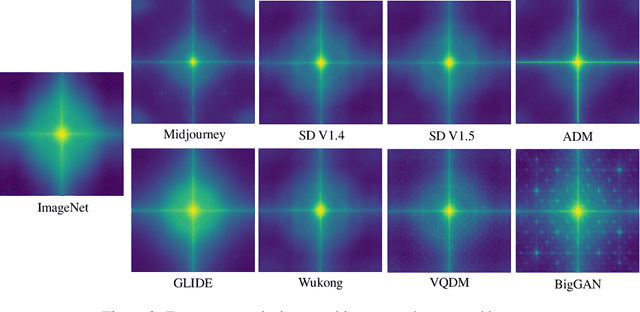
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can effectively expedite the development and evaluation of superior AI-generated image detectors in comparison to prevailing methodologies.
FPPN: Future Pseudo-LiDAR Frame Prediction for Autonomous Driving
Dec 08, 2021
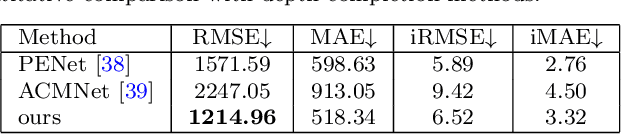


LiDAR sensors are widely used in autonomous driving due to the reliable 3D spatial information. However, the data of LiDAR is sparse and the frequency of LiDAR is lower than that of cameras. To generate denser point clouds spatially and temporally, we propose the first future pseudo-LiDAR frame prediction network. Given the consecutive sparse depth maps and RGB images, we first predict a future dense depth map based on dynamic motion information coarsely. To eliminate the errors of optical flow estimation, an inter-frame aggregation module is proposed to fuse the warped depth maps with adaptive weights. Then, we refine the predicted dense depth map using static contextual information. The future pseudo-LiDAR frame can be obtained by converting the predicted dense depth map into corresponding 3D point clouds. Experimental results show that our method outperforms the existing solutions on the popular KITTI benchmark.