 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Prototyping and Hierarchical Alignment for Unsupervised Video-based Visible-Infrared Person Re-Identification
Apr 23, 2026Visible-infrared person re-identification (VI-ReID) enables cross-modality identity matching for all-day surveillance, yet existing methods predominantly focus on the image level or rely heavily on costly identity annotations. While video-based VI-ReID has recently emerged to exploit temporal dynamics for improved robustness, existing studies remain limited to supervised settings. Crucially, the unsupervised video VI-ReID problem, where models must learn from RGB and infrared tracklets without identity labels, remains largely unexplored despite its practical importance in real-world deployment. To bridge this gap, we propose HiTPro (Hierarchical Temporal Prototyping), a prototype-driven framework without explicit hard pseudo-label assignment for unsupervised video-based VI-ReID. HiTPro begins with an efficient Temporal-aware Feature Encoder that first extracts discriminative frame-level features and then aggregates them into a robust tracklet-level representation. Building upon these features, HiTPro first constructs reliable intra-camera prototypes via Intra-Camera Tracklet Prototyping by aggregating features from temporally partitioned sub-tracklets. Through Hierarchical Cross-Prototype Alignment, we perform a two-stage positive mining process: progressing from within-modality associations to cross-modality matching, enhanced by Dynamic Threshold Strategy and Soft Weight Assignment. Finally, {Hierarchical Contrastive Learning} progressively optimizes feature-prototype alignment across three levels: intra-camera discrimination, cross-camera same-modality consistency, and cross-modality invariance. Extensive experiments on HITSZ-VCM and BUPTCampus demonstrate that HiTPro achieves state-of-the-art performance under fully unsupervised settings, significantly outperforming adapted baselines and establishes a strong baseline for future research.
InterDyad: Interactive Dyadic Speech-to-Video Generation by Querying Intermediate Visual Guidance
Mar 24, 2026Despite progress in speech-to-video synthesis, existing methods often struggle to capture cross-individual dependencies and provide fine-grained control over reactive behaviors in dyadic settings. To address these challenges, we propose InterDyad, a framework that enables naturalistic interactive dynamics synthesis via querying structural motion guidance. Specifically, we first design an Interactivity Injector that achieves video reenactment based on identity-agnostic motion priors extracted from reference videos. Building upon this, we introduce a MetaQuery-based modality alignment mechanism to bridge the gap between conversational audio and these motion priors. By leveraging a Multimodal Large Language Model (MLLM), our framework is able to distill linguistic intent from audio to dictate the precise timing and appropriateness of reactions. To further improve lip-sync quality under extreme head poses, we propose Role-aware Dyadic Gaussian Guidance (RoDG) for enhanced lip-synchronization and spatial consistency. Finally, we introduce a dedicated evaluation suite with novelly designed metrics to quantify dyadic interaction. Comprehensive experiments demonstrate that InterDyad significantly outperforms state-of-the-art methods in producing natural and contextually grounded two-person interactions. Please refer to our project page for demo videos: https://interdyad.github.io/.
Dependency Network-Based Portfolio Design with Forecasting and VaR Constraints
Jul 26, 2025

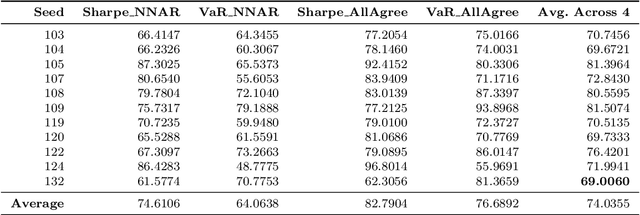

This study proposes a novel portfolio optimization framework that integrates statistical social network analysis with time series forecasting and risk management. Using daily stock data from the S&P 500 (2020-2024), we construct dependency networks via Vector Autoregression (VAR) and Forecast Error Variance Decomposition (FEVD), transforming influence relationships into a cost-based network. Specifically, FEVD breaks down the VAR's forecast error variance to quantify how much each stock's shocks contribute to another's uncertainty information we invert to form influence-based edge weights in our network. By applying the Minimum Spanning Tree (MST) algorithm, we extract the core inter-stock structure and identify central stocks through degree centrality. A dynamic portfolio is constructed using the top-ranked stocks, with capital allocated based on Value at Risk (VaR). To refine stock selection, we incorporate forecasts from ARIMA and Neural Network Autoregressive (NNAR) models. Trading simulations over a one-year period demonstrate that the MST-based strategies outperform a buy-and-hold benchmark, with the tuned NNAR-enhanced strategy achieving a 63.74% return versus 18.00% for the benchmark. Our results highlight the potential of combining network structures, predictive modeling, and risk metrics to improve adaptive financial decision-making.
Galerkin-ARIMA: A Two-Stage Polynomial Regression Framework for Fast Rolling One-Step-Ahead Forecasting
Jul 10, 2025Time-series models like ARIMA remain widely used for forecasting but limited to linear assumptions and high computational cost in large and complex datasets. We propose Galerkin-ARIMA that generalizes the AR component of ARIMA and replace it with a flexible spline-based function estimated by Galerkin projection. This enables the model to capture nonlinear dependencies in lagged values and retain the MA component and Gaussian noise assumption. We derive a closed-form OLS estimator for the Galerkin coefficients and show the model is asymptotically unbiased and consistent under standard conditions. Our method bridges classical time-series modeling and nonparametric regression, which offering improved forecasting performance and computational efficiency.
Agent-as-a-Service based on Agent Network
May 13, 2025The rise of large model-based AI agents has spurred interest in Multi-Agent Systems (MAS) for their capabilities in decision-making, collaboration, and adaptability. While the Model Context Protocol (MCP) addresses tool invocation and data exchange challenges via a unified protocol, it lacks support for organizing agent-level collaboration. To bridge this gap, we propose Agent-as-a-Service based on Agent Network (AaaS-AN), a service-oriented paradigm grounded in the Role-Goal-Process-Service (RGPS) standard. AaaS-AN unifies the entire agent lifecycle, including construction, integration, interoperability, and networked collaboration, through two core components: (1) a dynamic Agent Network, which models agents and agent groups as vertexes that self-organize within the network based on task and role dependencies; (2) service-oriented agents, incorporating service discovery, registration, and interoperability protocols. These are orchestrated by a Service Scheduler, which leverages an Execution Graph to enable distributed coordination, context tracking, and runtime task management. We validate AaaS-AN on mathematical reasoning and application-level code generation tasks, which outperforms state-of-the-art baselines. Notably, we constructed a MAS based on AaaS-AN containing agent groups, Robotic Process Automation (RPA) workflows, and MCP servers over 100 agent services. We also release a dataset containing 10,000 long-horizon multi-agent workflows to facilitate future research on long-chain collaboration in MAS.
Impact of Static Friction on Sim2Real in Robotic Reinforcement Learning
Mar 03, 2025



In robotic reinforcement learning, the Sim2Real gap remains a critical challenge. However, the impact of Static friction on Sim2Real has been underexplored. Conventional domain randomization methods typically exclude Static friction from their parameter space. In our robotic reinforcement learning task, such conventional domain randomization approaches resulted in significantly underperforming real-world models. To address this Sim2Real challenge, we employed Actuator Net as an alternative to conventional domain randomization. While this method enabled successful transfer to flat-ground locomotion, it failed on complex terrains like stairs. To further investigate physical parameters affecting Sim2Real in robotic joints, we developed a control-theoretic joint model and performed systematic parameter identification. Our analysis revealed unexpectedly high friction-torque ratios in our robotic joints. To mitigate its impact, we implemented Static friction-aware domain randomization for Sim2Real. Recognizing the increased training difficulty introduced by friction modeling, we proposed a simple and novel solution to reduce learning complexity. To validate this approach, we conducted comprehensive Sim2Sim and Sim2Real experiments comparing three methods: conventional domain randomization (without Static friction), Actuator Net, and our Static friction-aware domain randomization. All experiments utilized the Rapid Motor Adaptation (RMA) algorithm. Results demonstrated that our method achieved superior adaptive capabilities and overall performance.
Towards Homogeneous Modality Learning and Multi-Granularity Information Exploration for Visible-Infrared Person Re-Identification
Apr 11, 2022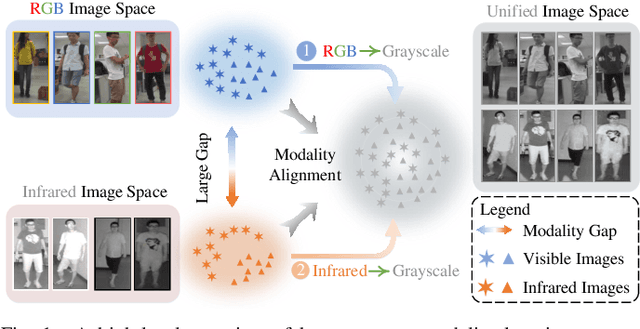

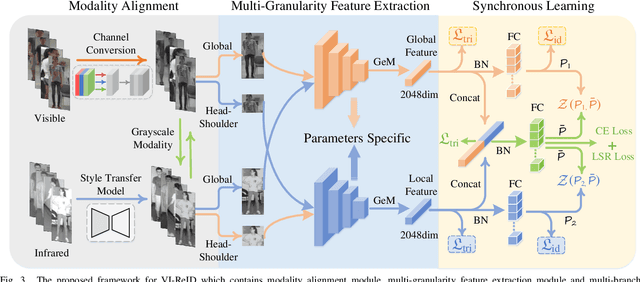

Visible-infrared person re-identification (VI-ReID) is a challenging and essential task, which aims to retrieve a set of person images over visible and infrared camera views. In order to mitigate the impact of large modality discrepancy existing in heterogeneous images, previous methods attempt to apply generative adversarial network (GAN) to generate the modality-consisitent data. However, due to severe color variations between the visible domain and infrared domain, the generated fake cross-modality samples often fail to possess good qualities to fill the modality gap between synthesized scenarios and target real ones, which leads to sub-optimal feature representations. In this work, we address cross-modality matching problem with Aligned Grayscale Modality (AGM), an unified dark-line spectrum that reformulates visible-infrared dual-mode learning as a gray-gray single-mode learning problem. Specifically, we generate the grasycale modality from the homogeneous visible images. Then, we train a style tranfer model to transfer infrared images into homogeneous grayscale images. In this way, the modality discrepancy is significantly reduced in the image space. In order to reduce the remaining appearance discrepancy, we further introduce a multi-granularity feature extraction network to conduct feature-level alignment. Rather than relying on the global information, we propose to exploit local (head-shoulder) features to assist person Re-ID, which complements each other to form a stronger feature descriptor. Comprehensive experiments implemented on the mainstream evaluation datasets include SYSU-MM01 and RegDB indicate that our method can significantly boost cross-modality retrieval performance against the state of the art methods.
FPPN: Future Pseudo-LiDAR Frame Prediction for Autonomous Driving
Dec 08, 2021
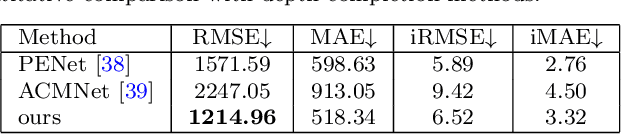


LiDAR sensors are widely used in autonomous driving due to the reliable 3D spatial information. However, the data of LiDAR is sparse and the frequency of LiDAR is lower than that of cameras. To generate denser point clouds spatially and temporally, we propose the first future pseudo-LiDAR frame prediction network. Given the consecutive sparse depth maps and RGB images, we first predict a future dense depth map based on dynamic motion information coarsely. To eliminate the errors of optical flow estimation, an inter-frame aggregation module is proposed to fuse the warped depth maps with adaptive weights. Then, we refine the predicted dense depth map using static contextual information. The future pseudo-LiDAR frame can be obtained by converting the predicted dense depth map into corresponding 3D point clouds. Experimental results show that our method outperforms the existing solutions on the popular KITTI benchmark.
End-to-end Neural Video Coding Using a Compound Spatiotemporal Representation
Aug 05, 2021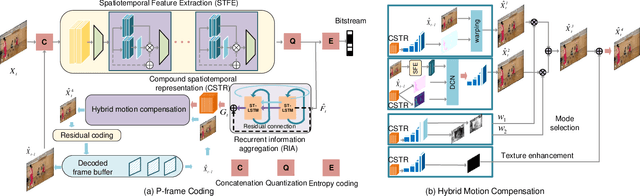
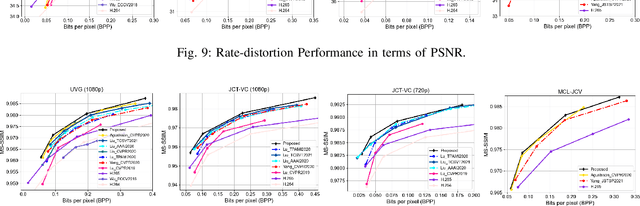
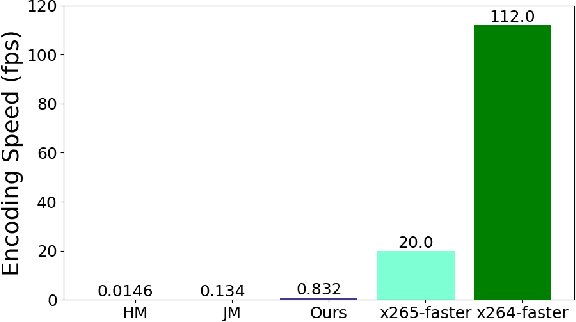
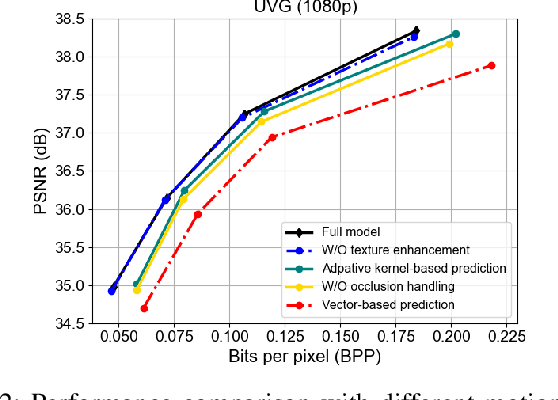
Recent years have witnessed rapid advances in learnt video coding. Most algorithms have solely relied on the vector-based motion representation and resampling (e.g., optical flow based bilinear sampling) for exploiting the inter frame redundancy. In spite of the great success of adaptive kernel-based resampling (e.g., adaptive convolutions and deformable convolutions) in video prediction for uncompressed videos, integrating such approaches with rate-distortion optimization for inter frame coding has been less successful. Recognizing that each resampling solution offers unique advantages in regions with different motion and texture characteristics, we propose a hybrid motion compensation (HMC) method that adaptively combines the predictions generated by these two approaches. Specifically, we generate a compound spatiotemporal representation (CSTR) through a recurrent information aggregation (RIA) module using information from the current and multiple past frames. We further design a one-to-many decoder pipeline to generate multiple predictions from the CSTR, including vector-based resampling, adaptive kernel-based resampling, compensation mode selection maps and texture enhancements, and combines them adaptively to achieve more accurate inter prediction. Experiments show that our proposed inter coding system can provide better motion-compensated prediction and is more robust to occlusions and complex motions. Together with jointly trained intra coder and residual coder, the overall learnt hybrid coder yields the state-of-the-art coding efficiency in low-delay scenario, compared to the traditional H.264/AVC and H.265/HEVC, as well as recently published learning-based methods, in terms of both PSNR and MS-SSIM metrics.
PDWN: Pyramid Deformable Warping Network for Video Interpolation
Apr 04, 2021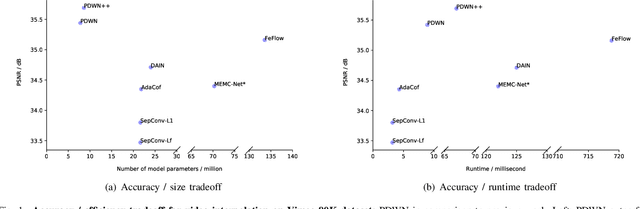
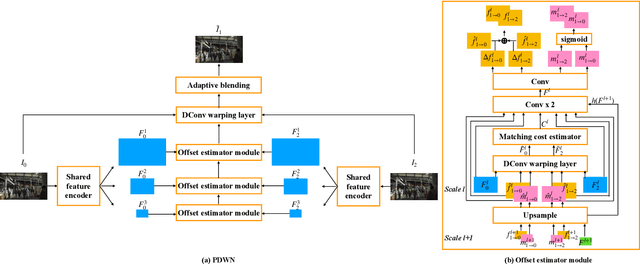


Video interpolation aims to generate a non-existent intermediate frame given the past and future frames. Many state-of-the-art methods achieve promising results by estimating the optical flow between the known frames and then generating the backward flows between the middle frame and the known frames. However, these methods usually suffer from the inaccuracy of estimated optical flows and require additional models or information to compensate for flow estimation errors. Following the recent development in using deformable convolution (DConv) for video interpolation, we propose a light but effective model, called Pyramid Deformable Warping Network (PDWN). PDWN uses a pyramid structure to generate DConv offsets of the unknown middle frame with respect to the known frames through coarse-to-fine successive refinements. Cost volumes between warped features are calculated at every pyramid level to help the offset inference. At the finest scale, the two warped frames are adaptively blended to generate the middle frame. Lastly, a context enhancement network further enhances the contextual detail of the final output. Ablation studies demonstrate the effectiveness of the coarse-to-fine offset refinement, cost volumes, and DConv. Our method achieves better or on-par accuracy compared to state-of-the-art models on multiple datasets while the number of model parameters and the inference time are substantially less than previous models. Moreover, we present an extension of the proposed framework to use four input frames, which can achieve significant improvement over using only two input frames, with only a slight increase in the model size and inference time.