 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSNVC: Single Stream Neural Video Compression with Implicit Temporal Information
Jun 11, 2024
Recently, Neural Video Compression (NVC) techniques have achieved remarkable performance, even surpassing the best traditional lossy video codec. However, most existing NVC methods heavily rely on transmitting Motion Vector (MV) to generate accurate contextual features, which has the following drawbacks. (1) Compressing and transmitting MV requires specialized MV encoder and decoder, which makes modules redundant. (2) Due to the existence of MV Encoder-Decoder, the training strategy is complex. In this paper, we present a noval Single Stream NVC framework (SSNVC), which removes complex MV Encoder-Decoder structure and uses a one-stage training strategy. SSNVC implicitly use temporal information by adding previous entropy model feature to current entropy model and using previous two frame to generate predicted motion information at the decoder side. Besides, we enhance the frame generator to generate higher quality reconstructed frame. Experiments demonstrate that SSNVC can achieve state-of-the-art performance on multiple benchmarks, and can greatly simplify compression process as well as training process.
Neural Video Coding using Multiscale Motion Compensation and Spatiotemporal Context Model
Jul 09, 2020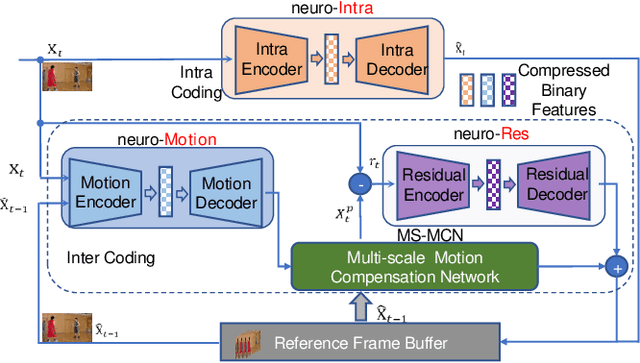
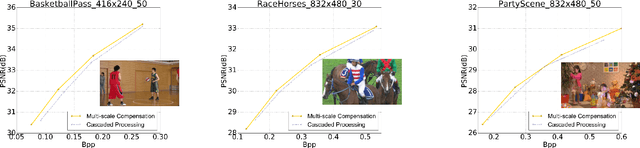
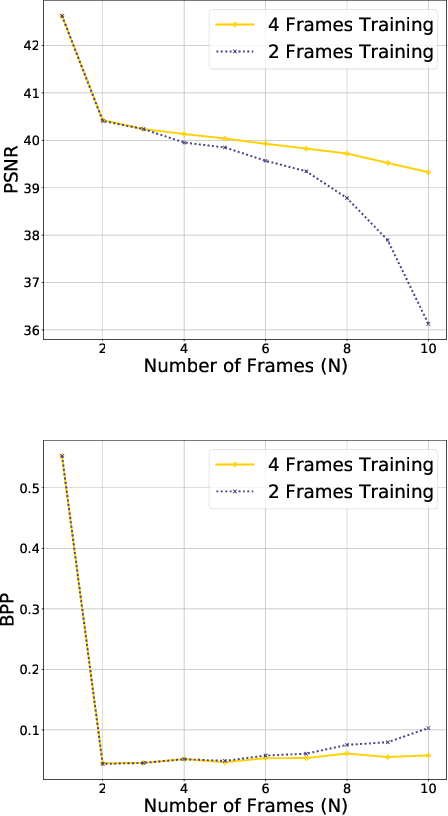
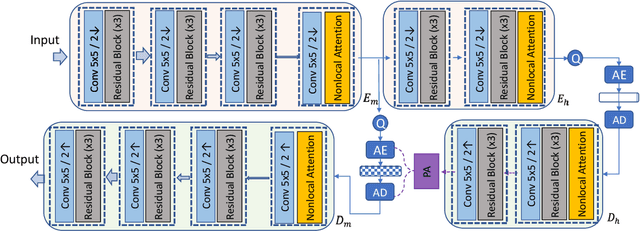
Over the past two decades, traditional block-based video coding has made remarkable progress and spawned a series of well-known standards such as MPEG-4, H.264/AVC and H.265/HEVC. On the other hand, deep neural networks (DNNs) have shown their powerful capacity for visual content understanding, feature extraction and compact representation. Some previous works have explored the learnt video coding algorithms in an end-to-end manner, which show the great potential compared with traditional methods. In this paper, we propose an end-to-end deep neural video coding framework (NVC), which uses variational autoencoders (VAEs) with joint spatial and temporal prior aggregation (PA) to exploit the correlations in intra-frame pixels, inter-frame motions and inter-frame compensation residuals, respectively. Novel features of NVC include: 1) To estimate and compensate motion over a large range of magnitudes, we propose an unsupervised multiscale motion compensation network (MS-MCN) together with a pyramid decoder in the VAE for coding motion features that generates multiscale flow fields, 2) we design a novel adaptive spatiotemporal context model for efficient entropy coding for motion information, 3) we adopt nonlocal attention modules (NLAM) at the bottlenecks of the VAEs for implicit adaptive feature extraction and activation, leveraging its high transformation capacity and unequal weighting with joint global and local information, and 4) we introduce multi-module optimization and a multi-frame training strategy to minimize the temporal error propagation among P-frames. NVC is evaluated for the low-delay causal settings and compared with H.265/HEVC, H.264/AVC and the other learnt video compression methods following the common test conditions, demonstrating consistent gains across all popular test sequences for both PSNR and MS-SSIM distortion metrics.