 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSNVC: Single Stream Neural Video Compression with Implicit Temporal Information
Jun 11, 2024
Recently, Neural Video Compression (NVC) techniques have achieved remarkable performance, even surpassing the best traditional lossy video codec. However, most existing NVC methods heavily rely on transmitting Motion Vector (MV) to generate accurate contextual features, which has the following drawbacks. (1) Compressing and transmitting MV requires specialized MV encoder and decoder, which makes modules redundant. (2) Due to the existence of MV Encoder-Decoder, the training strategy is complex. In this paper, we present a noval Single Stream NVC framework (SSNVC), which removes complex MV Encoder-Decoder structure and uses a one-stage training strategy. SSNVC implicitly use temporal information by adding previous entropy model feature to current entropy model and using previous two frame to generate predicted motion information at the decoder side. Besides, we enhance the frame generator to generate higher quality reconstructed frame. Experiments demonstrate that SSNVC can achieve state-of-the-art performance on multiple benchmarks, and can greatly simplify compression process as well as training process.
Butterfly: Multiple Reference Frames Feature Propagation Mechanism for Neural Video Compression
Mar 06, 2023



Using more reference frames can significantly improve the compression efficiency in neural video compression. However, in low-latency scenarios, most existing neural video compression frameworks usually use the previous one frame as reference. Or a few frameworks which use the previous multiple frames as reference only adopt a simple multi-reference frames propagation mechanism. In this paper, we present a more reasonable multi-reference frames propagation mechanism for neural video compression, called butterfly multi-reference frame propagation mechanism (Butterfly), which allows a more effective feature fusion of multi-reference frames. By this, we can generate more accurate temporal context conditional prior for Contextual Coding Module. Besides, when the number of decoded frames does not meet the required number of reference frames, we duplicate the nearest reference frame to achieve the requirement, which is better than duplicating the furthest one. Experiment results show that our method can significantly outperform the previous state-of-the-art (SOTA), and our neural codec can achieve -7.6% bitrate save on HEVC Class D dataset when compares with our base single-reference frame model with the same compression configuration.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
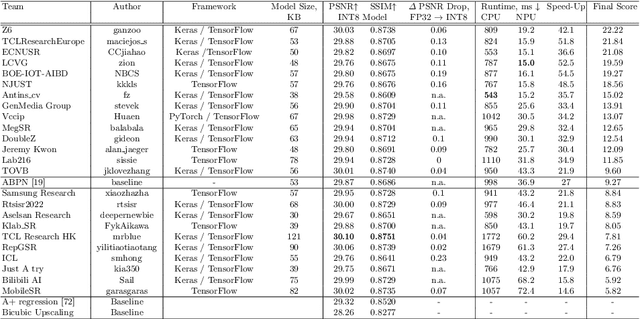
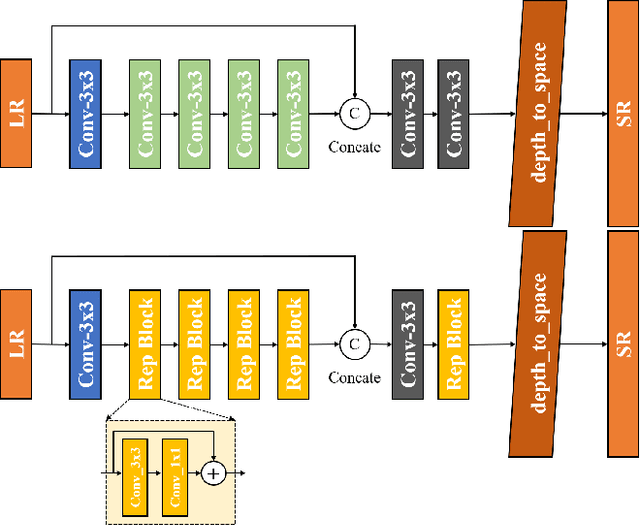
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.