 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Image-Text Correspondence with Cost Aggregation for Open-Vocabulary Part Segmentation
Jan 16, 2025Open-Vocabulary Part Segmentation (OVPS) is an emerging field for recognizing fine-grained parts in unseen categories. We identify two primary challenges in OVPS: (1) the difficulty in aligning part-level image-text correspondence, and (2) the lack of structural understanding in segmenting object parts. To address these issues, we propose PartCATSeg, a novel framework that integrates object-aware part-level cost aggregation, compositional loss, and structural guidance from DINO. Our approach employs a disentangled cost aggregation strategy that handles object and part-level costs separately, enhancing the precision of part-level segmentation. We also introduce a compositional loss to better capture part-object relationships, compensating for the limited part annotations. Additionally, structural guidance from DINO features improves boundary delineation and inter-part understanding. Extensive experiments on Pascal-Part-116, ADE20K-Part-234, and PartImageNet datasets demonstrate that our method significantly outperforms state-of-the-art approaches, setting a new baseline for robust generalization to unseen part categories.
Learning to Transfer Human Hand Skills for Robot Manipulations
Jan 07, 2025We present a method for teaching dexterous manipulation tasks to robots from human hand motion demonstrations. Unlike existing approaches that solely rely on kinematics information without taking into account the plausibility of robot and object interaction, our method directly infers plausible robot manipulation actions from human motion demonstrations. To address the embodiment gap between the human hand and the robot system, our approach learns a joint motion manifold that maps human hand movements, robot hand actions, and object movements in 3D, enabling us to infer one motion component from others. Our key idea is the generation of pseudo-supervision triplets, which pair human, object, and robot motion trajectories synthetically. Through real-world experiments with robot hand manipulation, we demonstrate that our data-driven retargeting method significantly outperforms conventional retargeting techniques, effectively bridging the embodiment gap between human and robotic hands. Website at https://rureadyo.github.io/MocapRobot/.
MaskRIS: Semantic Distortion-aware Data Augmentation for Referring Image Segmentation
Nov 28, 2024Referring Image Segmentation (RIS) is an advanced vision-language task that involves identifying and segmenting objects within an image as described by free-form text descriptions. While previous studies focused on aligning visual and language features, exploring training techniques, such as data augmentation, remains underexplored. In this work, we explore effective data augmentation for RIS and propose a novel training framework called Masked Referring Image Segmentation (MaskRIS). We observe that the conventional image augmentations fall short of RIS, leading to performance degradation, while simple random masking significantly enhances the performance of RIS. MaskRIS uses both image and text masking, followed by Distortion-aware Contextual Learning (DCL) to fully exploit the benefits of the masking strategy. This approach can improve the model's robustness to occlusions, incomplete information, and various linguistic complexities, resulting in a significant performance improvement. Experiments demonstrate that MaskRIS can easily be applied to various RIS models, outperforming existing methods in both fully supervised and weakly supervised settings. Finally, MaskRIS achieves new state-of-the-art performance on RefCOCO, RefCOCO+, and RefCOCOg datasets. Code is available at https://github.com/naver-ai/maskris.
Learning from Spatio-temporal Correlation for Semi-Supervised LiDAR Semantic Segmentation
Oct 09, 2024



We address the challenges of the semi-supervised LiDAR segmentation (SSLS) problem, particularly in low-budget scenarios. The two main issues in low-budget SSLS are the poor-quality pseudo-labels for unlabeled data, and the performance drops due to the significant imbalance between ground-truth and pseudo-labels. This imbalance leads to a vicious training cycle. To overcome these challenges, we leverage the spatio-temporal prior by recognizing the substantial overlap between temporally adjacent LiDAR scans. We propose a proximity-based label estimation, which generates highly accurate pseudo-labels for unlabeled data by utilizing semantic consistency with adjacent labeled data. Additionally, we enhance this method by progressively expanding the pseudo-labels from the nearest unlabeled scans, which helps significantly reduce errors linked to dynamic classes. Additionally, we employ a dual-branch structure to mitigate performance degradation caused by data imbalance. Experimental results demonstrate remarkable performance in low-budget settings (i.e., <= 5%) and meaningful improvements in normal budget settings (i.e., 5 - 50%). Finally, our method has achieved new state-of-the-art results on SemanticKITTI and nuScenes in semi-supervised LiDAR segmentation. With only 5% labeled data, it offers competitive results against fully-supervised counterparts. Moreover, it surpasses the performance of the previous state-of-the-art at 100% labeled data (75.2%) using only 20% of labeled data (76.0%) on nuScenes. The code is available on https://github.com/halbielee/PLE.
Understanding Multi-Granularity for Open-Vocabulary Part Segmentation
Jun 17, 2024



Open-vocabulary part segmentation (OVPS) is an emerging research area focused on segmenting fine-grained entities based on diverse and previously unseen vocabularies. Our study highlights the inherent complexities of part segmentation due to intricate boundaries and diverse granularity, reflecting the knowledge-based nature of part identification. To address these challenges, we propose PartCLIPSeg, a novel framework utilizing generalized parts and object-level contexts to mitigate the lack of generalization in fine-grained parts. PartCLIPSeg integrates competitive part relationships and attention control techniques, alleviating ambiguous boundaries and underrepresented parts. Experimental results demonstrate that PartCLIPSeg outperforms existing state-of-the-art OVPS methods, offering refined segmentation and an advanced understanding of part relationships in images. Through extensive experiments, our model demonstrated an improvement over the state-of-the-art models on the Pascal-Part-116, ADE20K-Part-234, and PartImageNet datasets.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Self-Supervised Vision Transformers Are Efficient Segmentation Learners for Imperfect Labels
Jan 23, 2024This study demonstrates a cost-effective approach to semantic segmentation using self-supervised vision transformers (SSVT). By freezing the SSVT backbone and training a lightweight segmentation head, our approach effectively utilizes imperfect labels, thereby improving robustness to label imperfections. Empirical experiments show significant performance improvements over existing methods for various annotation types, including scribble, point-level, and image-level labels. The research highlights the effectiveness of self-supervised vision transformers in dealing with imperfect labels, providing a practical and efficient solution for semantic segmentation while reducing annotation costs. Through extensive experiments, we confirm that our method outperforms baseline models for all types of imperfect labels. Especially under the zero-shot vision-language-model-based label, our model exhibits 11.5\%p performance gain compared to the baseline.
Weakly Supervised Semantic Segmentation for Driving Scenes
Dec 22, 2023State-of-the-art techniques in weakly-supervised semantic segmentation (WSSS) using image-level labels exhibit severe performance degradation on driving scene datasets such as Cityscapes. To address this challenge, we develop a new WSSS framework tailored to driving scene datasets. Based on extensive analysis of dataset characteristics, we employ Contrastive Language-Image Pre-training (CLIP) as our baseline to obtain pseudo-masks. However, CLIP introduces two key challenges: (1) pseudo-masks from CLIP lack in representing small object classes, and (2) these masks contain notable noise. We propose solutions for each issue as follows. (1) We devise Global-Local View Training that seamlessly incorporates small-scale patches during model training, thereby enhancing the model's capability to handle small-sized yet critical objects in driving scenes (e.g., traffic light). (2) We introduce Consistency-Aware Region Balancing (CARB), a novel technique that discerns reliable and noisy regions through evaluating the consistency between CLIP masks and segmentation predictions. It prioritizes reliable pixels over noisy pixels via adaptive loss weighting. Notably, the proposed method achieves 51.8\% mIoU on the Cityscapes test dataset, showcasing its potential as a strong WSSS baseline on driving scene datasets. Experimental results on CamVid and WildDash2 demonstrate the effectiveness of our method across diverse datasets, even with small-scale datasets or visually challenging conditions. The code is available at https://github.com/k0u-id/CARB.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
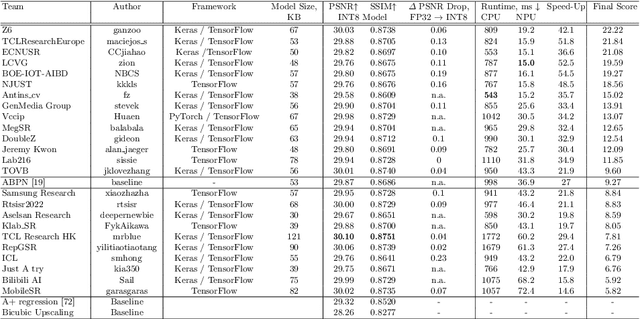
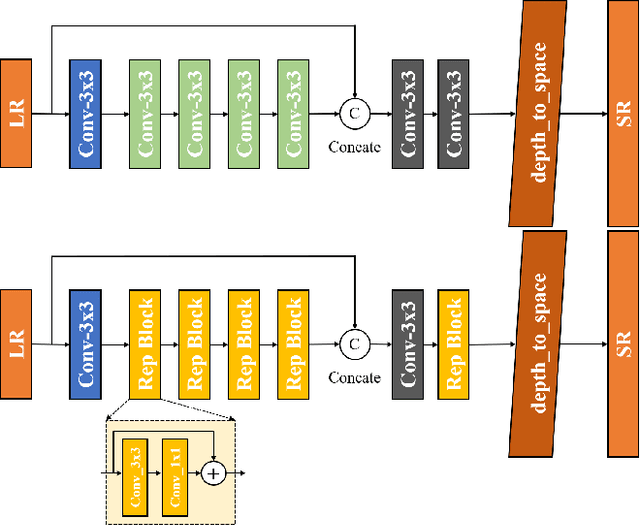
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Railroad is not a Train: Saliency as Pseudo-pixel Supervision for Weakly Supervised Semantic Segmentation
May 19, 2021
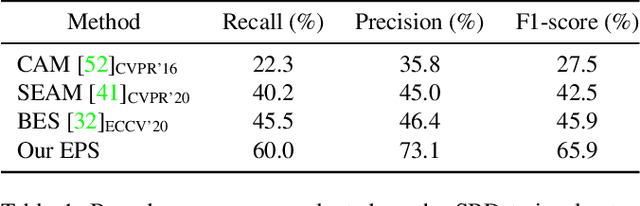
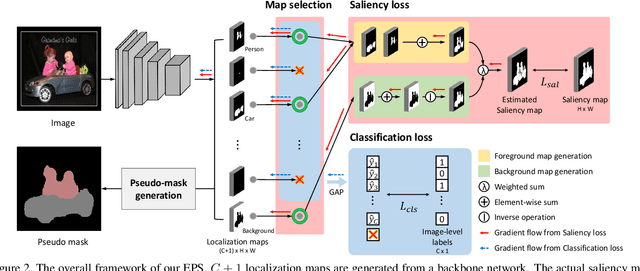
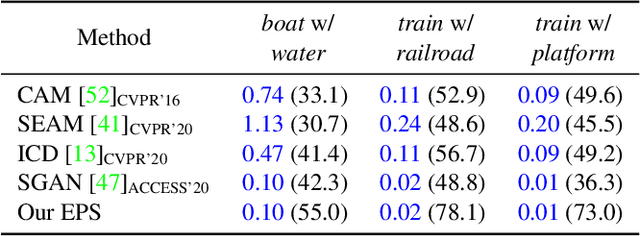
Existing studies in weakly-supervised semantic segmentation (WSSS) using image-level weak supervision have several limitations: sparse object coverage, inaccurate object boundaries, and co-occurring pixels from non-target objects. To overcome these challenges, we propose a novel framework, namely Explicit Pseudo-pixel Supervision (EPS), which learns from pixel-level feedback by combining two weak supervisions; the image-level label provides the object identity via the localization map and the saliency map from the off-the-shelf saliency detection model offers rich boundaries. We devise a joint training strategy to fully utilize the complementary relationship between both information. Our method can obtain accurate object boundaries and discard co-occurring pixels, thereby significantly improving the quality of pseudo-masks. Experimental results show that the proposed method remarkably outperforms existing methods by resolving key challenges of WSSS and achieves the new state-of-the-art performance on both PASCAL VOC 2012 and MS COCO 2014 datasets.