 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Reward for Multi-View 3D Reasoning with Global Maps and Local Views
Jun 22, 2026Multi-view 3D Visual Question Answering (MV3D-VQA) requires integrating partial observations into a coherent 3D scene representation and selecting informative viewpoints for multi-step spatial reasoning. However, current multimodal LLMs are typically trained with sparse, answer-level supervision, which often yields inconsistent cross-view reasoning and brittle view selection. We present DR-MV3D (Dense Reward for MV3D-VQA), a map-grounded learning framework that provides dense, verifiable rewards to supervise the reasoning process. Our approach decomposes MV3D-VQA into (i) allocentric global map construction, (ii) question-conditioned view-trajectory planning, and (iii) egocentric grounding for answer prediction. To make intermediate steps learnable without manual annotations, we introduce two rewards: a global consistency reward that aligns the predicted map with geometry-consistent pseudo targets from frozen 3D vision foundation models (e.g., VGGT + SAM3), and a local trajectory reward that supervises ordered viewpoint selection. We optimize the full pipeline with trajectory-level policy optimization (GRPO). Experiments on MindCube, VSI-Bench, and BLINK (MV) show that DR-MV3D consistently improves over strong multi-image baselines, supporting the effectiveness of process-level dense supervision for multi-view 3D reasoning.
MS-rPPG: Multi-spectral State Space Model for Remote Photoplethysmography in Driver Monitoring Systems
Jun 19, 2026Remote photoplethysmography (rPPG) is a camera-based technique for measuring physiological signals, particularly cardiac activity. From the remotely measured signals, heart rate can be estimated, which is crucial for health monitoring. In this study, we investigate a driver health monitoring system based on remote heart rate estimation. However, driving environments represent uncontrolled settings where videos are subject to varying illumination conditions and frequent head movements. We introduce MS-rPPG, a multi-spectral framework that combines RGB with near-infrared (NIR) face video to alleviate rPPG estimation under challenging driving conditions. To combine the complementary features from two spectral videos, we propose a cross-spectral linear modulation (CSLM) strategy based on frequency-domain analysis. Moreover, we introduce MS-Mamba, a novel state space model designed to effectively model long-range temporal dependencies while jointly capturing cross-channel interactions between multi-spectral features. We collected a real-world dataset called MS-Drive, which was recorded from 50 participants while driving the vehicle. The proposed method was evaluated on the MR-NIRP Car dataset and MS-Drive datasets. The experimental results indicate that MS-rPPG shows better robustness and heart rate estimation accuracy than previous methods, highlighting its promise for driver health monitoring. The codes are available at github.com/ziiho08/MS-rPPG.
Mitigating Perceptual Judgment Bias in Multimodal LLM-as-a-Judge via Perceptual Perturbation and Reward Modeling
Jun 01, 2026Recent multimodal large language models have demonstrated strong reasoning ability, yet their reliability as automated evaluators remains limited by a critical weakness: when visual evidence conflicts with textual cues, MLLM judges tend to reward plausible narratives over perceptually correct answers. We identify and systematically analyze this phenomenon, which we term Perceptual Judgment Bias. Through controlled visual perturbations, existing multimodal judges frequently anchor on the response text instead of their own visual perception, leading to inconsistent and non-verifiable evaluations. To address this issue, we introduce the Perceptually Perturbed Judgment Dataset, which constructs minimally edited counterfactual responses that isolate perceptual errors and enable verifiable supervision. Building on this dataset, we develop a unified training framework that combines a structured GRPO-based reward with a batch-ranking objective, achieving coherent global ordering without explicit pairwise labels. Experiments across diverse MLLM-as-a-Judge benchmarks show that our approach substantially improves perceptual fidelity, ranking coherence, and alignment with human evaluation. Our results establish a scalable and generalizable pathway for training multimodal judges that are perceptually grounded, interpretable, and robust to visual-reasoning conflicts.
Weighted Knowledge Distillation for Semi-Supervised Segmentation of Maxillary Sinus in Panoramic X-ray Images
Apr 22, 2026Accurate segmentation of maxillary sinus in panoramic X-ray images is essential for dental diagnosis and surgical planning; however, this task remains relatively underexplored in dental imaging research. Structural overlap, ambiguous anatomical boundaries inherent to two-dimensional panoramic projections, and the limited availability of large scale clinical datasets with reliable pixel-level annotations make the development and evaluation of segmentation models challenging. To address these challenges, we propose a semi-supervised segmentation framework that effectively leverages both labeled and unlabeled panoramic radiographs, where knowledge distillation is utilized to train a student model with reliable structural information distilled from a teacher model. Specifically, we introduce a weighted knowledge distillation loss to suppress unreliable distillation signals caused by structural discrepancies between teacher and student predictions. To further enhance the quality of pseudo labels generated by the teacher network, we introduce SinusCycle-GAN which is a refinement network based on unpaired image-to-image translation. This refinement process improves the precision of boundaries and reduces noise propagation when learning from unlabeled data during semi-supervised training. To evaluate the proposed method, we collected clinical panoramic X-ray images from 2,511 patients, and experimental results demonstrate that the proposed method outperforms state-of-the-art segmentation models, achieving the Dice score of 96.35\% while reducing boundary error. The results indicate that the proposed semi-supervised framework provides robust and anatomically consistent segmentation performance under limited labeled data conditions, highlighting its potential for broader dental image analysis applications.
When Sinks Help or Hurt: Unified Framework for Attention Sink in Large Vision-Language Models
Apr 01, 2026Attention sinks are defined as tokens that attract disproportionate attention. While these have been studied in single modality transformers, their cross-modal impact in Large Vision-Language Models (LVLM) remains largely unexplored: are they redundant artifacts or essential global priors? This paper first categorizes visual sinks into two distinct categories: ViT-emerged sinks (V-sinks), which propagate from the vision encoder, and LLM-emerged sinks (L-sinks), which arise within deep LLM layers. Based on the new definition, our analysis reveals a fundamental performance trade-off: while sinks effectively encode global scene-level priors, their dominance can suppress the fine-grained visual evidence required for local perception. Furthermore, we identify specific functional layers where modulating these sinks most significantly impacts downstream performance. To leverage these insights, we propose Layer-wise Sink Gating (LSG), a lightweight, plug-and-play module that dynamically scales the attention contributions of V-sink and the rest visual tokens. LSG is trained via standard next-token prediction, requiring no task-specific supervision while keeping the LVLM backbone frozen. In most layers, LSG yields improvements on representative multimodal benchmarks, effectively balancing global reasoning and precise local evidence.
Sparse Bayesian Message Passing under Structural Uncertainty
Jan 03, 2026Semi-supervised learning on real-world graphs is frequently challenged by heterophily, where the observed graph is unreliable or label-disassortative. Many existing graph neural networks either rely on a fixed adjacency structure or attempt to handle structural noise through regularization. In this work, we explicitly capture structural uncertainty by modeling a posterior distribution over signed adjacency matrices, allowing each edge to be positive, negative, or absent. We propose a sparse signed message passing network that is naturally robust to edge noise and heterophily, which can be interpreted from a Bayesian perspective. By combining (i) posterior marginalization over signed graph structures with (ii) sparse signed message aggregation, our approach offers a principled way to handle both edge noise and heterophily. Experimental results demonstrate that our method outperforms strong baseline models on heterophilic benchmarks under both synthetic and real-world structural noise.
PosterForest: Hierarchical Multi-Agent Collaboration for Scientific Poster Generation
Aug 29, 2025We present a novel training-free framework, \textit{PosterForest}, for automated scientific poster generation. Unlike prior approaches, which largely neglect the hierarchical structure of scientific documents and the semantic integration of textual and visual elements, our method addresses both challenges directly. We introduce the \textit{Poster Tree}, a hierarchical intermediate representation that jointly encodes document structure and visual-textual relationships at multiple levels. Our framework employs a multi-agent collaboration strategy, where agents specializing in content summarization and layout planning iteratively coordinate and provide mutual feedback. This approach enables the joint optimization of logical consistency, content fidelity, and visual coherence. Extensive experiments on multiple academic domains show that our method outperforms existing baselines in both qualitative and quantitative evaluations. The resulting posters achieve quality closest to expert-designed ground truth and deliver superior information preservation, structural clarity, and user preference.
Sheaf Graph Neural Networks via PAC-Bayes Spectral Optimization
Aug 01, 2025Over-smoothing in Graph Neural Networks (GNNs) causes collapse in distinct node features, particularly on heterophilic graphs where adjacent nodes often have dissimilar labels. Although sheaf neural networks partially mitigate this problem, they typically rely on static or heavily parameterized sheaf structures that hinder generalization and scalability. Existing sheaf-based models either predefine restriction maps or introduce excessive complexity, yet fail to provide rigorous stability guarantees. In this paper, we introduce a novel scheme called SGPC (Sheaf GNNs with PAC-Bayes Calibration), a unified architecture that combines cellular-sheaf message passing with several mechanisms, including optimal transport-based lifting, variance-reduced diffusion, and PAC-Bayes spectral regularization for robust semi-supervised node classification. We establish performance bounds theoretically and demonstrate that the resulting bound-aware objective can be achieved via end-to-end training in linear computational complexity. Experiments on nine homophilic and heterophilic benchmarks show that SGPC outperforms state-of-the-art spectral and sheaf-based GNNs while providing certified confidence intervals on unseen nodes.
3D-Aware Vision-Language Models Fine-Tuning with Geometric Distillation
Jun 11, 2025Vision-Language Models (VLMs) have shown remarkable performance on diverse visual and linguistic tasks, yet they remain fundamentally limited in their understanding of 3D spatial structures. We propose Geometric Distillation, a lightweight, annotation-free fine-tuning framework that injects human-inspired geometric cues into pretrained VLMs without modifying their architecture. By distilling (1) sparse correspondences, (2) relative depth relations, and (3) dense cost volumes from off-the-shelf 3D foundation models (e.g., MASt3R, VGGT), our method shapes representations to be geometry-aware while remaining compatible with natural image-text inputs. Through extensive evaluations on 3D vision-language reasoning and 3D perception benchmarks, our method consistently outperforms prior approaches, achieving improved 3D spatial reasoning with significantly lower computational cost. Our work demonstrates a scalable and efficient path to bridge 2D-trained VLMs with 3D understanding, opening up wider use in spatially grounded multimodal tasks.
AdaRank: Adaptive Rank Pruning for Enhanced Model Merging
Mar 28, 2025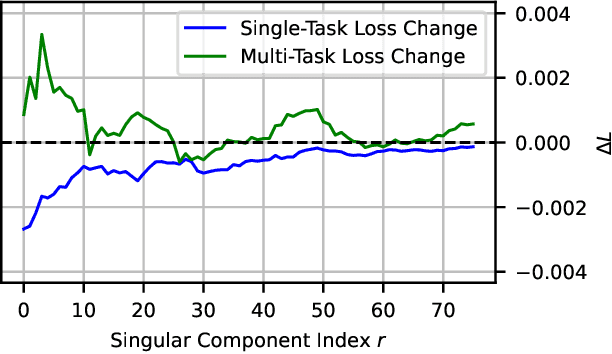
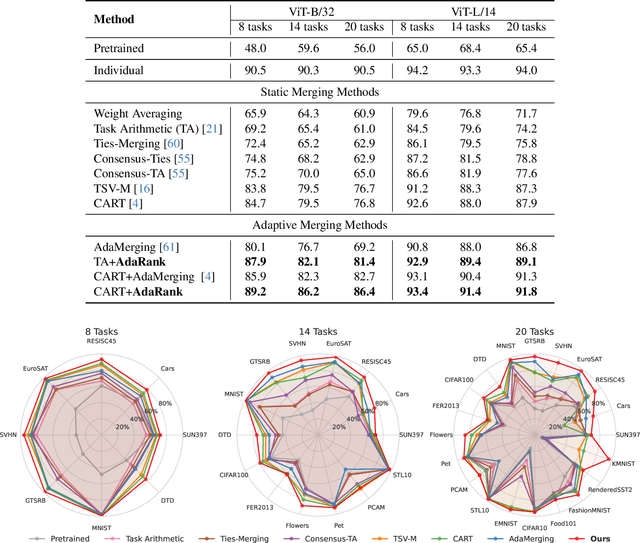
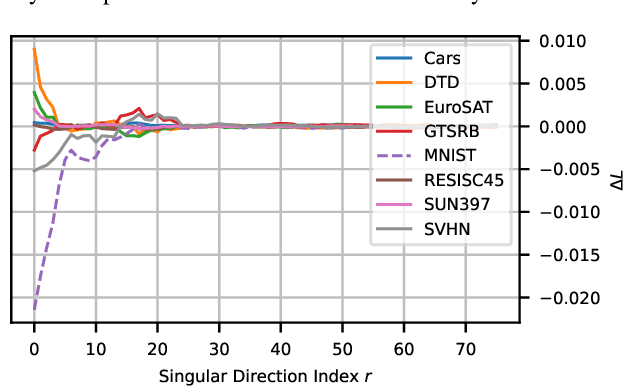
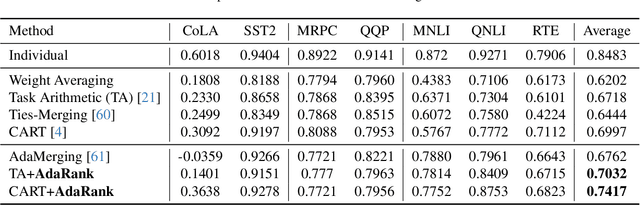
Model merging has emerged as a promising approach for unifying independently fine-tuned models into an integrated framework, significantly enhancing computational efficiency in multi-task learning. Recently, several SVD-based techniques have been introduced to exploit low-rank structures for enhanced merging, but their reliance on such manually designed rank selection often leads to cross-task interference and suboptimal performance. In this paper, we propose AdaRank, a novel model merging framework that adaptively selects the most beneficial singular directions of task vectors to merge multiple models. We empirically show that the dominant singular components of task vectors can cause critical interference with other tasks, and that naive truncation across tasks and layers degrades performance. In contrast, AdaRank dynamically prunes the singular components that cause interference and offers an optimal amount of information to each task vector by learning to prune ranks during test-time via entropy minimization. Our analysis demonstrates that such method mitigates detrimental overlaps among tasks, while empirical results show that AdaRank consistently achieves state-of-the-art performance with various backbones and number of tasks, reducing the performance gap between fine-tuned models to nearly 1%.