 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Perceptual Judgment Bias in Multimodal LLM-as-a-Judge via Perceptual Perturbation and Reward Modeling
Jun 01, 2026Recent multimodal large language models have demonstrated strong reasoning ability, yet their reliability as automated evaluators remains limited by a critical weakness: when visual evidence conflicts with textual cues, MLLM judges tend to reward plausible narratives over perceptually correct answers. We identify and systematically analyze this phenomenon, which we term Perceptual Judgment Bias. Through controlled visual perturbations, existing multimodal judges frequently anchor on the response text instead of their own visual perception, leading to inconsistent and non-verifiable evaluations. To address this issue, we introduce the Perceptually Perturbed Judgment Dataset, which constructs minimally edited counterfactual responses that isolate perceptual errors and enable verifiable supervision. Building on this dataset, we develop a unified training framework that combines a structured GRPO-based reward with a batch-ranking objective, achieving coherent global ordering without explicit pairwise labels. Experiments across diverse MLLM-as-a-Judge benchmarks show that our approach substantially improves perceptual fidelity, ranking coherence, and alignment with human evaluation. Our results establish a scalable and generalizable pathway for training multimodal judges that are perceptually grounded, interpretable, and robust to visual-reasoning conflicts.
Representation Alignment for Just Image Transformers is not Easier than You Think
Mar 15, 2026Representation Alignment (REPA) has emerged as a simple way to accelerate Diffusion Transformers training in latent space. At the same time, pixel-space diffusion transformers such as Just image Transformers (JiT) have attracted growing attention because they remove a dependency on a pretrained tokenizer, and then avoid the reconstruction bottleneck of latent diffusion. This paper shows that the REPA can fail for JiT. REPA yields worse FID for JiT as training proceeds and collapses diversity on image subsets that are tightly clustered in the representation space of pretrained semantic encoder on ImageNet. We trace the failure to an information asymmetry: denoising occurs in the high dimensional image space, while the semantic target is strongly compressed, making direct regression a shortcut objective. We propose PixelREPA, which transforms the alignment target and constrains alignment with a Masked Transformer Adapter that combines a shallow transformer adapter with partial token masking. PixelREPA improves both training convergence and final quality. PixelREPA reduces FID from 3.66 to 3.17 for JiT-B$/16$ and improves Inception Score (IS) from 275.1 to 284.6 on ImageNet $256 \times 256$, while achieving $> 2\times$ faster convergence. Finally, PixelREPA-H$/16$ achieves FID$=1.81$ and IS$=317.2$. Our code is available at https://github.com/kaist-cvml/PixelREPA.
DreamCatalyst: Fast and High-Quality 3D Editing via Controlling Editability and Identity Preservation
Jul 16, 2024



Score distillation sampling (SDS) has emerged as an effective framework in text-driven 3D editing tasks due to its inherent 3D consistency. However, existing SDS-based 3D editing methods suffer from extensive training time and lead to low-quality results, primarily because these methods deviate from the sampling dynamics of diffusion models. In this paper, we propose DreamCatalyst, a novel framework that interprets SDS-based editing as a diffusion reverse process. Our objective function considers the sampling dynamics, thereby making the optimization process of DreamCatalyst an approximation of the diffusion reverse process in editing tasks. DreamCatalyst aims to reduce training time and improve editing quality. DreamCatalyst presents two modes: (1) a faster mode, which edits the NeRF scene in only about 25 minutes, and (2) a high-quality mode, which produces superior results in less than 70 minutes. Specifically, our high-quality mode outperforms current state-of-the-art NeRF editing methods both in terms of speed and quality. See more extensive results on our project page: https://dream-catalyst.github.io.
MagiCapture: High-Resolution Multi-Concept Portrait Customization
Sep 13, 2023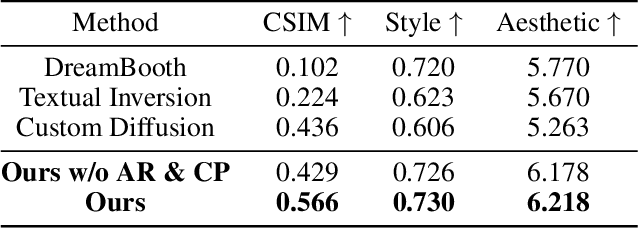
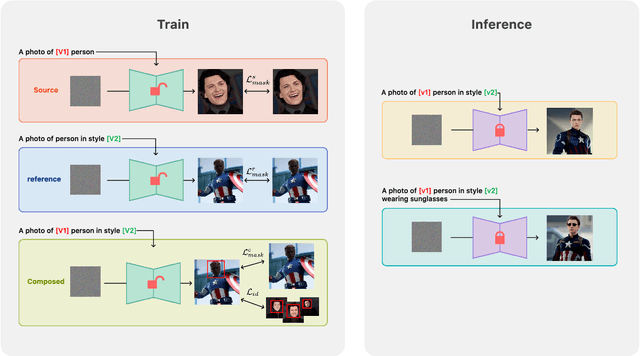
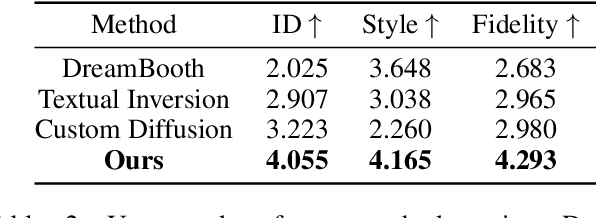

Large-scale text-to-image models including Stable Diffusion are capable of generating high-fidelity photorealistic portrait images. There is an active research area dedicated to personalizing these models, aiming to synthesize specific subjects or styles using provided sets of reference images. However, despite the plausible results from these personalization methods, they tend to produce images that often fall short of realism and are not yet on a commercially viable level. This is particularly noticeable in portrait image generation, where any unnatural artifact in human faces is easily discernible due to our inherent human bias. To address this, we introduce MagiCapture, a personalization method for integrating subject and style concepts to generate high-resolution portrait images using just a few subject and style references. For instance, given a handful of random selfies, our fine-tuned model can generate high-quality portrait images in specific styles, such as passport or profile photos. The main challenge with this task is the absence of ground truth for the composed concepts, leading to a reduction in the quality of the final output and an identity shift of the source subject. To address these issues, we present a novel Attention Refocusing loss coupled with auxiliary priors, both of which facilitate robust learning within this weakly supervised learning setting. Our pipeline also includes additional post-processing steps to ensure the creation of highly realistic outputs. MagiCapture outperforms other baselines in both quantitative and qualitative evaluations and can also be generalized to other non-human objects.