 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Alignment for Just Image Transformers is not Easier than You Think
Mar 15, 2026Representation Alignment (REPA) has emerged as a simple way to accelerate Diffusion Transformers training in latent space. At the same time, pixel-space diffusion transformers such as Just image Transformers (JiT) have attracted growing attention because they remove a dependency on a pretrained tokenizer, and then avoid the reconstruction bottleneck of latent diffusion. This paper shows that the REPA can fail for JiT. REPA yields worse FID for JiT as training proceeds and collapses diversity on image subsets that are tightly clustered in the representation space of pretrained semantic encoder on ImageNet. We trace the failure to an information asymmetry: denoising occurs in the high dimensional image space, while the semantic target is strongly compressed, making direct regression a shortcut objective. We propose PixelREPA, which transforms the alignment target and constrains alignment with a Masked Transformer Adapter that combines a shallow transformer adapter with partial token masking. PixelREPA improves both training convergence and final quality. PixelREPA reduces FID from 3.66 to 3.17 for JiT-B$/16$ and improves Inception Score (IS) from 275.1 to 284.6 on ImageNet $256 \times 256$, while achieving $> 2\times$ faster convergence. Finally, PixelREPA-H$/16$ achieves FID$=1.81$ and IS$=317.2$. Our code is available at https://github.com/kaist-cvml/PixelREPA.
Interpretable Debiasing of Vision-Language Models for Social Fairness
Feb 27, 2026The rapid advancement of Vision-Language models (VLMs) has raised growing concerns that their black-box reasoning processes could lead to unintended forms of social bias. Current debiasing approaches focus on mitigating surface-level bias signals through post-hoc learning or test-time algorithms, while leaving the internal dynamics of the model largely unexplored. In this work, we introduce an interpretable, model-agnostic bias mitigation framework, DeBiasLens, that localizes social attribute neurons in VLMs through sparse autoencoders (SAEs) applied to multimodal encoders. Building upon the disentanglement ability of SAEs, we train them on facial image or caption datasets without corresponding social attribute labels to uncover neurons highly responsive to specific demographics, including those that are underrepresented. By selectively deactivating the social neurons most strongly tied to bias for each group, we effectively mitigate socially biased behaviors of VLMs without degrading their semantic knowledge. Our research lays the groundwork for future auditing tools, prioritizing social fairness in emerging real-world AI systems.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Directional Textual Inversion for Personalized Text-to-Image Generation
Dec 15, 2025Textual Inversion (TI) is an efficient approach to text-to-image personalization but often fails on complex prompts. We trace these failures to embedding norm inflation: learned tokens drift to out-of-distribution magnitudes, degrading prompt conditioning in pre-norm Transformers. Empirically, we show semantics are primarily encoded by direction in CLIP token space, while inflated norms harm contextualization; theoretically, we analyze how large magnitudes attenuate positional information and hinder residual updates in pre-norm blocks. We propose Directional Textual Inversion (DTI), which fixes the embedding magnitude to an in-distribution scale and optimizes only direction on the unit hypersphere via Riemannian SGD. We cast direction learning as MAP with a von Mises-Fisher prior, yielding a constant-direction prior gradient that is simple and efficient to incorporate. Across personalization tasks, DTI improves text fidelity over TI and TI-variants while maintaining subject similarity. Crucially, DTI's hyperspherical parameterization enables smooth, semantically coherent interpolation between learned concepts (slerp), a capability that is absent in standard TI. Our findings suggest that direction-only optimization is a robust and scalable path for prompt-faithful personalization.
Robust Driving QA through Metadata-Grounded Context and Task-Specific Prompts
Oct 21, 2025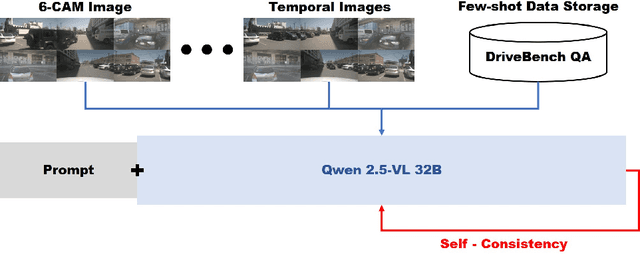
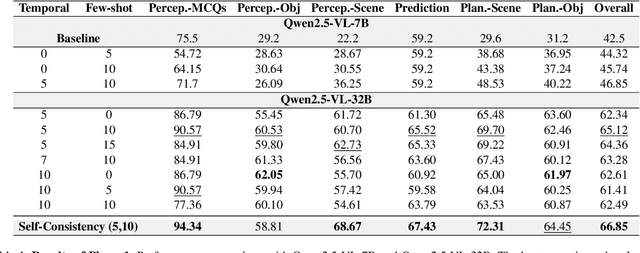
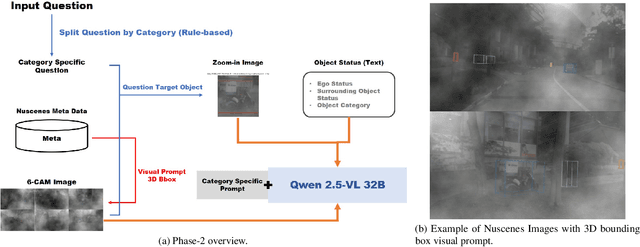

We present a two-phase vision-language QA system for autonomous driving that answers high-level perception, prediction, and planning questions. In Phase-1, a large multimodal LLM (Qwen2.5-VL-32B) is conditioned on six-camera inputs, a short temporal window of history, and a chain-of-thought prompt with few-shot exemplars. A self-consistency ensemble (multiple sampled reasoning chains) further improves answer reliability. In Phase-2, we augment the prompt with nuScenes scene metadata (object annotations, ego-vehicle state, etc.) and category-specific question instructions (separate prompts for perception, prediction, planning tasks). In experiments on a driving QA benchmark, our approach significantly outperforms the baseline Qwen2.5 models. For example, using 5 history frames and 10-shot prompting in Phase-1 yields 65.1% overall accuracy (vs.62.61% with zero-shot); applying self-consistency raises this to 66.85%. Phase-2 achieves 67.37% overall. Notably, the system maintains 96% accuracy under severe visual corruption. These results demonstrate that carefully engineered prompts and contextual grounding can greatly enhance high-level driving QA with pretrained vision-language models.
Multi-Objective Task-Aware Predictor for Image-Text Alignment
Oct 01, 2025Evaluating image-text alignment while reflecting human preferences across multiple aspects is a significant issue for the development of reliable vision-language applications. It becomes especially crucial in real-world scenarios where multiple valid descriptions exist depending on contexts or user needs. However, research progress is hindered by the lack of comprehensive benchmarks and existing evaluation predictors lacking at least one of these key properties: (1) Alignment with human judgments, (2) Long-sequence processing, (3) Inference efficiency, and (4) Applicability to multi-objective scoring. To address these challenges, we propose a plug-and-play architecture to build a robust predictor, MULTI-TAP (Multi-Objective Task-Aware Predictor), capable of both multi and single-objective scoring. MULTI-TAP can produce a single overall score, utilizing a reward head built on top of a large vision-language model (LVLMs). We show that MULTI-TAP is robust in terms of application to different LVLM architectures, achieving significantly higher performance than existing metrics and even on par with the GPT-4o-based predictor, G-VEval, with a smaller size (7-8B). By training a lightweight ridge regression layer on the frozen hidden states of a pre-trained LVLM, MULTI-TAP can produce fine-grained scores for multiple human-interpretable objectives. MULTI-TAP performs better than VisionREWARD, a high-performing multi-objective reward model, in both performance and efficiency on multi-objective benchmarks and our newly released text-image-to-text dataset, EYE4ALL. Our new dataset, consisting of chosen/rejected human preferences (EYE4ALLPref) and human-annotated fine-grained scores across seven dimensions (EYE4ALLMulti), can serve as a foundation for developing more accessible AI systems by capturing the underlying preferences of users, including blind and low-vision (BLV) individuals.
PosterForest: Hierarchical Multi-Agent Collaboration for Scientific Poster Generation
Aug 29, 2025We present a novel training-free framework, \textit{PosterForest}, for automated scientific poster generation. Unlike prior approaches, which largely neglect the hierarchical structure of scientific documents and the semantic integration of textual and visual elements, our method addresses both challenges directly. We introduce the \textit{Poster Tree}, a hierarchical intermediate representation that jointly encodes document structure and visual-textual relationships at multiple levels. Our framework employs a multi-agent collaboration strategy, where agents specializing in content summarization and layout planning iteratively coordinate and provide mutual feedback. This approach enables the joint optimization of logical consistency, content fidelity, and visual coherence. Extensive experiments on multiple academic domains show that our method outperforms existing baselines in both qualitative and quantitative evaluations. The resulting posters achieve quality closest to expert-designed ground truth and deliver superior information preservation, structural clarity, and user preference.
3D-Aware Vision-Language Models Fine-Tuning with Geometric Distillation
Jun 11, 2025Vision-Language Models (VLMs) have shown remarkable performance on diverse visual and linguistic tasks, yet they remain fundamentally limited in their understanding of 3D spatial structures. We propose Geometric Distillation, a lightweight, annotation-free fine-tuning framework that injects human-inspired geometric cues into pretrained VLMs without modifying their architecture. By distilling (1) sparse correspondences, (2) relative depth relations, and (3) dense cost volumes from off-the-shelf 3D foundation models (e.g., MASt3R, VGGT), our method shapes representations to be geometry-aware while remaining compatible with natural image-text inputs. Through extensive evaluations on 3D vision-language reasoning and 3D perception benchmarks, our method consistently outperforms prior approaches, achieving improved 3D spatial reasoning with significantly lower computational cost. Our work demonstrates a scalable and efficient path to bridge 2D-trained VLMs with 3D understanding, opening up wider use in spatially grounded multimodal tasks.
Rethinking Direct Preference Optimization in Diffusion Models
May 24, 2025



Aligning text-to-image (T2I) diffusion models with human preferences has emerged as a critical research challenge. While recent advances in this area have extended preference optimization techniques from large language models (LLMs) to the diffusion setting, they often struggle with limited exploration. In this work, we propose a novel and orthogonal approach to enhancing diffusion-based preference optimization. First, we introduce a stable reference model update strategy that relaxes the frozen reference model, encouraging exploration while maintaining a stable optimization anchor through reference model regularization. Second, we present a timestep-aware training strategy that mitigates the reward scale imbalance problem across timesteps. Our method can be integrated into various preference optimization algorithms. Experimental results show that our approach improves the performance of state-of-the-art methods on human preference evaluation benchmarks.
No Thing, Nothing: Highlighting Safety-Critical Classes for Robust LiDAR Semantic Segmentation in Adverse Weather
Mar 20, 2025Existing domain generalization methods for LiDAR semantic segmentation under adverse weather struggle to accurately predict "things" categories compared to "stuff" categories. In typical driving scenes, "things" categories can be dynamic and associated with higher collision risks, making them crucial for safe navigation and planning. Recognizing the importance of "things" categories, we identify their performance drop as a serious bottleneck in existing approaches. We observed that adverse weather induces degradation of semantic-level features and both corruption of local features, leading to a misprediction of "things" as "stuff". To mitigate these corruptions, we suggest our method, NTN - segmeNt Things for No-accident. To address semantic-level feature corruption, we bind each point feature to its superclass, preventing the misprediction of things classes into visually dissimilar categories. Additionally, to enhance robustness against local corruption caused by adverse weather, we define each LiDAR beam as a local region and propose a regularization term that aligns the clean data with its corrupted counterpart in feature space. NTN achieves state-of-the-art performance with a +2.6 mIoU gain on the SemanticKITTI-to-SemanticSTF benchmark and +7.9 mIoU on the SemanticPOSS-to-SemanticSTF benchmark. Notably, NTN achieves a +4.8 and +7.9 mIoU improvement on "things" classes, respectively, highlighting its effectiveness.