 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA computer vision-based model for occupancy detection using low-resolution thermal images
May 13, 2025Occupancy plays an essential role in influencing the energy consumption and operation of heating, ventilation, and air conditioning (HVAC) systems. Traditional HVAC typically operate on fixed schedules without considering occupancy. Advanced occupant-centric control (OCC) adopted occupancy status in regulating HVAC operations. RGB images combined with computer vision (CV) techniques are widely used for occupancy detection, however, the detailed facial and body features they capture raise significant privacy concerns. Low-resolution thermal images offer a non-invasive solution that mitigates privacy issues. The study developed an occupancy detection model utilizing low-resolution thermal images and CV techniques, where transfer learning was applied to fine-tune the You Only Look Once version 5 (YOLOv5) model. The developed model ultimately achieved satisfactory performance, with precision, recall, mAP50, and mAP50 values approaching 1.000. The contributions of this model lie not only in mitigating privacy concerns but also in reducing computing resource demands.
Fine-Grained Image-Text Correspondence with Cost Aggregation for Open-Vocabulary Part Segmentation
Jan 16, 2025Open-Vocabulary Part Segmentation (OVPS) is an emerging field for recognizing fine-grained parts in unseen categories. We identify two primary challenges in OVPS: (1) the difficulty in aligning part-level image-text correspondence, and (2) the lack of structural understanding in segmenting object parts. To address these issues, we propose PartCATSeg, a novel framework that integrates object-aware part-level cost aggregation, compositional loss, and structural guidance from DINO. Our approach employs a disentangled cost aggregation strategy that handles object and part-level costs separately, enhancing the precision of part-level segmentation. We also introduce a compositional loss to better capture part-object relationships, compensating for the limited part annotations. Additionally, structural guidance from DINO features improves boundary delineation and inter-part understanding. Extensive experiments on Pascal-Part-116, ADE20K-Part-234, and PartImageNet datasets demonstrate that our method significantly outperforms state-of-the-art approaches, setting a new baseline for robust generalization to unseen part categories.
MaskRIS: Semantic Distortion-aware Data Augmentation for Referring Image Segmentation
Nov 28, 2024Referring Image Segmentation (RIS) is an advanced vision-language task that involves identifying and segmenting objects within an image as described by free-form text descriptions. While previous studies focused on aligning visual and language features, exploring training techniques, such as data augmentation, remains underexplored. In this work, we explore effective data augmentation for RIS and propose a novel training framework called Masked Referring Image Segmentation (MaskRIS). We observe that the conventional image augmentations fall short of RIS, leading to performance degradation, while simple random masking significantly enhances the performance of RIS. MaskRIS uses both image and text masking, followed by Distortion-aware Contextual Learning (DCL) to fully exploit the benefits of the masking strategy. This approach can improve the model's robustness to occlusions, incomplete information, and various linguistic complexities, resulting in a significant performance improvement. Experiments demonstrate that MaskRIS can easily be applied to various RIS models, outperforming existing methods in both fully supervised and weakly supervised settings. Finally, MaskRIS achieves new state-of-the-art performance on RefCOCO, RefCOCO+, and RefCOCOg datasets. Code is available at https://github.com/naver-ai/maskris.
Understanding Multi-Granularity for Open-Vocabulary Part Segmentation
Jun 17, 2024



Open-vocabulary part segmentation (OVPS) is an emerging research area focused on segmenting fine-grained entities based on diverse and previously unseen vocabularies. Our study highlights the inherent complexities of part segmentation due to intricate boundaries and diverse granularity, reflecting the knowledge-based nature of part identification. To address these challenges, we propose PartCLIPSeg, a novel framework utilizing generalized parts and object-level contexts to mitigate the lack of generalization in fine-grained parts. PartCLIPSeg integrates competitive part relationships and attention control techniques, alleviating ambiguous boundaries and underrepresented parts. Experimental results demonstrate that PartCLIPSeg outperforms existing state-of-the-art OVPS methods, offering refined segmentation and an advanced understanding of part relationships in images. Through extensive experiments, our model demonstrated an improvement over the state-of-the-art models on the Pascal-Part-116, ADE20K-Part-234, and PartImageNet datasets.
Forging Tokens for Improved Storage-efficient Training
Dec 15, 2023Recent advancements in Deep Neural Network (DNN) models have significantly improved performance across computer vision tasks. However, achieving highly generalizable and high-performing vision models requires extensive datasets, leading to large storage requirements. This storage challenge poses a critical bottleneck for scaling up vision models. Motivated by the success of discrete representations, SeiT proposes to use Vector-Quantized (VQ) feature vectors (i.e., tokens) as network inputs for vision classification. However, applying traditional data augmentations to tokens faces challenges due to input domain shift. To address this issue, we introduce TokenAdapt and ColorAdapt, simple yet effective token-based augmentation strategies. TokenAdapt realigns token embedding space for compatibility with spatial augmentations, preserving the model's efficiency without requiring fine-tuning. Additionally, ColorAdapt addresses color-based augmentations for tokens inspired by Adaptive Instance Normalization (AdaIN). We evaluate our approach across various scenarios, including storage-efficient ImageNet-1k classification, fine-grained classification, robustness benchmarks, and ADE-20k semantic segmentation. Experimental results demonstrate consistent performance improvement in diverse experiments. Code is available at https://github.com/naver-ai/tokenadapt.
Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurate Segmentation Model Against Thresholds
Mar 30, 2022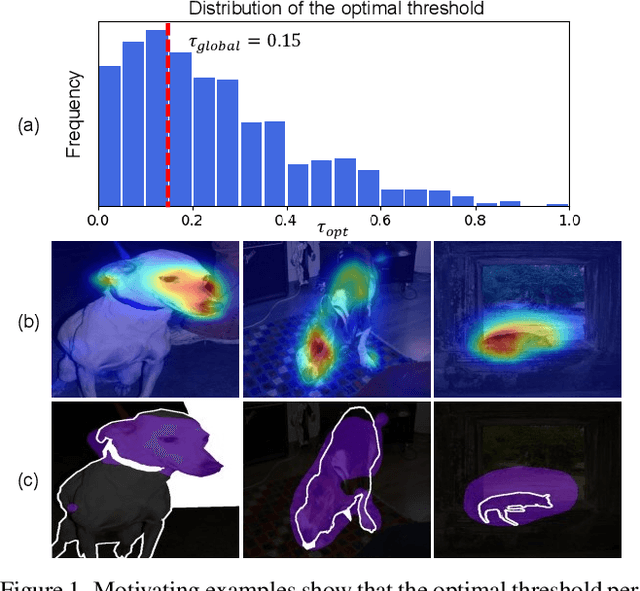

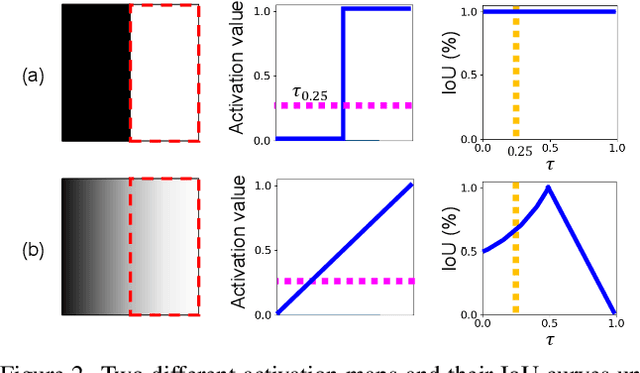
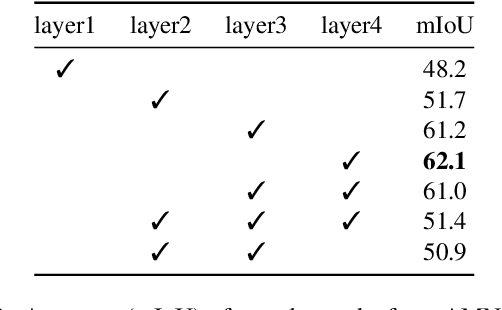
Weakly-supervised semantic segmentation (WSSS) has recently gained much attention for its promise to train segmentation models only with image-level labels. Existing WSSS methods commonly argue that the sparse coverage of CAM incurs the performance bottleneck of WSSS. This paper provides analytical and empirical evidence that the actual bottleneck may not be sparse coverage but a global thresholding scheme applied after CAM. Then, we show that this issue can be mitigated by satisfying two conditions; 1) reducing the imbalance in the foreground activation and 2) increasing the gap between the foreground and the background activation. Based on these findings, we propose a novel activation manipulation network with a per-pixel classification loss and a label conditioning module. Per-pixel classification naturally induces two-level activation in activation maps, which can penalize the most discriminative parts, promote the less discriminative parts, and deactivate the background regions. Label conditioning imposes that the output label of pseudo-masks should be any of true image-level labels; it penalizes the wrong activation assigned to non-target classes. Based on extensive analysis and evaluations, we demonstrate that each component helps produce accurate pseudo-masks, achieving the robustness against the choice of the global threshold. Finally, our model achieves state-of-the-art records on both PASCAL VOC 2012 and MS COCO 2014 datasets.
Railroad is not a Train: Saliency as Pseudo-pixel Supervision for Weakly Supervised Semantic Segmentation
May 19, 2021
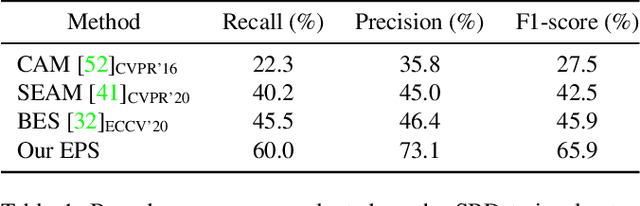
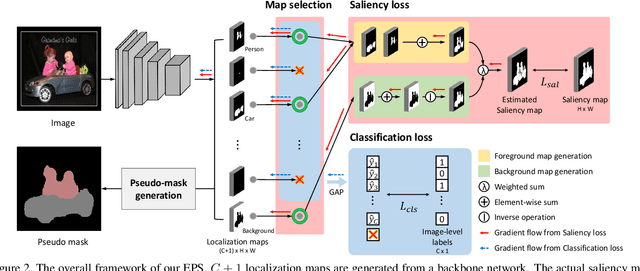
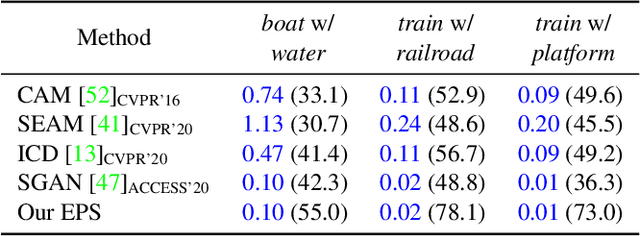
Existing studies in weakly-supervised semantic segmentation (WSSS) using image-level weak supervision have several limitations: sparse object coverage, inaccurate object boundaries, and co-occurring pixels from non-target objects. To overcome these challenges, we propose a novel framework, namely Explicit Pseudo-pixel Supervision (EPS), which learns from pixel-level feedback by combining two weak supervisions; the image-level label provides the object identity via the localization map and the saliency map from the off-the-shelf saliency detection model offers rich boundaries. We devise a joint training strategy to fully utilize the complementary relationship between both information. Our method can obtain accurate object boundaries and discard co-occurring pixels, thereby significantly improving the quality of pseudo-masks. Experimental results show that the proposed method remarkably outperforms existing methods by resolving key challenges of WSSS and achieves the new state-of-the-art performance on both PASCAL VOC 2012 and MS COCO 2014 datasets.