 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeRec: Model Merging for Data-Isolated Cross-Domain Sequential Recommendation
Jan 05, 2026Modern recommender systems trained on domain-specific data often struggle to generalize across multiple domains. Cross-domain sequential recommendation has emerged as a promising research direction to address this challenge; however, existing approaches face fundamental limitations, such as reliance on overlapping users or items across domains, or unrealistic assumptions that ignore privacy constraints. In this work, we propose a new framework, MergeRec, based on model merging under a new and realistic problem setting termed data-isolated cross-domain sequential recommendation, where raw user interaction data cannot be shared across domains. MergeRec consists of three key components: (1) merging initialization, (2) pseudo-user data construction, and (3) collaborative merging optimization. First, we initialize a merged model using training-free merging techniques. Next, we construct pseudo-user data by treating each item as a virtual sequence in each domain, enabling the synthesis of meaningful training samples without relying on real user interactions. Finally, we optimize domain-specific merging weights through a joint objective that combines a recommendation loss, which encourages the merged model to identify relevant items, and a distillation loss, which transfers collaborative filtering signals from the fine-tuned source models. Extensive experiments demonstrate that MergeRec not only preserves the strengths of the original models but also significantly enhances generalizability to unseen domains. Compared to conventional model merging methods, MergeRec consistently achieves superior performance, with average improvements of up to 17.21% in Recall@10, highlighting the potential of model merging as a scalable and effective approach for building universal recommender systems. The source code is available at https://github.com/DIALLab-SKKU/MergeRec.
Enhancing Time Awareness in Generative Recommendation
Sep 17, 2025Generative recommendation has emerged as a promising paradigm that formulates the recommendations into a text-to-text generation task, harnessing the vast knowledge of large language models. However, existing studies focus on considering the sequential order of items and neglect to handle the temporal dynamics across items, which can imply evolving user preferences. To address this limitation, we propose a novel model, Generative Recommender Using Time awareness (GRUT), effectively capturing hidden user preferences via various temporal signals. We first introduce Time-aware Prompting, consisting of two key contexts. The user-level temporal context models personalized temporal patterns across timestamps and time intervals, while the item-level transition context provides transition patterns across users. We also devise Trend-aware Inference, a training-free method that enhances rankings by incorporating trend information about items with generation likelihood. Extensive experiments demonstrate that GRUT outperforms state-of-the-art models, with gains of up to 15.4% and 14.3% in Recall@5 and NDCG@5 across four benchmark datasets. The source code is available at https://github.com/skleee/GRUT.
Multi-view-guided Passage Reranking with Large Language Models
Sep 09, 2025Recent advances in large language models (LLMs) have shown impressive performance in passage reranking tasks. Despite their success, LLM-based methods still face challenges in efficiency and sensitivity to external biases. (1) Existing models rely mostly on autoregressive generation and sliding window strategies to rank passages, which incur heavy computational overhead as the number of passages increases. (2) External biases, such as position or selection bias, hinder the model's ability to accurately represent passages and increase input-order sensitivity. To address these limitations, we introduce a novel passage reranking model, called Multi-View-guided Passage Reranking (MVP). MVP is a non-generative LLM-based reranking method that encodes query-passage information into diverse view embeddings without being influenced by external biases. For each view, it combines query-aware passage embeddings to produce a distinct anchor vector, which is then used to directly compute relevance scores in a single decoding step. In addition, it employs an orthogonal loss to make the views more distinctive. Extensive experiments demonstrate that MVP, with just 220M parameters, matches the performance of much larger 7B-scale fine-tuned models while achieving a 100x reduction in inference latency. Notably, the 3B-parameter variant of MVP achieves state-of-the-art performance on both in-domain and out-of-domain benchmarks. The source code is available at: https://github.com/bulbna/MVP
DIFF: Dual Side-Information Filtering and Fusion for Sequential Recommendation
May 20, 2025Side-information Integrated Sequential Recommendation (SISR) benefits from auxiliary item information to infer hidden user preferences, which is particularly effective for sparse interactions and cold-start scenarios. However, existing studies face two main challenges. (i) They fail to remove noisy signals in item sequence and (ii) they underutilize the potential of side-information integration. To tackle these issues, we propose a novel SISR model, Dual Side-Information Filtering and Fusion (DIFF), which employs frequency-based noise filtering and dual multi-sequence fusion. Specifically, we convert the item sequence to the frequency domain to filter out noisy short-term fluctuations in user interests. We then combine early and intermediate fusion to capture diverse relationships across item IDs and attributes. Thanks to our innovative filtering and fusion strategy, DIFF is more robust in learning subtle and complex item correlations in the sequence. DIFF outperforms state-of-the-art SISR models, achieving improvements of up to 14.1% and 12.5% in Recall@20 and NDCG@20 across four benchmark datasets.
Linear Item-Item Model with Neural Knowledge for Session-based Recommendation
Apr 21, 2025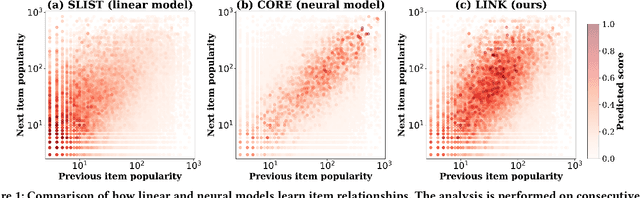
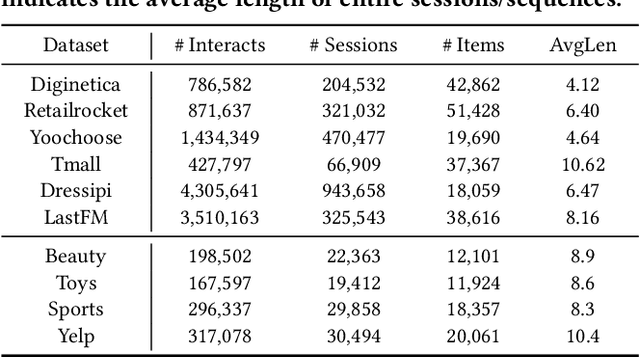
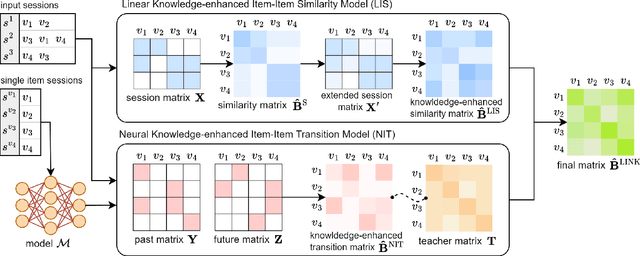
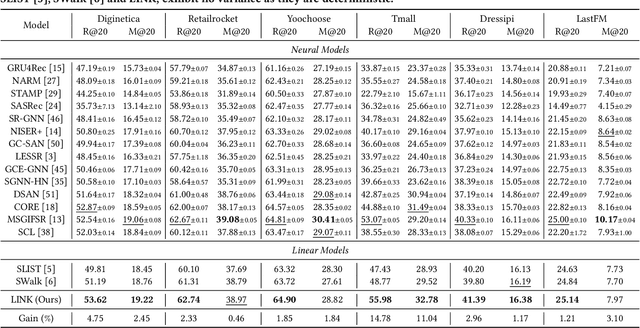
Session-based recommendation (SBR) aims to predict users' subsequent actions by modeling short-term interactions within sessions. Existing neural models primarily focus on capturing complex dependencies for sequential item transitions. As an alternative solution, linear item-item models mainly identify strong co-occurrence patterns across items and support faster inference speed. Although each paradigm has been actively studied in SBR, their fundamental differences in capturing item relationships and how to bridge these distinct modeling paradigms effectively remain unexplored. In this paper, we propose a novel SBR model, namely Linear Item-Item model with Neural Knowledge (LINK), which integrates both types of knowledge into a unified linear framework. Specifically, we design two specialized components of LINK: (i) Linear knowledge-enhanced Item-item Similarity model (LIS), which refines the item similarity correlation via self-distillation, and (ii) Neural knowledge-enhanced Item-item Transition model (NIT), which seamlessly incorporates complicated neural knowledge distilled from the off-the-shelf neural model. Extensive experiments demonstrate that LINK outperforms state-of-the-art linear SBR models across six real-world datasets, achieving improvements of up to 14.78% and 11.04% in Recall@20 and MRR@20 while showing up to 813x fewer inference FLOPs. Our code is available at https://github.com/jin530/LINK.
Why is Normalization Necessary for Linear Recommenders?
Apr 08, 2025Despite their simplicity, linear autoencoder (LAE)-based models have shown comparable or even better performance with faster inference speed than neural recommender models. However, LAEs face two critical challenges: (i) popularity bias, which tends to recommend popular items, and (ii) neighborhood bias, which overly focuses on capturing local item correlations. To address these issues, this paper first analyzes the effect of two existing normalization methods for LAEs, i.e., random-walk and symmetric normalization. Our theoretical analysis reveals that normalization highly affects the degree of popularity and neighborhood biases among items. Inspired by this analysis, we propose a versatile normalization solution, called Data-Adaptive Normalization (DAN), which flexibly controls the popularity and neighborhood biases by adjusting item- and user-side normalization to align with unique dataset characteristics. Owing to its model-agnostic property, DAN can be easily applied to various LAE-based models. Experimental results show that DAN-equipped LAEs consistently improve existing LAE-based models across six benchmark datasets, with significant gains of up to 128.57% and 12.36% for long-tail items and unbiased evaluations, respectively. Refer to our code in https://github.com/psm1206/DAN.
Empowering Retrieval-based Conversational Recommendation with Contrasting User Preferences
Mar 27, 2025



Conversational recommender systems (CRSs) are designed to suggest the target item that the user is likely to prefer through multi-turn conversations. Recent studies stress that capturing sentiments in user conversations improves recommendation accuracy. However, they employ a single user representation, which may fail to distinguish between contrasting user intentions, such as likes and dislikes, potentially leading to suboptimal performance. To this end, we propose a novel conversational recommender model, called COntrasting user pReference expAnsion and Learning (CORAL). Firstly, CORAL extracts the user's hidden preferences through contrasting preference expansion using the reasoning capacity of the LLMs. Based on the potential preference, CORAL explicitly differentiates the contrasting preferences and leverages them into the recommendation process via preference-aware learning. Extensive experiments show that CORAL significantly outperforms existing methods in three benchmark datasets, improving up to 99.72% in Recall@10. The code and datasets are available at https://github.com/kookeej/CORAL
Temporal Linear Item-Item Model for Sequential Recommendation
Dec 10, 2024



In sequential recommendation (SR), neural models have been actively explored due to their remarkable performance, but they suffer from inefficiency inherent to their complexity. On the other hand, linear SR models exhibit high efficiency and achieve competitive or superior accuracy compared to neural models. However, they solely deal with the sequential order of items (i.e., sequential information) and overlook the actual timestamp (i.e., temporal information). It is limited to effectively capturing various user preference drifts over time. To address this issue, we propose a novel linear SR model, named TemporAl LinEar item-item model (TALE), incorporating temporal information while preserving training/inference efficiency, with three key components. (i) Single-target augmentation concentrates on a single target item, enabling us to learn the temporal correlation for the target item. (ii) Time interval-aware weighting utilizes the actual timestamp to discern the item correlation depending on time intervals. (iii) Trend-aware normalization reflects the dynamic shift of item popularity over time. Our empirical studies show that TALE outperforms ten competing SR models by up to 18.71% gains on five benchmark datasets. It also exhibits remarkable effectiveness in evaluating long-tail items by up to 30.45% gains. The source code is available at https://github.com/psm1206/TALE.
From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression
Oct 05, 2024



Large language models (LLMs) have achieved significant performance gains using advanced prompting techniques over various tasks. However, the increasing length of prompts leads to high computational costs and often obscures crucial information. Prompt compression has been proposed to alleviate these issues, but it faces challenges in (i) capturing the global context and (ii) training the compressor effectively. To tackle these challenges, we introduce a novel prompt compression method, namely Reading To Compressing (R2C), utilizing the Fusion-in-Decoder (FiD) architecture to identify the important information in the prompt. Specifically, the cross-attention scores of the FiD are used to discern essential chunks and sentences from the prompt. R2C effectively captures the global context without compromising semantic consistency while detouring the necessity of pseudo-labels for training the compressor. Empirical results show that R2C retains key contexts, enhancing the LLM performance by 6% in out-of-domain evaluations while reducing the prompt length by 80%.
MARS: Matching Attribute-aware Representations for Text-based Sequential Recommendation
Sep 04, 2024Sequential recommendation aims to predict the next item a user is likely to prefer based on their sequential interaction history. Recently, text-based sequential recommendation has emerged as a promising paradigm that uses pre-trained language models to exploit textual item features to enhance performance and facilitate knowledge transfer to unseen datasets. However, existing text-based recommender models still struggle with two key challenges: (i) representing users and items with multiple attributes, and (ii) matching items with complex user interests. To address these challenges, we propose a novel model, Matching Attribute-aware Representations for Text-based Sequential Recommendation (MARS). MARS extracts detailed user and item representations through attribute-aware text encoding, capturing diverse user intents with multiple attribute-aware representations. It then computes user-item scores via attribute-wise interaction matching, effectively capturing attribute-level user preferences. Our extensive experiments demonstrate that MARS significantly outperforms existing sequential models, achieving improvements of up to 24.43% and 29.26% in Recall@10 and NDCG@10 across five benchmark datasets. Code is available at https://github.com/junieberry/MARS