 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyped-RAG: Type-aware Multi-Aspect Decomposition for Non-Factoid Question Answering
Mar 21, 2025



Non-factoid question-answering (NFQA) poses a significant challenge due to its open-ended nature, diverse intents, and the need for multi-aspect reasoning, which renders conventional factoid QA approaches, including retrieval-augmented generation (RAG), inadequate. Unlike factoid questions, non-factoid questions (NFQs) lack definitive answers and require synthesizing information from multiple sources across various reasoning dimensions. To address these limitations, we introduce Typed-RAG, a type-aware multi-aspect decomposition framework within the RAG paradigm for NFQA. Typed-RAG classifies NFQs into distinct types -- such as debate, experience, and comparison -- and applies aspect-based decomposition to refine retrieval and generation strategies. By decomposing multi-aspect NFQs into single-aspect sub-queries and aggregating the results, Typed-RAG generates more informative and contextually relevant responses. To evaluate Typed-RAG, we introduce Wiki-NFQA, a benchmark dataset covering diverse NFQ types. Experimental results demonstrate that Typed-RAG outperforms baselines, thereby highlighting the importance of type-aware decomposition for effective retrieval and generation in NFQA. Our code and dataset are available at https://github.com/TeamNLP/Typed-RAG.
Multi-Granularity Guided Fusion-in-Decoder
Apr 03, 2024
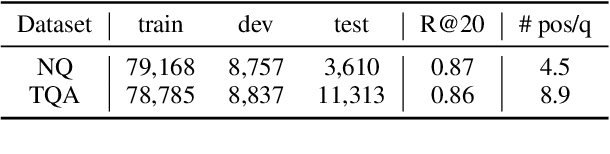
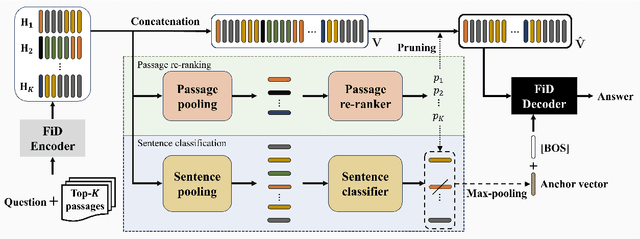
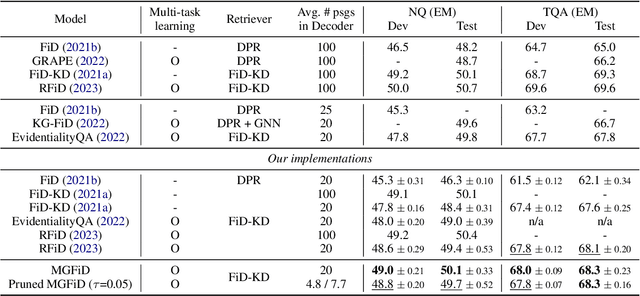
In Open-domain Question Answering (ODQA), it is essential to discern relevant contexts as evidence and avoid spurious ones among retrieved results. The model architecture that uses concatenated multiple contexts in the decoding phase, i.e., Fusion-in-Decoder, demonstrates promising performance but generates incorrect outputs from seemingly plausible contexts. To address this problem, we propose the Multi-Granularity guided Fusion-in-Decoder (MGFiD), discerning evidence across multiple levels of granularity. Based on multi-task learning, MGFiD harmonizes passage re-ranking with sentence classification. It aggregates evident sentences into an anchor vector that instructs the decoder. Additionally, it improves decoding efficiency by reusing the results of passage re-ranking for passage pruning. Through our experiments, MGFiD outperforms existing models on the Natural Questions (NQ) and TriviaQA (TQA) datasets, highlighting the benefits of its multi-granularity solution.