 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view-guided Passage Reranking with Large Language Models
Sep 09, 2025Recent advances in large language models (LLMs) have shown impressive performance in passage reranking tasks. Despite their success, LLM-based methods still face challenges in efficiency and sensitivity to external biases. (1) Existing models rely mostly on autoregressive generation and sliding window strategies to rank passages, which incur heavy computational overhead as the number of passages increases. (2) External biases, such as position or selection bias, hinder the model's ability to accurately represent passages and increase input-order sensitivity. To address these limitations, we introduce a novel passage reranking model, called Multi-View-guided Passage Reranking (MVP). MVP is a non-generative LLM-based reranking method that encodes query-passage information into diverse view embeddings without being influenced by external biases. For each view, it combines query-aware passage embeddings to produce a distinct anchor vector, which is then used to directly compute relevance scores in a single decoding step. In addition, it employs an orthogonal loss to make the views more distinctive. Extensive experiments demonstrate that MVP, with just 220M parameters, matches the performance of much larger 7B-scale fine-tuned models while achieving a 100x reduction in inference latency. Notably, the 3B-parameter variant of MVP achieves state-of-the-art performance on both in-domain and out-of-domain benchmarks. The source code is available at: https://github.com/bulbna/MVP
From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression
Oct 05, 2024



Large language models (LLMs) have achieved significant performance gains using advanced prompting techniques over various tasks. However, the increasing length of prompts leads to high computational costs and often obscures crucial information. Prompt compression has been proposed to alleviate these issues, but it faces challenges in (i) capturing the global context and (ii) training the compressor effectively. To tackle these challenges, we introduce a novel prompt compression method, namely Reading To Compressing (R2C), utilizing the Fusion-in-Decoder (FiD) architecture to identify the important information in the prompt. Specifically, the cross-attention scores of the FiD are used to discern essential chunks and sentences from the prompt. R2C effectively captures the global context without compromising semantic consistency while detouring the necessity of pseudo-labels for training the compressor. Empirical results show that R2C retains key contexts, enhancing the LLM performance by 6% in out-of-domain evaluations while reducing the prompt length by 80%.
Multi-Granularity Guided Fusion-in-Decoder
Apr 03, 2024
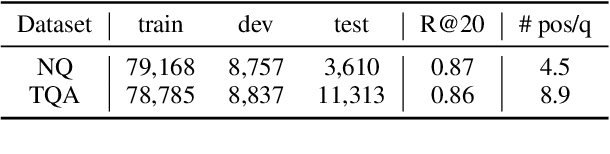
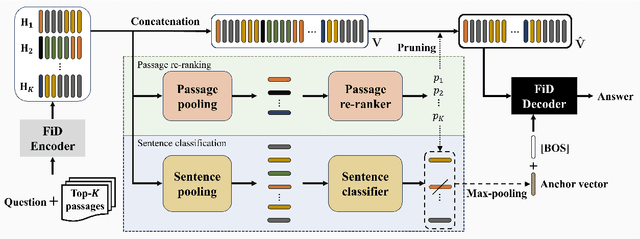
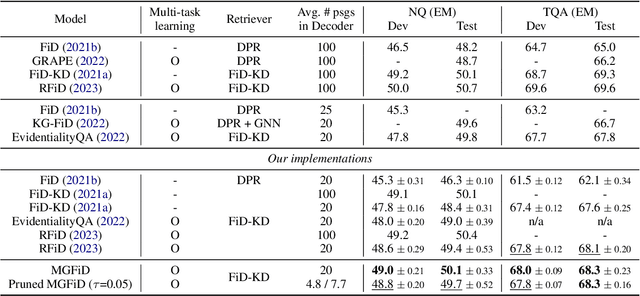
In Open-domain Question Answering (ODQA), it is essential to discern relevant contexts as evidence and avoid spurious ones among retrieved results. The model architecture that uses concatenated multiple contexts in the decoding phase, i.e., Fusion-in-Decoder, demonstrates promising performance but generates incorrect outputs from seemingly plausible contexts. To address this problem, we propose the Multi-Granularity guided Fusion-in-Decoder (MGFiD), discerning evidence across multiple levels of granularity. Based on multi-task learning, MGFiD harmonizes passage re-ranking with sentence classification. It aggregates evident sentences into an anchor vector that instructs the decoder. Additionally, it improves decoding efficiency by reusing the results of passage re-ranking for passage pruning. Through our experiments, MGFiD outperforms existing models on the Natural Questions (NQ) and TriviaQA (TQA) datasets, highlighting the benefits of its multi-granularity solution.
Forgetting-aware Linear Bias for Attentive Knowledge Tracing
Sep 26, 2023Knowledge Tracing (KT) aims to track proficiency based on a question-solving history, allowing us to offer a streamlined curriculum. Recent studies actively utilize attention-based mechanisms to capture the correlation between questions and combine it with the learner's characteristics for responses. However, our empirical study shows that existing attention-based KT models neglect the learner's forgetting behavior, especially as the interaction history becomes longer. This problem arises from the bias that overprioritizes the correlation of questions while inadvertently ignoring the impact of forgetting behavior. This paper proposes a simple-yet-effective solution, namely Forgetting-aware Linear Bias (FoLiBi), to reflect forgetting behavior as a linear bias. Despite its simplicity, FoLiBi is readily equipped with existing attentive KT models by effectively decomposing question correlations with forgetting behavior. FoLiBi plugged with several KT models yields a consistent improvement of up to 2.58% in AUC over state-of-the-art KT models on four benchmark datasets.
ConQueR: Contextualized Query Reduction using Search Logs
May 22, 2023



Query reformulation is a key mechanism to alleviate the linguistic chasm of query in ad-hoc retrieval. Among various solutions, query reduction effectively removes extraneous terms and specifies concise user intent from long queries. However, it is challenging to capture hidden and diverse user intent. This paper proposes Contextualized Query Reduction (ConQueR) using a pre-trained language model (PLM). Specifically, it reduces verbose queries with two different views: core term extraction and sub-query selection. One extracts core terms from an original query at the term level, and the other determines whether a sub-query is a suitable reduction for the original query at the sequence level. Since they operate at different levels of granularity and complement each other, they are finally aggregated in an ensemble manner. We evaluate the reduction quality of ConQueR on real-world search logs collected from a commercial web search engine. It achieves up to 8.45% gains in exact match scores over the best competing model.
SpaDE: Improving Sparse Representations using a Dual Document Encoder for First-stage Retrieval
Sep 13, 2022
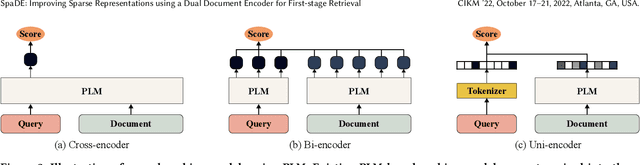
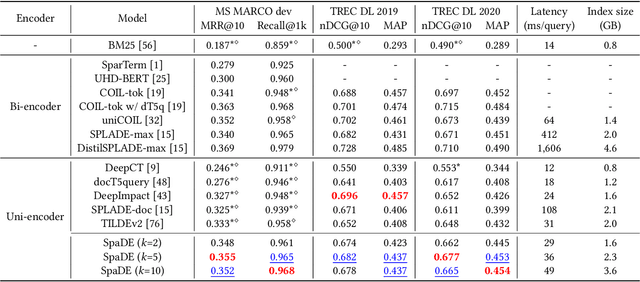
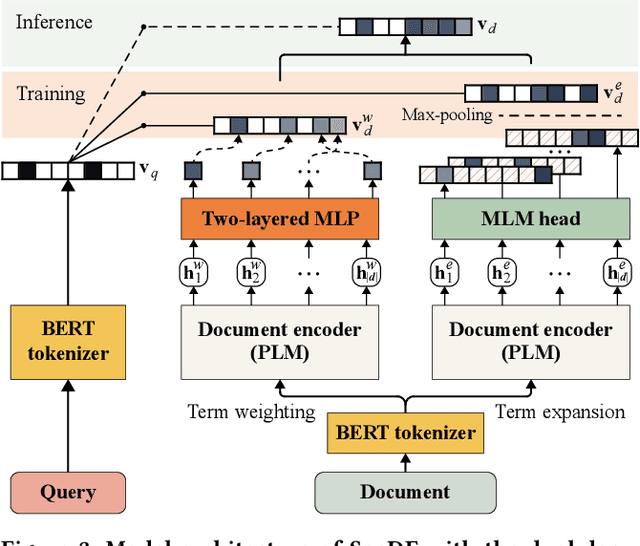
Sparse document representations have been widely used to retrieve relevant documents via exact lexical matching. Owing to the pre-computed inverted index, it supports fast ad-hoc search but incurs the vocabulary mismatch problem. Although recent neural ranking models using pre-trained language models can address this problem, they usually require expensive query inference costs, implying the trade-off between effectiveness and efficiency. Tackling the trade-off, we propose a novel uni-encoder ranking model, Sparse retriever using a Dual document Encoder (SpaDE), learning document representation via the dual encoder. Each encoder plays a central role in (i) adjusting the importance of terms to improve lexical matching and (ii) expanding additional terms to support semantic matching. Furthermore, our co-training strategy trains the dual encoder effectively and avoids unnecessary intervention in training each other. Experimental results on several benchmarks show that SpaDE outperforms existing uni-encoder ranking models.
MelBERT: Metaphor Detection via Contextualized Late Interaction using Metaphorical Identification Theories
Apr 28, 2021



Automated metaphor detection is a challenging task to identify metaphorical expressions of words in a sentence. To tackle this problem, we adopt pre-trained contextualized models, e.g., BERT and RoBERTa. To this end, we propose a novel metaphor detection model, namely metaphor-aware late interaction over BERT (MelBERT). Our model not only leverages contextualized word representation but also benefits from linguistic metaphor identification theories to distinguish between the contextual and literal meaning of words. Our empirical results demonstrate that MelBERT outperforms several strong baselines on four benchmark datasets, i.e., VUA-18, VUA-20, MOH-X, and TroFi.