 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlans for Evaluating Structured Generative Search Summaries
May 26, 2026We propose a framework for evaluating structured generative search summaries that are placed atop organic web search results. A structured summary, generated by a large language model, typically consists of an overview, several sections with section titles, and a list of source documents that are cited within the summary. We then describe our plans for implementing and evaluating the framework.
Relevance to Utility: Process-Supervised Rewrite for RAG
Sep 19, 2025Retrieval-Augmented Generation systems often suffer from a gap between optimizing retrieval relevance and generative utility: retrieved documents may be topically relevant but still lack the content needed for effective reasoning during generation. While existing "bridge" modules attempt to rewrite the retrieved text for better generation, we show how they fail to capture true document utility. In this work, we propose R2U, with a key distinction of directly optimizing to maximize the probability of generating a correct answer through process supervision. As such direct observation is expensive, we also propose approximating an efficient distillation pipeline by scaling the supervision from LLMs, which helps the smaller rewriter model generalize better. We evaluate our method across multiple open-domain question-answering benchmarks. The empirical results demonstrate consistent improvements over strong bridging baselines.
ConQueR: Contextualized Query Reduction using Search Logs
May 22, 2023



Query reformulation is a key mechanism to alleviate the linguistic chasm of query in ad-hoc retrieval. Among various solutions, query reduction effectively removes extraneous terms and specifies concise user intent from long queries. However, it is challenging to capture hidden and diverse user intent. This paper proposes Contextualized Query Reduction (ConQueR) using a pre-trained language model (PLM). Specifically, it reduces verbose queries with two different views: core term extraction and sub-query selection. One extracts core terms from an original query at the term level, and the other determines whether a sub-query is a suitable reduction for the original query at the sequence level. Since they operate at different levels of granularity and complement each other, they are finally aggregated in an ensemble manner. We evaluate the reduction quality of ConQueR on real-world search logs collected from a commercial web search engine. It achieves up to 8.45% gains in exact match scores over the best competing model.
SpaDE: Improving Sparse Representations using a Dual Document Encoder for First-stage Retrieval
Sep 13, 2022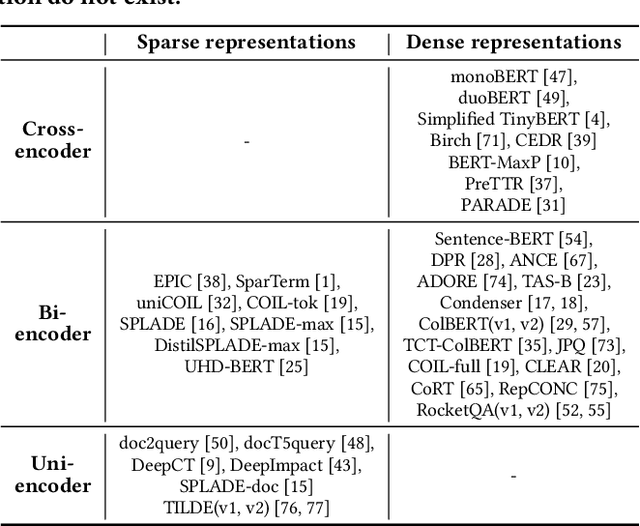
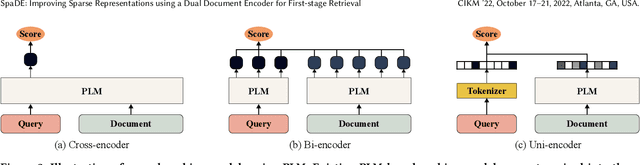
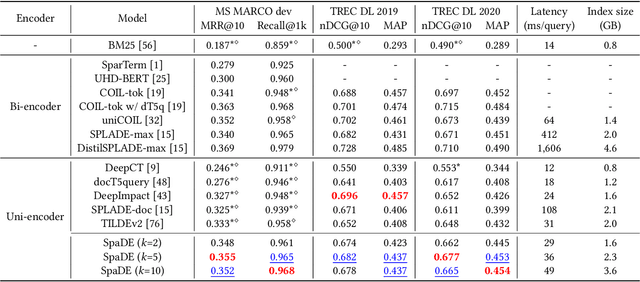
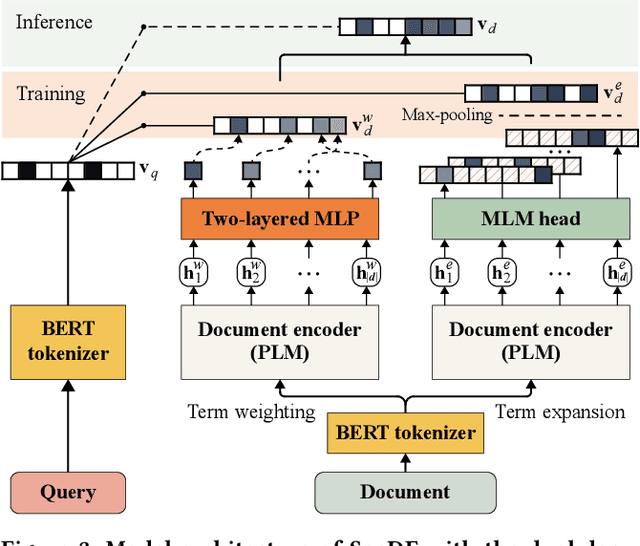
Sparse document representations have been widely used to retrieve relevant documents via exact lexical matching. Owing to the pre-computed inverted index, it supports fast ad-hoc search but incurs the vocabulary mismatch problem. Although recent neural ranking models using pre-trained language models can address this problem, they usually require expensive query inference costs, implying the trade-off between effectiveness and efficiency. Tackling the trade-off, we propose a novel uni-encoder ranking model, Sparse retriever using a Dual document Encoder (SpaDE), learning document representation via the dual encoder. Each encoder plays a central role in (i) adjusting the importance of terms to improve lexical matching and (ii) expanding additional terms to support semantic matching. Furthermore, our co-training strategy trains the dual encoder effectively and avoids unnecessary intervention in training each other. Experimental results on several benchmarks show that SpaDE outperforms existing uni-encoder ranking models.