 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Time Awareness in Generative Recommendation
Sep 17, 2025Generative recommendation has emerged as a promising paradigm that formulates the recommendations into a text-to-text generation task, harnessing the vast knowledge of large language models. However, existing studies focus on considering the sequential order of items and neglect to handle the temporal dynamics across items, which can imply evolving user preferences. To address this limitation, we propose a novel model, Generative Recommender Using Time awareness (GRUT), effectively capturing hidden user preferences via various temporal signals. We first introduce Time-aware Prompting, consisting of two key contexts. The user-level temporal context models personalized temporal patterns across timestamps and time intervals, while the item-level transition context provides transition patterns across users. We also devise Trend-aware Inference, a training-free method that enhances rankings by incorporating trend information about items with generation likelihood. Extensive experiments demonstrate that GRUT outperforms state-of-the-art models, with gains of up to 15.4% and 14.3% in Recall@5 and NDCG@5 across four benchmark datasets. The source code is available at https://github.com/skleee/GRUT.
DIFF: Dual Side-Information Filtering and Fusion for Sequential Recommendation
May 20, 2025Side-information Integrated Sequential Recommendation (SISR) benefits from auxiliary item information to infer hidden user preferences, which is particularly effective for sparse interactions and cold-start scenarios. However, existing studies face two main challenges. (i) They fail to remove noisy signals in item sequence and (ii) they underutilize the potential of side-information integration. To tackle these issues, we propose a novel SISR model, Dual Side-Information Filtering and Fusion (DIFF), which employs frequency-based noise filtering and dual multi-sequence fusion. Specifically, we convert the item sequence to the frequency domain to filter out noisy short-term fluctuations in user interests. We then combine early and intermediate fusion to capture diverse relationships across item IDs and attributes. Thanks to our innovative filtering and fusion strategy, DIFF is more robust in learning subtle and complex item correlations in the sequence. DIFF outperforms state-of-the-art SISR models, achieving improvements of up to 14.1% and 12.5% in Recall@20 and NDCG@20 across four benchmark datasets.
Linear Item-Item Model with Neural Knowledge for Session-based Recommendation
Apr 21, 2025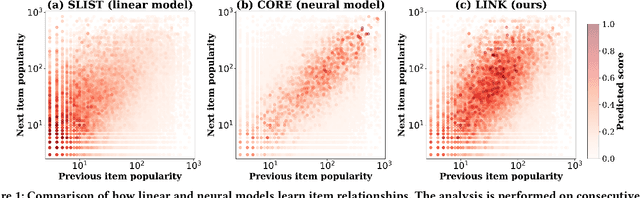
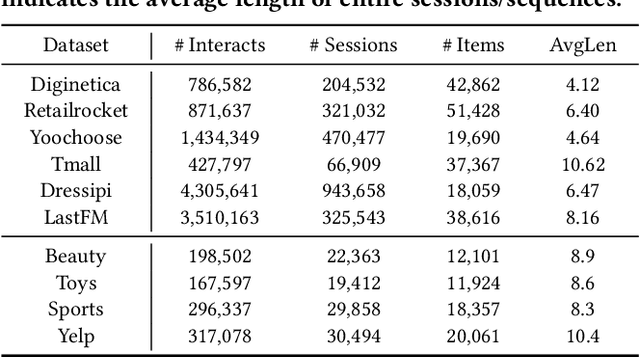
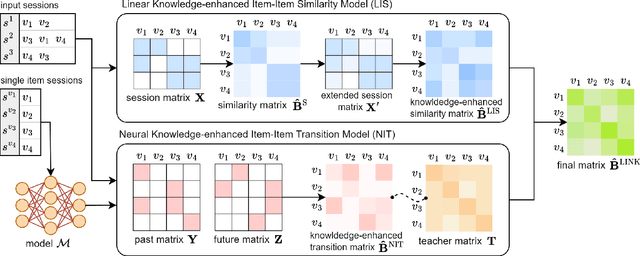
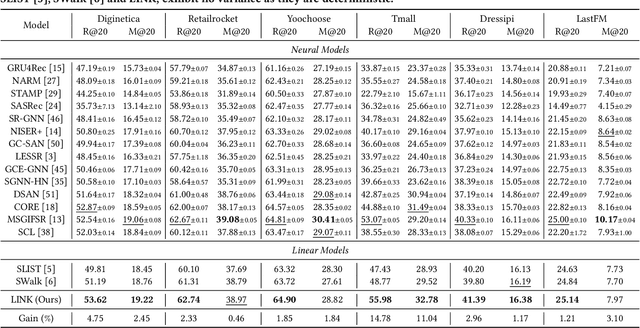
Session-based recommendation (SBR) aims to predict users' subsequent actions by modeling short-term interactions within sessions. Existing neural models primarily focus on capturing complex dependencies for sequential item transitions. As an alternative solution, linear item-item models mainly identify strong co-occurrence patterns across items and support faster inference speed. Although each paradigm has been actively studied in SBR, their fundamental differences in capturing item relationships and how to bridge these distinct modeling paradigms effectively remain unexplored. In this paper, we propose a novel SBR model, namely Linear Item-Item model with Neural Knowledge (LINK), which integrates both types of knowledge into a unified linear framework. Specifically, we design two specialized components of LINK: (i) Linear knowledge-enhanced Item-item Similarity model (LIS), which refines the item similarity correlation via self-distillation, and (ii) Neural knowledge-enhanced Item-item Transition model (NIT), which seamlessly incorporates complicated neural knowledge distilled from the off-the-shelf neural model. Extensive experiments demonstrate that LINK outperforms state-of-the-art linear SBR models across six real-world datasets, achieving improvements of up to 14.78% and 11.04% in Recall@20 and MRR@20 while showing up to 813x fewer inference FLOPs. Our code is available at https://github.com/jin530/LINK.
From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression
Oct 05, 2024



Large language models (LLMs) have achieved significant performance gains using advanced prompting techniques over various tasks. However, the increasing length of prompts leads to high computational costs and often obscures crucial information. Prompt compression has been proposed to alleviate these issues, but it faces challenges in (i) capturing the global context and (ii) training the compressor effectively. To tackle these challenges, we introduce a novel prompt compression method, namely Reading To Compressing (R2C), utilizing the Fusion-in-Decoder (FiD) architecture to identify the important information in the prompt. Specifically, the cross-attention scores of the FiD are used to discern essential chunks and sentences from the prompt. R2C effectively captures the global context without compromising semantic consistency while detouring the necessity of pseudo-labels for training the compressor. Empirical results show that R2C retains key contexts, enhancing the LLM performance by 6% in out-of-domain evaluations while reducing the prompt length by 80%.
MARS: Matching Attribute-aware Representations for Text-based Sequential Recommendation
Sep 04, 2024Sequential recommendation aims to predict the next item a user is likely to prefer based on their sequential interaction history. Recently, text-based sequential recommendation has emerged as a promising paradigm that uses pre-trained language models to exploit textual item features to enhance performance and facilitate knowledge transfer to unseen datasets. However, existing text-based recommender models still struggle with two key challenges: (i) representing users and items with multiple attributes, and (ii) matching items with complex user interests. To address these challenges, we propose a novel model, Matching Attribute-aware Representations for Text-based Sequential Recommendation (MARS). MARS extracts detailed user and item representations through attribute-aware text encoding, capturing diverse user intents with multiple attribute-aware representations. It then computes user-item scores via attribute-wise interaction matching, effectively capturing attribute-level user preferences. Our extensive experiments demonstrate that MARS significantly outperforms existing sequential models, achieving improvements of up to 24.43% and 29.26% in Recall@10 and NDCG@10 across five benchmark datasets. Code is available at https://github.com/junieberry/MARS
GLEN: Generative Retrieval via Lexical Index Learning
Nov 06, 2023



Generative retrieval shed light on a new paradigm of document retrieval, aiming to directly generate the identifier of a relevant document for a query. While it takes advantage of bypassing the construction of auxiliary index structures, existing studies face two significant challenges: (i) the discrepancy between the knowledge of pre-trained language models and identifiers and (ii) the gap between training and inference that poses difficulty in learning to rank. To overcome these challenges, we propose a novel generative retrieval method, namely Generative retrieval via LExical iNdex learning (GLEN). For training, GLEN effectively exploits a dynamic lexical identifier using a two-phase index learning strategy, enabling it to learn meaningful lexical identifiers and relevance signals between queries and documents. For inference, GLEN utilizes collision-free inference, using identifier weights to rank documents without additional overhead. Experimental results prove that GLEN achieves state-of-the-art or competitive performance against existing generative retrieval methods on various benchmark datasets, e.g., NQ320k, MS MARCO, and BEIR. The code is available at https://github.com/skleee/GLEN.
ConQueR: Contextualized Query Reduction using Search Logs
May 22, 2023



Query reformulation is a key mechanism to alleviate the linguistic chasm of query in ad-hoc retrieval. Among various solutions, query reduction effectively removes extraneous terms and specifies concise user intent from long queries. However, it is challenging to capture hidden and diverse user intent. This paper proposes Contextualized Query Reduction (ConQueR) using a pre-trained language model (PLM). Specifically, it reduces verbose queries with two different views: core term extraction and sub-query selection. One extracts core terms from an original query at the term level, and the other determines whether a sub-query is a suitable reduction for the original query at the sequence level. Since they operate at different levels of granularity and complement each other, they are finally aggregated in an ensemble manner. We evaluate the reduction quality of ConQueR on real-world search logs collected from a commercial web search engine. It achieves up to 8.45% gains in exact match scores over the best competing model.
SpaDE: Improving Sparse Representations using a Dual Document Encoder for First-stage Retrieval
Sep 13, 2022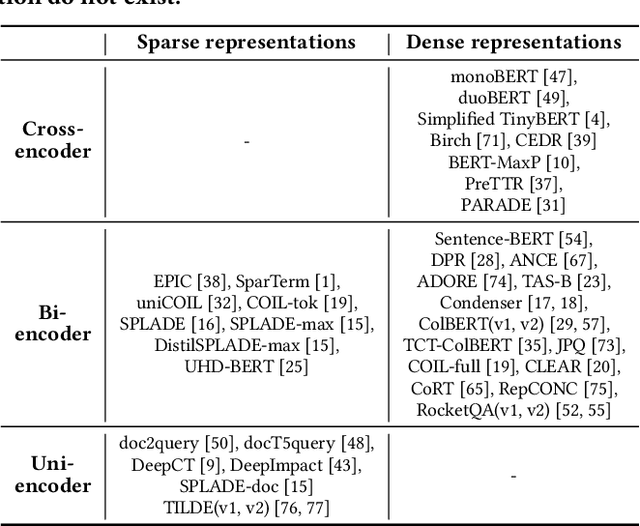
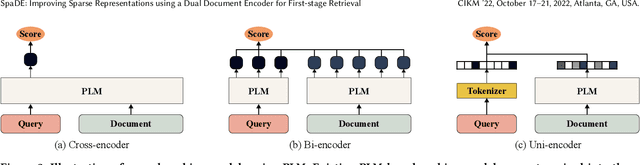
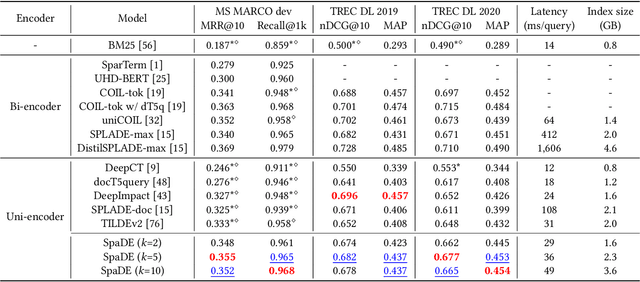
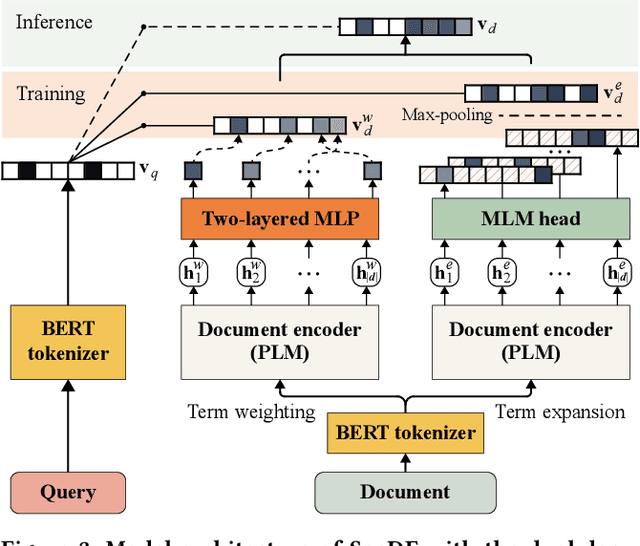
Sparse document representations have been widely used to retrieve relevant documents via exact lexical matching. Owing to the pre-computed inverted index, it supports fast ad-hoc search but incurs the vocabulary mismatch problem. Although recent neural ranking models using pre-trained language models can address this problem, they usually require expensive query inference costs, implying the trade-off between effectiveness and efficiency. Tackling the trade-off, we propose a novel uni-encoder ranking model, Sparse retriever using a Dual document Encoder (SpaDE), learning document representation via the dual encoder. Each encoder plays a central role in (i) adjusting the importance of terms to improve lexical matching and (ii) expanding additional terms to support semantic matching. Furthermore, our co-training strategy trains the dual encoder effectively and avoids unnecessary intervention in training each other. Experimental results on several benchmarks show that SpaDE outperforms existing uni-encoder ranking models.
MelBERT: Metaphor Detection via Contextualized Late Interaction using Metaphorical Identification Theories
Apr 28, 2021



Automated metaphor detection is a challenging task to identify metaphorical expressions of words in a sentence. To tackle this problem, we adopt pre-trained contextualized models, e.g., BERT and RoBERTa. To this end, we propose a novel metaphor detection model, namely metaphor-aware late interaction over BERT (MelBERT). Our model not only leverages contextualized word representation but also benefits from linguistic metaphor identification theories to distinguish between the contextual and literal meaning of words. Our empirical results demonstrate that MelBERT outperforms several strong baselines on four benchmark datasets, i.e., VUA-18, VUA-20, MOH-X, and TroFi.