 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
May 13, 2024
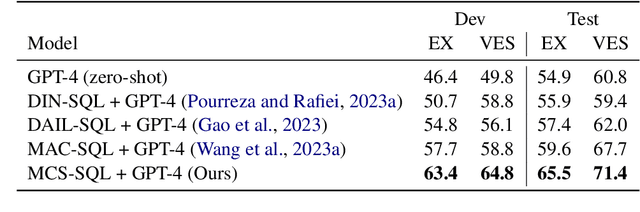


Recent advancements in large language models (LLMs) have enabled in-context learning (ICL)-based methods that significantly outperform fine-tuning approaches for text-to-SQL tasks. However, their performance is still considerably lower than that of human experts on benchmarks that include complex schemas and queries, such as BIRD. This study considers the sensitivity of LLMs to the prompts and introduces a novel approach that leverages multiple prompts to explore a broader search space for possible answers and effectively aggregate them. Specifically, we robustly refine the database schema through schema linking using multiple prompts. Thereafter, we generate various candidate SQL queries based on the refined schema and diverse prompts. Finally, the candidate queries are filtered based on their confidence scores, and the optimal query is obtained through a multiple-choice selection that is presented to the LLM. When evaluated on the BIRD and Spider benchmarks, the proposed method achieved execution accuracies of 65.5\% and 89.6\%, respectively, significantly outperforming previous ICL-based methods. Moreover, we established a new SOTA performance on the BIRD in terms of both the accuracy and efficiency of the generated queries.
IntelliCAT: Intelligent Machine Translation Post-Editing with Quality Estimation and Translation Suggestion
May 25, 2021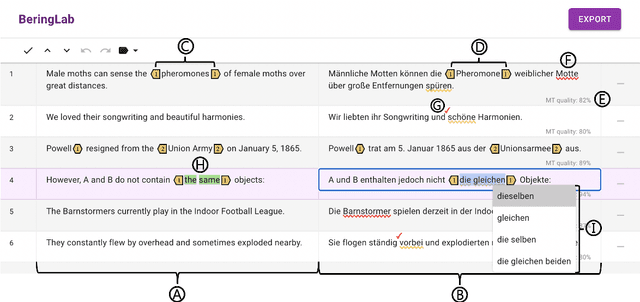
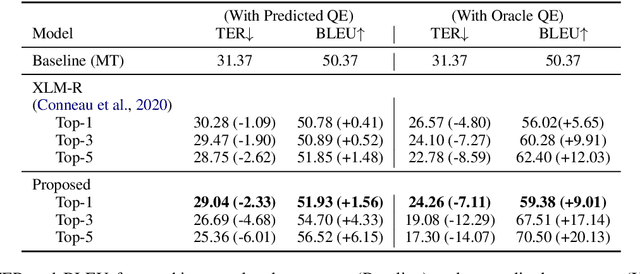
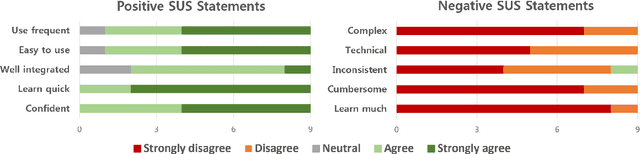
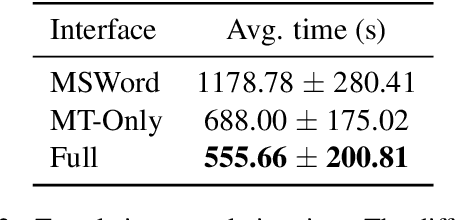
We present IntelliCAT, an interactive translation interface with neural models that streamline the post-editing process on machine translation output. We leverage two quality estimation (QE) models at different granularities: sentence-level QE, to predict the quality of each machine-translated sentence, and word-level QE, to locate the parts of the machine-translated sentence that need correction. Additionally, we introduce a novel translation suggestion model conditioned on both the left and right contexts, providing alternatives for specific words or phrases for correction. Finally, with word alignments, IntelliCAT automatically preserves the original document's styles in the translated document. The experimental results show that post-editing based on the proposed QE and translation suggestions can significantly improve translation quality. Furthermore, a user study reveals that three features provided in IntelliCAT significantly accelerate the post-editing task, achieving a 52.9\% speedup in translation time compared to translating from scratch. The interface is publicly available at https://intellicat.beringlab.com/.
MelBERT: Metaphor Detection via Contextualized Late Interaction using Metaphorical Identification Theories
Apr 28, 2021



Automated metaphor detection is a challenging task to identify metaphorical expressions of words in a sentence. To tackle this problem, we adopt pre-trained contextualized models, e.g., BERT and RoBERTa. To this end, we propose a novel metaphor detection model, namely metaphor-aware late interaction over BERT (MelBERT). Our model not only leverages contextualized word representation but also benefits from linguistic metaphor identification theories to distinguish between the contextual and literal meaning of words. Our empirical results demonstrate that MelBERT outperforms several strong baselines on four benchmark datasets, i.e., VUA-18, VUA-20, MOH-X, and TroFi.