 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-View Spatial Reasoning from Cross-View Relations
Mar 30, 2026Vision-language models (VLMs) have achieved impressive results on single-view vision tasks, but lack the multi-view spatial reasoning capabilities essential for embodied AI systems to understand 3D environments and manipulate objects across different viewpoints. In this work, we introduce Cross-View Relations (XVR), a large-scale dataset designed to teach VLMs spatial reasoning across multiple views. XVR comprises 100K vision-question-answer samples derived from 18K diverse 3D scenes and 70K robotic manipulation trajectories, spanning three fundamental spatial reasoning tasks: Correspondence (matching objects across views), Verification (validating spatial relationships), and Localization (identifying object positions). VLMs fine-tuned on XVR achieve substantial improvements on established multi-view and robotic spatial reasoning benchmarks (MindCube and RoboSpatial). When integrated as backbones in Vision-Language-Action models, XVR-trained representations improve success rates on RoboCasa. Our results demonstrate that explicit training on cross-view spatial relations significantly enhances multi-view reasoning and transfers effectively to real-world robotic manipulation.
Learning to Generate Unit Test via Adversarial Reinforcement Learning
Aug 28, 2025



Unit testing is a core practice in programming, enabling systematic evaluation of programs produced by human developers or large language models (LLMs). Given the challenges in writing comprehensive unit tests, LLMs have been employed to automate test generation, yet methods for training LLMs to produce high-quality tests remain underexplored. In this work, we propose UTRL, a novel reinforcement learning framework that trains an LLM to generate high-quality unit tests given a programming instruction. Our key idea is to iteratively train two LLMs, the unit test generator and the code generator, in an adversarial manner via reinforcement learning. The unit test generator is trained to maximize a discrimination reward, which reflects its ability to produce tests that expose faults in the code generator's solutions, and the code generator is trained to maximize a code reward, which reflects its ability to produce solutions that pass the unit tests generated by the test generator. In our experiments, we demonstrate that unit tests generated by Qwen3-4B trained via UTRL show higher quality compared to unit tests generated by the same model trained via supervised fine-tuning on human-written ground-truth unit tests, yielding code evaluations that more closely align with those induced by the ground-truth tests. Moreover, Qwen3-4B trained with UTRL outperforms frontier models such as GPT-4.1 in generating high-quality unit tests, highlighting the effectiveness of UTRL in training LLMs for this task.
Causality-Aware Contrastive Learning for Robust Multivariate Time-Series Anomaly Detection
Jun 04, 2025Utilizing the complex inter-variable causal relationships within multivariate time-series provides a promising avenue toward more robust and reliable multivariate time-series anomaly detection (MTSAD) but remains an underexplored area of research. This paper proposes Causality-Aware contrastive learning for RObust multivariate Time-Series (CAROTS), a novel MTSAD pipeline that incorporates the notion of causality into contrastive learning. CAROTS employs two data augmentors to obtain causality-preserving and -disturbing samples that serve as a wide range of normal variations and synthetic anomalies, respectively. With causality-preserving and -disturbing samples as positives and negatives, CAROTS performs contrastive learning to train an encoder whose latent space separates normal and abnormal samples based on causality. Moreover, CAROTS introduces a similarity-filtered one-class contrastive loss that encourages the contrastive learning process to gradually incorporate more semantically diverse samples with common causal relationships. Extensive experiments on five real-world and two synthetic datasets validate that the integration of causal relationships endows CAROTS with improved MTSAD capabilities. The code is available at https://github.com/kimanki/CAROTS.
Automated Skill Discovery for Language Agents through Exploration and Iterative Feedback
Jun 04, 2025Training large language model (LLM) agents to acquire necessary skills and perform diverse tasks within an environment is gaining interest as a means to enable open-endedness. However, creating the training dataset for their skill acquisition faces several challenges. Manual trajectory collection requires significant human effort. Another approach, where LLMs directly propose tasks to learn, is often invalid, as the LLMs lack knowledge of which tasks are actually feasible. Moreover, the generated data may not provide a meaningful learning signal, as agents often already perform well on the proposed tasks. To address this, we propose a novel automatic skill discovery framework EXIF for LLM-powered agents, designed to improve the feasibility of generated target behaviors while accounting for the agents' capabilities. Our method adopts an exploration-first strategy by employing an exploration agent (Alice) to train the target agent (Bob) to learn essential skills in the environment. Specifically, Alice first interacts with the environment to retrospectively generate a feasible, environment-grounded skill dataset, which is then used to train Bob. Crucially, we incorporate an iterative feedback loop, where Alice evaluates Bob's performance to identify areas for improvement. This feedback then guides Alice's next round of exploration, forming a closed-loop data generation process. Experiments on Webshop and Crafter demonstrate EXIF's ability to effectively discover meaningful skills and iteratively expand the capabilities of the trained agent without any human intervention, achieving substantial performance improvements. Interestingly, we observe that setting Alice to the same model as Bob also notably improves performance, demonstrating EXIF's potential for building a self-evolving system.
Consensus-aware Contrastive Learning for Group Recommendation
Apr 18, 2025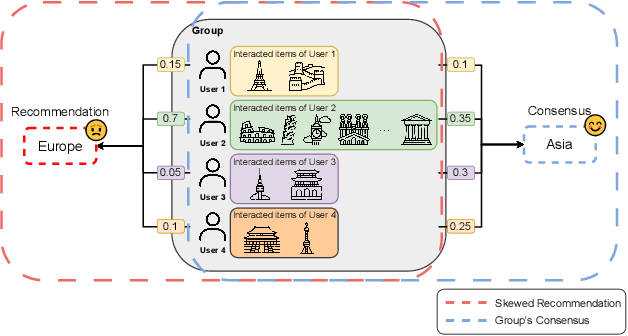
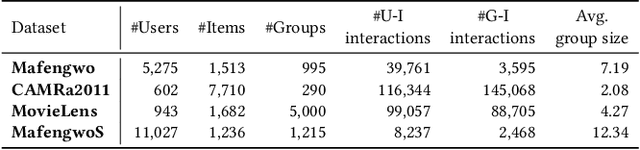
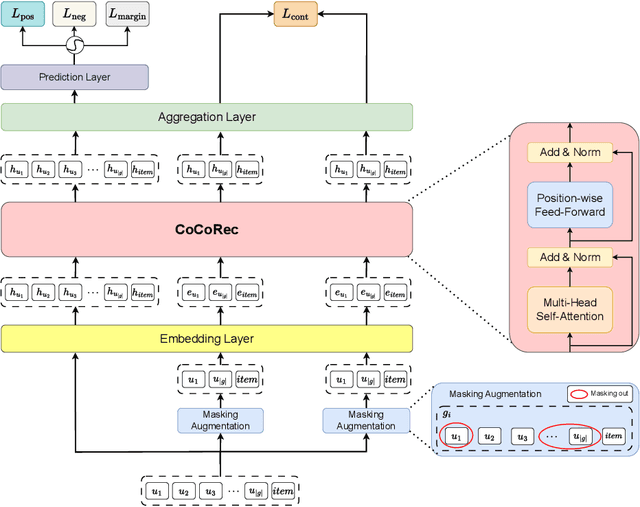
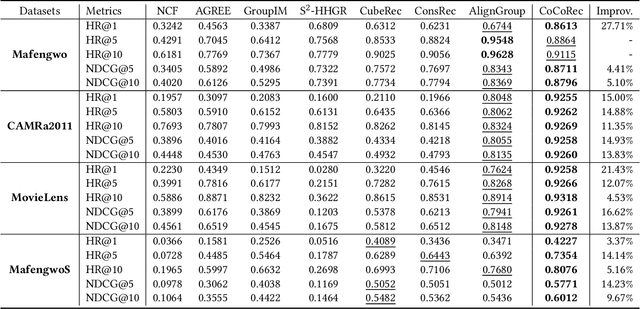
Group recommendation aims to provide personalized item suggestions to a group of users by reflecting their collective preferences. A fundamental challenge in this task is deriving a consensus that adequately represents the diverse interests of individual group members. Despite advancements made by deep learning-based models, existing approaches still struggle in two main areas: (1) Capturing consensus in small-group settings, which are more prevalent in real-world applications, and (2) Balancing individual preferences with overall group performance, particularly in hypergraph-based methods that tend to emphasize group accuracy at the expense of personalization. To address these challenges, we introduce a Consensus-aware Contrastive Learning for Group Recommendation (CoCoRec) that models group consensus through contrastive learning. CoCoRec utilizes a transformer encoder to jointly learn user and group representations, enabling richer modeling of intra-group dynamics. Additionally, the contrastive objective helps reduce overfitting from high-frequency user interactions, leading to more robust and representative group embeddings. Experiments conducted on four benchmark datasets show that CoCoRec consistently outperforms state-of-the-art baselines in both individual and group recommendation scenarios, highlighting the effectiveness of consensus-aware contrastive learning in group recommendation tasks.
Efficient Gradient-Based Inference for Manipulation Planning in Contact Factor Graphs
Mar 08, 2025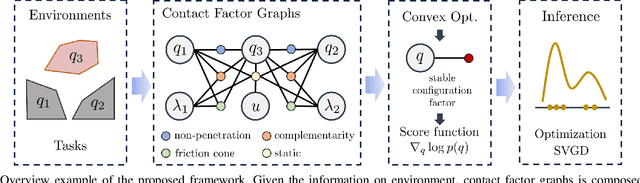



This paper presents a framework designed to tackle a range of planning problems arise in manipulation, which typically involve complex geometric-physical reasoning related to contact and dynamic constraints. We introduce the Contact Factor Graph (CFG) to graphically model these diverse factors, enabling us to perform inference on the graphs to approximate the distribution and sample appropriate solutions. We propose a novel approach that can incorporate various phenomena of contact manipulation as differentiable factors, and develop an efficient inference algorithm for CFG that leverages this differentiability along with the conditional probabilities arising from the structured nature of contact. Our results demonstrate the capability of our framework in generating viable samples and approximating posterior distributions for various manipulation scenarios.
Variations of Augmented Lagrangian for Robotic Multi-Contact Simulation
Feb 24, 2025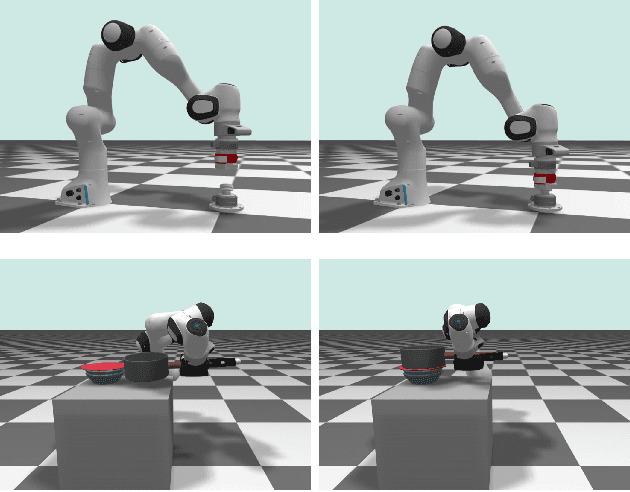



The multi-contact nonlinear complementarity problem (NCP) is a naturally arising challenge in robotic simulations. Achieving high performance in terms of both accuracy and efficiency remains a significant challenge, particularly in scenarios involving intensive contacts and stiff interactions. In this article, we introduce a new class of multi-contact NCP solvers based on the theory of the Augmented Lagrangian (AL). We detail how the standard derivation of AL in convex optimization can be adapted to handle multi-contact NCP through the iteration of surrogate problem solutions and the subsequent update of primal-dual variables. Specifically, we present two tailored variations of AL for robotic simulations: the Cascaded Newton-based Augmented Lagrangian (CANAL) and the Subsystem-based Alternating Direction Method of Multipliers (SubADMM). We demonstrate how CANAL can manage multi-contact NCP in an accurate and robust manner, while SubADMM offers superior computational speed, scalability, and parallelizability for high degrees-of-freedom multibody systems with numerous contacts. Our results showcase the effectiveness of the proposed solver framework, illustrating its advantages in various robotic manipulation scenarios.
Debiasing Classifiers by Amplifying Bias with Latent Diffusion and Large Language Models
Nov 25, 2024



Neural networks struggle with image classification when biases are learned and misleads correlations, affecting their generalization and performance. Previous methods require attribute labels (e.g. background, color) or utilizes Generative Adversarial Networks (GANs) to mitigate biases. We introduce DiffuBias, a novel pipeline for text-to-image generation that enhances classifier robustness by generating bias-conflict samples, without requiring training during the generation phase. Utilizing pretrained diffusion and image captioning models, DiffuBias generates images that challenge the biases of classifiers, using the top-$K$ losses from a biased classifier ($f_B$) to create more representative data samples. This method not only debiases effectively but also boosts classifier generalization capabilities. To the best of our knowledge, DiffuBias is the first approach leveraging a stable diffusion model to generate bias-conflict samples in debiasing tasks. Our comprehensive experimental evaluations demonstrate that DiffuBias achieves state-of-the-art performance on benchmark datasets. We also conduct a comparative analysis of various generative models in terms of carbon emissions and energy consumption to highlight the significance of computational efficiency.
Introducing Spectral Attention for Long-Range Dependency in Time Series Forecasting
Oct 28, 2024



Sequence modeling faces challenges in capturing long-range dependencies across diverse tasks. Recent linear and transformer-based forecasters have shown superior performance in time series forecasting. However, they are constrained by their inherent inability to effectively address long-range dependencies in time series data, primarily due to using fixed-size inputs for prediction. Furthermore, they typically sacrifice essential temporal correlation among consecutive training samples by shuffling them into mini-batches. To overcome these limitations, we introduce a fast and effective Spectral Attention mechanism, which preserves temporal correlations among samples and facilitates the handling of long-range information while maintaining the base model structure. Spectral Attention preserves long-period trends through a low-pass filter and facilitates gradient to flow between samples. Spectral Attention can be seamlessly integrated into most sequence models, allowing models with fixed-sized look-back windows to capture long-range dependencies over thousands of steps. Through extensive experiments on 11 real-world time series datasets using 7 recent forecasting models, we consistently demonstrate the efficacy of our Spectral Attention mechanism, achieving state-of-the-art results.
Narrow Passage Path Planning using Collision Constraint Interpolation
Oct 28, 2024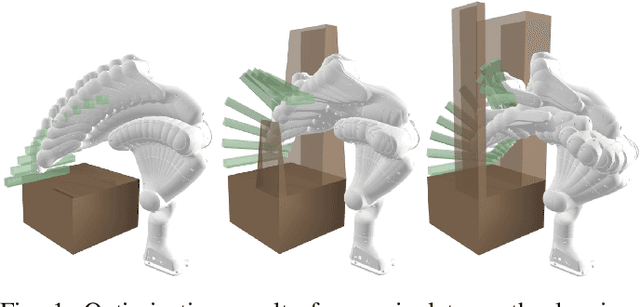
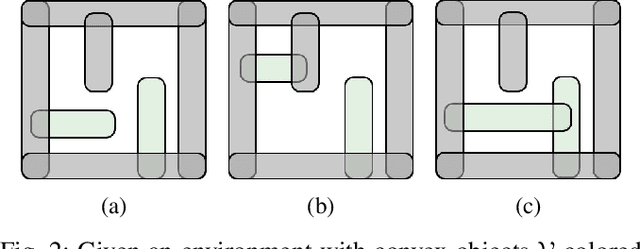

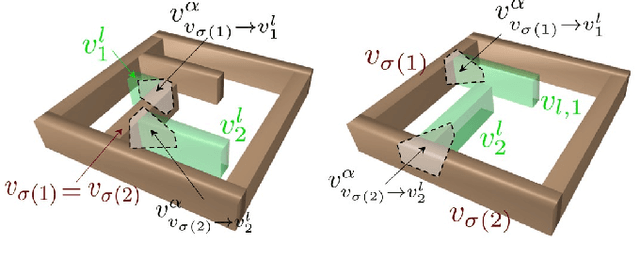
Narrow passage path planning is a prevalent problem from industrial to household sites, often facing difficulties in finding feasible paths or requiring excessive computational resources. Given that deep penetration into the environment can cause optimization failure, we propose a framework to ensure feasibility throughout the process using a series of subproblems tailored for narrow passage problem. We begin by decomposing the environment into convex objects and initializing collision constraints with a subset of these objects. By continuously interpolating the collision constraints through the process of sequentially introducing remaining objects, our proposed framework generates subproblems that guide the optimization toward solving the narrow passage problem. Several examples are presented to demonstrate how the proposed framework addresses narrow passage path planning problems.