 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Gradient-Based Inference for Manipulation Planning in Contact Factor Graphs
Mar 08, 2025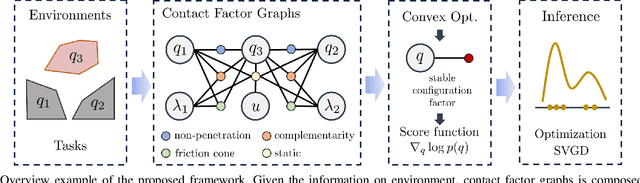



This paper presents a framework designed to tackle a range of planning problems arise in manipulation, which typically involve complex geometric-physical reasoning related to contact and dynamic constraints. We introduce the Contact Factor Graph (CFG) to graphically model these diverse factors, enabling us to perform inference on the graphs to approximate the distribution and sample appropriate solutions. We propose a novel approach that can incorporate various phenomena of contact manipulation as differentiable factors, and develop an efficient inference algorithm for CFG that leverages this differentiability along with the conditional probabilities arising from the structured nature of contact. Our results demonstrate the capability of our framework in generating viable samples and approximating posterior distributions for various manipulation scenarios.
Variations of Augmented Lagrangian for Robotic Multi-Contact Simulation
Feb 24, 2025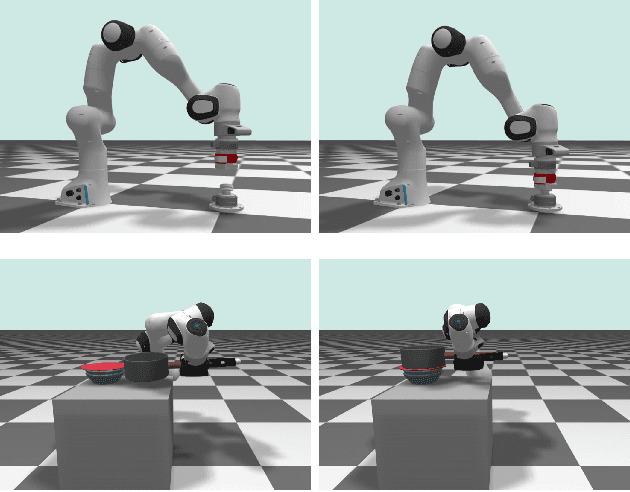



The multi-contact nonlinear complementarity problem (NCP) is a naturally arising challenge in robotic simulations. Achieving high performance in terms of both accuracy and efficiency remains a significant challenge, particularly in scenarios involving intensive contacts and stiff interactions. In this article, we introduce a new class of multi-contact NCP solvers based on the theory of the Augmented Lagrangian (AL). We detail how the standard derivation of AL in convex optimization can be adapted to handle multi-contact NCP through the iteration of surrogate problem solutions and the subsequent update of primal-dual variables. Specifically, we present two tailored variations of AL for robotic simulations: the Cascaded Newton-based Augmented Lagrangian (CANAL) and the Subsystem-based Alternating Direction Method of Multipliers (SubADMM). We demonstrate how CANAL can manage multi-contact NCP in an accurate and robust manner, while SubADMM offers superior computational speed, scalability, and parallelizability for high degrees-of-freedom multibody systems with numerous contacts. Our results showcase the effectiveness of the proposed solver framework, illustrating its advantages in various robotic manipulation scenarios.
Machine Learning Optimal Ordering in Global Routing Problems in Semiconductors
Dec 30, 2024In this work, we propose a new method for ordering nets during the process of layer assignment in global routing problems. The global routing problems that we focus on in this work are based on routing problems that occur in the design of substrates in multilayered semiconductor packages. The proposed new method is based on machine learning techniques and we show that the proposed method supersedes conventional net ordering techniques based on heuristic score functions. We perform global routing experiments in multilayered semiconductor package environments in order to illustrate that the routing order based on our new proposed technique outperforms previous methods based on heuristics. Our approach of using machine learning for global routing targets specifically the net ordering step which we show in this work can be significantly improved by deep learning.
* 18 pages, 13 figures, 6 tables; published in Scientific Reports
Narrow Passage Path Planning using Collision Constraint Interpolation
Oct 28, 2024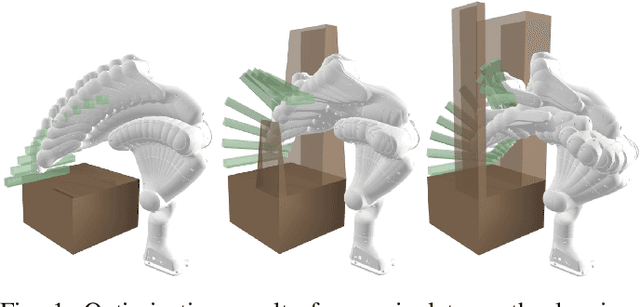
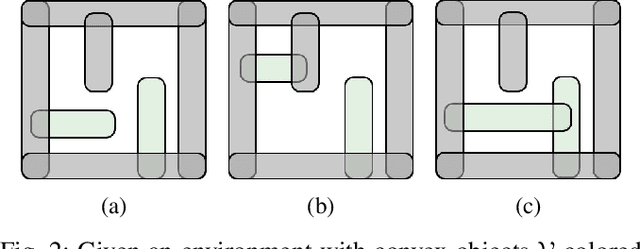

Narrow passage path planning is a prevalent problem from industrial to household sites, often facing difficulties in finding feasible paths or requiring excessive computational resources. Given that deep penetration into the environment can cause optimization failure, we propose a framework to ensure feasibility throughout the process using a series of subproblems tailored for narrow passage problem. We begin by decomposing the environment into convex objects and initializing collision constraints with a subset of these objects. By continuously interpolating the collision constraints through the process of sequentially introducing remaining objects, our proposed framework generates subproblems that guide the optimization toward solving the narrow passage problem. Several examples are presented to demonstrate how the proposed framework addresses narrow passage path planning problems.
Recent advances in interpretable machine learning using structure-based protein representations
Sep 26, 2024Recent advancements in machine learning (ML) are transforming the field of structural biology. For example, AlphaFold, a groundbreaking neural network for protein structure prediction, has been widely adopted by researchers. The availability of easy-to-use interfaces and interpretable outcomes from the neural network architecture, such as the confidence scores used to color the predicted structures, have made AlphaFold accessible even to non-ML experts. In this paper, we present various methods for representing protein 3D structures from low- to high-resolution, and show how interpretable ML methods can support tasks such as predicting protein structures, protein function, and protein-protein interactions. This survey also emphasizes the significance of interpreting and visualizing ML-based inference for structure-based protein representations that enhance interpretability and knowledge discovery. Developing such interpretable approaches promises to further accelerate fields including drug development and protein design.
Robust Optimization in Protein Fitness Landscapes Using Reinforcement Learning in Latent Space
May 29, 2024



Proteins are complex molecules responsible for different functions in nature. Enhancing the functionality of proteins and cellular fitness can significantly impact various industries. However, protein optimization using computational methods remains challenging, especially when starting from low-fitness sequences. We propose LatProtRL, an optimization method to efficiently traverse a latent space learned by an encoder-decoder leveraging a large protein language model. To escape local optima, our optimization is modeled as a Markov decision process using reinforcement learning acting directly in latent space. We evaluate our approach on two important fitness optimization tasks, demonstrating its ability to achieve comparable or superior fitness over baseline methods. Our findings and in vitro evaluation show that the generated sequences can reach high-fitness regions, suggesting a substantial potential of LatProtRL in lab-in-the-loop scenarios.
Out of Many, One: Designing and Scaffolding Proteins at the Scale of the Structural Universe with Genie 2
May 24, 2024



Protein diffusion models have emerged as a promising approach for protein design. One such pioneering model is Genie, a method that asymmetrically represents protein structures during the forward and backward processes, using simple Gaussian noising for the former and expressive SE(3)-equivariant attention for the latter. In this work we introduce Genie 2, extending Genie to capture a larger and more diverse protein structure space through architectural innovations and massive data augmentation. Genie 2 adds motif scaffolding capabilities via a novel multi-motif framework that designs co-occurring motifs with unspecified inter-motif positions and orientations. This makes possible complex protein designs that engage multiple interaction partners and perform multiple functions. On both unconditional and conditional generation, Genie 2 achieves state-of-the-art performance, outperforming all known methods on key design metrics including designability, diversity, and novelty. Genie 2 also solves more motif scaffolding problems than other methods and does so with more unique and varied solutions. Taken together, these advances set a new standard for structure-based protein design. Genie 2 inference and training code, as well as model weights, are freely available at: https://github.com/aqlaboratory/genie2.
FingerNet: EEG Decoding of A Fine Motor Imagery with Finger-tapping Task Based on A Deep Neural Network
Mar 06, 2024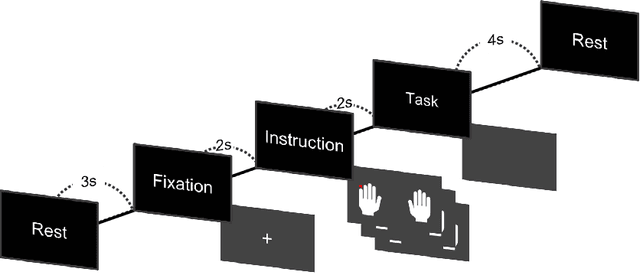

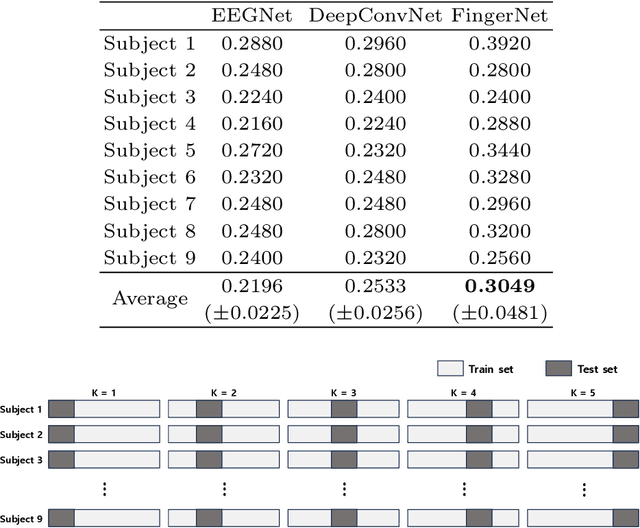
Brain-computer interface (BCI) technology facilitates communication between the human brain and computers, primarily utilizing electroencephalography (EEG) signals to discern human intentions. Although EEG-based BCI systems have been developed for paralysis individuals, ongoing studies explore systems for speech imagery and motor imagery (MI). This study introduces FingerNet, a specialized network for fine MI classification, departing from conventional gross MI studies. The proposed FingerNet could extract spatial and temporal features from EEG signals, improving classification accuracy within the same hand. The experimental results demonstrated that performance showed significantly higher accuracy in classifying five finger-tapping tasks, encompassing thumb, index, middle, ring, and little finger movements. FingerNet demonstrated dominant performance compared to the conventional baseline models, EEGNet and DeepConvNet. The average accuracy for FingerNet was 0.3049, whereas EEGNet and DeepConvNet exhibited lower accuracies of 0.2196 and 0.2533, respectively. Statistical validation also demonstrates the predominance of FingerNet over baseline networks. For biased predictions, particularly for thumb and index classes, we led to the implementation of weighted cross-entropy and also adapted the weighted cross-entropy, a method conventionally employed to mitigate class imbalance. The proposed FingerNet involves optimizing network structure, improving performance, and exploring applications beyond fine MI. Moreover, the weighted Cross Entropy approach employed to address such biased predictions appears to have broader applicability and relevance across various domains involving multi-class classification tasks. We believe that effective execution of motor imagery can be achieved not only for fine MI, but also for local muscle MI
Enhancing Spatiotemporal Traffic Prediction through Urban Human Activity Analysis
Aug 20, 2023
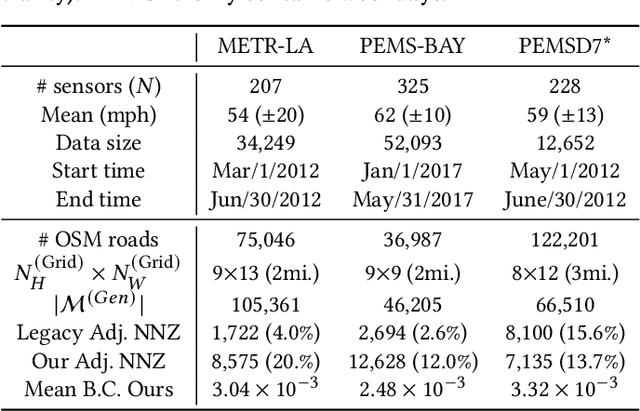

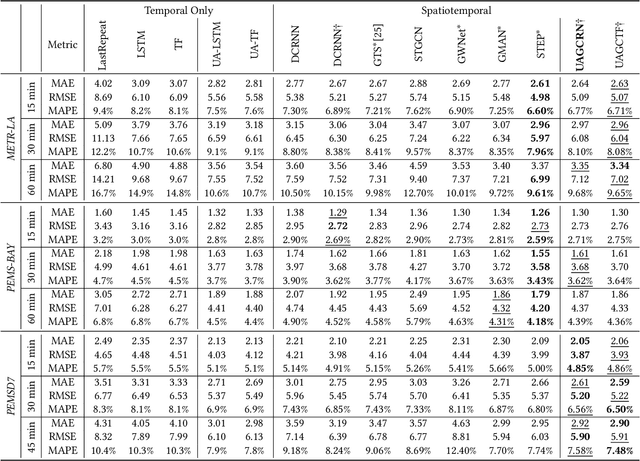
Traffic prediction is one of the key elements to ensure the safety and convenience of citizens. Existing traffic prediction models primarily focus on deep learning architectures to capture spatial and temporal correlation. They often overlook the underlying nature of traffic. Specifically, the sensor networks in most traffic datasets do not accurately represent the actual road network exploited by vehicles, failing to provide insights into the traffic patterns in urban activities. To overcome these limitations, we propose an improved traffic prediction method based on graph convolution deep learning algorithms. We leverage human activity frequency data from National Household Travel Survey to enhance the inference capability of a causal relationship between activity and traffic patterns. Despite making minimal modifications to the conventional graph convolutional recurrent networks and graph convolutional transformer architectures, our approach achieves state-of-the-art performance without introducing excessive computational overhead.
Local-Global Temporal Fusion Network with an Attention Mechanism for Multiple and Multiclass Arrhythmia Classification
Aug 03, 2023Clinical decision support systems (CDSSs) have been widely utilized to support the decisions made by cardiologists when detecting and classifying arrhythmia from electrocardiograms (ECGs). However, forming a CDSS for the arrhythmia classification task is challenging due to the varying lengths of arrhythmias. Although the onset time of arrhythmia varies, previously developed methods have not considered such conditions. Thus, we propose a framework that consists of (i) local temporal information extraction, (ii) global pattern extraction, and (iii) local-global information fusion with attention to perform arrhythmia detection and classification with a constrained input length. The 10-class and 4-class performances of our approach were assessed by detecting the onset and offset of arrhythmia as an episode and the duration of arrhythmia based on the MIT-BIH arrhythmia database (MITDB) and MIT-BIH atrial fibrillation database (AFDB), respectively. The results were statistically superior to those achieved by the comparison models. To check the generalization ability of the proposed method, an AFDB-trained model was tested on the MITDB, and superior performance was attained compared with that of a state-of-the-art model. The proposed method can capture local-global information and dynamics without incurring information losses. Therefore, arrhythmias can be recognized more accurately, and their occurrence times can be calculated; thus, the clinical field can create more accurate treatment plans by using the proposed method.