 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Optimal Ordering in Global Routing Problems in Semiconductors
Dec 30, 2024In this work, we propose a new method for ordering nets during the process of layer assignment in global routing problems. The global routing problems that we focus on in this work are based on routing problems that occur in the design of substrates in multilayered semiconductor packages. The proposed new method is based on machine learning techniques and we show that the proposed method supersedes conventional net ordering techniques based on heuristic score functions. We perform global routing experiments in multilayered semiconductor package environments in order to illustrate that the routing order based on our new proposed technique outperforms previous methods based on heuristics. Our approach of using machine learning for global routing targets specifically the net ordering step which we show in this work can be significantly improved by deep learning.
* 18 pages, 13 figures, 6 tables; published in Scientific Reports
Easy Learning from Label Proportions
Feb 13, 2023



We consider the problem of Learning from Label Proportions (LLP), a weakly supervised classification setup where instances are grouped into "bags", and only the frequency of class labels at each bag is available. Albeit, the objective of the learner is to achieve low task loss at an individual instance level. Here we propose Easyllp: a flexible and simple-to-implement debiasing approach based on aggregate labels, which operates on arbitrary loss functions. Our technique allows us to accurately estimate the expected loss of an arbitrary model at an individual level. We showcase the flexibility of our approach by applying it to popular learning frameworks, like Empirical Risk Minimization (ERM) and Stochastic Gradient Descent (SGD) with provable guarantees on instance level performance. More concretely, we exhibit a variance reduction technique that makes the quality of LLP learning deteriorate only by a factor of k (k being bag size) in both ERM and SGD setups, as compared to full supervision. Finally, we validate our theoretical results on multiple datasets demonstrating our algorithm performs as well or better than previous LLP approaches in spite of its simplicity.
An Empirical Study on L2 Accents of Cross-lingual Text-to-Speech Systems via Vowel Space
Nov 06, 2022With the recent developments in cross-lingual Text-to-Speech (TTS) systems, L2 (second-language, or foreign) accent problems arise. Moreover, running a subjective evaluation for such cross-lingual TTS systems is troublesome. The vowel space analysis, which is often utilized to explore various aspects of language including L2 accents, is a great alternative analysis tool. In this study, we apply the vowel space analysis method to explore L2 accents of cross-lingual TTS systems. Through the vowel space analysis, we observe the three followings: a) a parallel architecture (Glow-TTS) is less L2-accented than an auto-regressive one (Tacotron); b) L2 accents are more dominant in non-shared vowels in a language pair; and c) L2 accents of cross-lingual TTS systems share some phenomena with those of human L2 learners. Our findings imply that it is necessary for TTS systems to handle each language pair differently, depending on their linguistic characteristics such as non-shared vowels. They also hint that we can further incorporate linguistics knowledge in developing cross-lingual TTS systems.
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022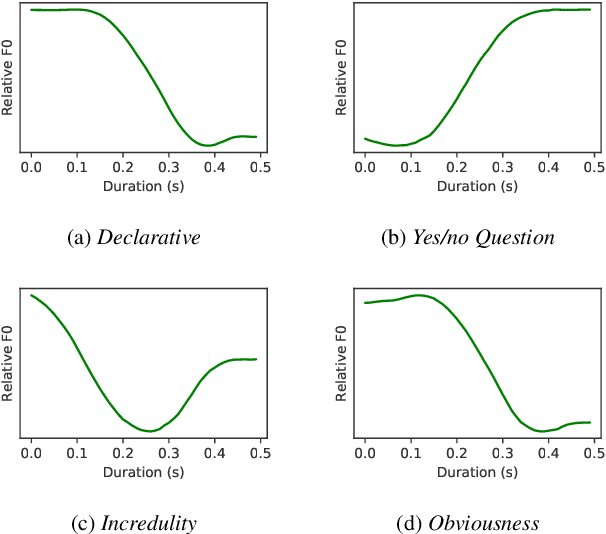

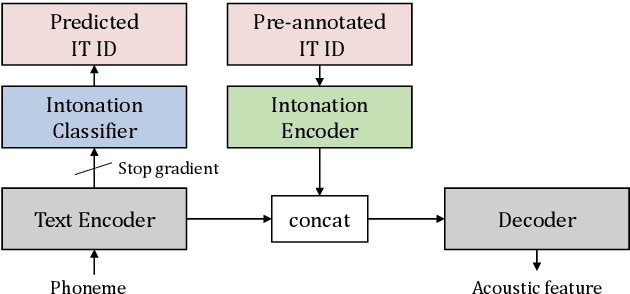
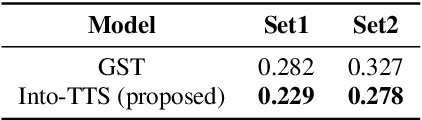
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.
Efficient Structured Surrogate Loss and Regularization in Structured Prediction
Sep 14, 2018


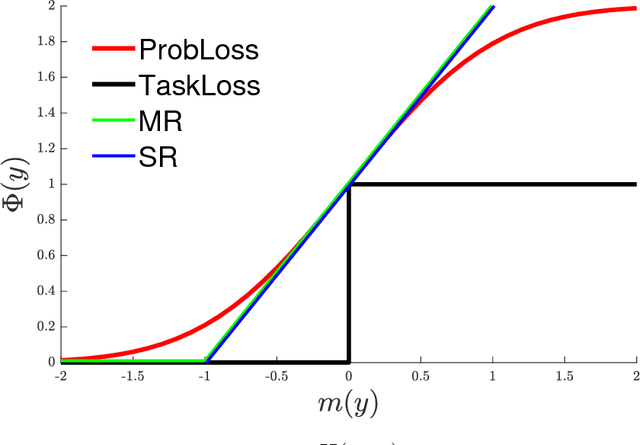
In this dissertation, we focus on several important problems in structured prediction. In structured prediction, the label has a rich intrinsic substructure, and the loss varies with respect to the predicted label and the true label pair. Structured SVM is an extension of binary SVM to adapt to such structured tasks. In the first part of the dissertation, we study the surrogate losses and its efficient methods. To minimize the empirical risk, a surrogate loss which upper bounds the loss, is used as a proxy to minimize the actual loss. Since the objective function is written in terms of the surrogate loss, the choice of the surrogate loss is important, and the performance depends on it. Another issue regarding the surrogate loss is the efficiency of the argmax label inference for the surrogate loss. Efficient inference is necessary for the optimization since it is often the most time-consuming step. We present a new class of surrogate losses named bi-criteria surrogate loss, which is a generalization of the popular surrogate losses. We first investigate an efficient method for a slack rescaling formulation as a starting point utilizing decomposability of the model. Then, we extend the algorithm to the bi-criteria surrogate loss, which is very efficient and also shows performance improvements. In the second part of the dissertation, another important issue of regularization is studied. Specifically, we investigate a problem of regularization in hierarchical classification when a structural imbalance exists in the label structure. We present a method to normalize the structure, as well as a new norm, namely shared Frobenius norm. It is suitable for hierarchical classification that adapts to the data in addition to the label structure.
Normalized Hierarchical SVM
Mar 04, 2016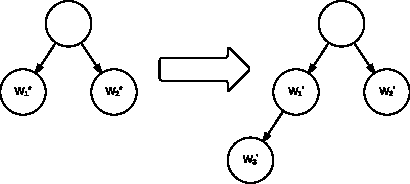
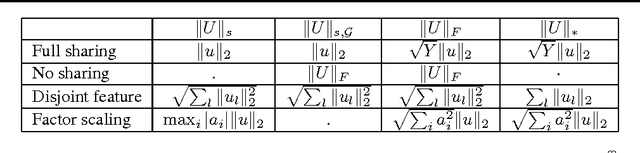
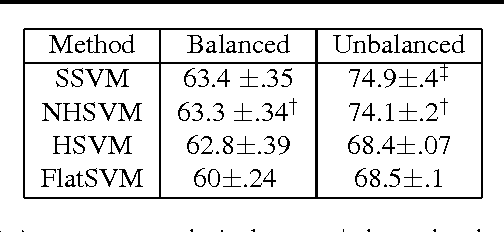
We present improved methods of using structured SVMs in a large-scale hierarchical classification problem, that is when labels are leaves, or sets of leaves, in a tree or a DAG. We examine the need to normalize both the regularization and the margin and show how doing so significantly improves performance, including allowing achieving state-of-the-art results where unnormalized structured SVMs do not perform better than flat models. We also describe a further extension of hierarchical SVMs that highlight the connection between hierarchical SVMs and matrix factorization models.
Fast and Scalable Structural SVM with Slack Rescaling
Oct 27, 2015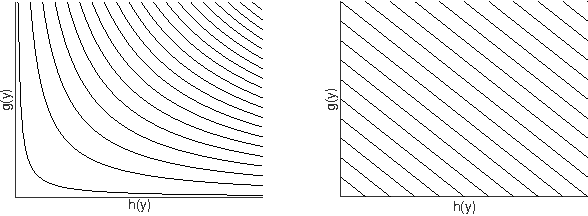
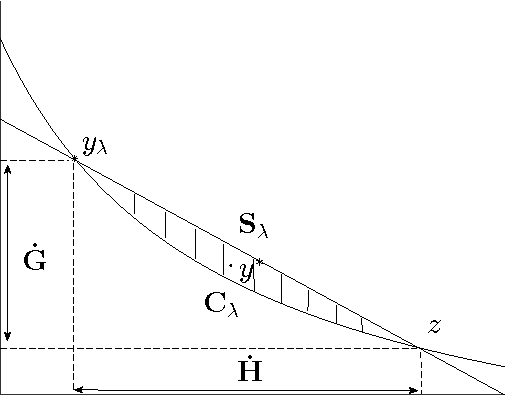
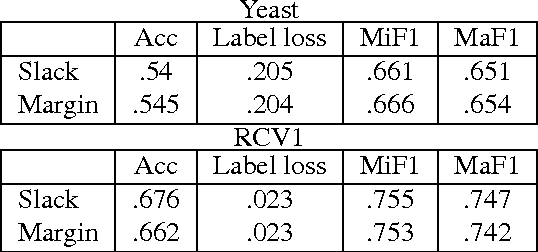
We present an efficient method for training slack-rescaled structural SVM. Although finding the most violating label in a margin-rescaled formulation is often easy since the target function decomposes with respect to the structure, this is not the case for a slack-rescaled formulation, and finding the most violated label might be very difficult. Our core contribution is an efficient method for finding the most-violating-label in a slack-rescaled formulation, given an oracle that returns the most-violating-label in a (slightly modified) margin-rescaled formulation. We show that our method enables accurate and scalable training for slack-rescaled SVMs, reducing runtime by an order of magnitude compared to previous approaches to slack-rescaled SVMs.