 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect Decoding in Phonated and Silent Speech Production from Surface EMG
Mar 12, 2026The expression of affect is integral to spoken communication, yet, its link to underlying articulatory execution remains unclear. Measures of articulatory muscle activity such as EMG could reveal how speech production is modulated by emotion alongside acoustic speech analyses. We investigate affect decoding from facial and neck surface electromyography (sEMG) during phonated and silent speech production. For this purpose, we introduce a dataset comprising 2,780 utterances from 12 participants across 3 tasks, on which we evaluate both intra- and inter-subject decoding using a range of features and model embeddings. Our results reveal that EMG representations reliably discriminate frustration with up to 0.845 AUC, and generalize well across articulation modes. Our ablation study further demonstrates that affective signatures are embedded in facial motor activity and persist in the absence of phonation, highlighting the potential of EMG sensing for affect-aware silent speech interfaces.
Follow the Saliency: Supervised Saliency for Retrieval-augmented Dense Video Captioning
Mar 12, 2026Existing retrieval-augmented approaches for Dense Video Captioning (DVC) often fail to achieve accurate temporal segmentation aligned with true event boundaries, as they rely on heuristic strategies that overlook ground truth event boundaries. The proposed framework, \textbf{STaRC}, overcomes this limitation by supervising frame-level saliency through a highlight detection module. Note that the highlight detection module is trained on binary labels derived directly from DVC ground truth annotations without the need for additional annotation. We also propose to utilize the saliency scores as a unified temporal signal that drives retrieval via saliency-guided segmentation and informs caption generation through explicit Saliency Prompts injected into the decoder. By enforcing saliency-constrained segmentation, our method produces temporally coherent segments that align closely with actual event transitions, leading to more accurate retrieval and contextually grounded caption generation. We conduct comprehensive evaluations on the YouCook2 and ViTT benchmarks, where STaRC achieves state-of-the-art performance across most of the metrics. Our code is available at https://github.com/ermitaju1/STaRC
An Approach to Simultaneous Acquisition of Real-Time MRI Video, EEG, and Surface EMG for Articulatory, Brain, and Muscle Activity During Speech Production
Mar 05, 2026Speech production is a complex process spanning neural planning, motor control, muscle activation, and articulatory kinematics. While the acoustic speech signal is the most accessible product of the speech production act, it does not directly reveal its causal neurophysiological substrates. We present the first simultaneous acquisition of real-time (dynamic) MRI, EEG, and surface EMG, capturing several key aspects of the speech production chain: brain signals, muscle activations, and articulatory movements. This multimodal acquisition paradigm presents substantial technical challenges, including MRI-induced electromagnetic interference and myogenic artifacts. To mitigate these, we introduce an artifact suppression pipeline tailored to this tri-modal setting. Once fully developed, this framework is poised to offer an unprecedented window into speech neuroscience and insights leading to brain-computer interface advances.
Quantifying Speaker Embedding Phonological Rule Interactions in Accented Speech Synthesis
Jan 20, 2026Many spoken languages, including English, exhibit wide variation in dialects and accents, making accent control an important capability for flexible text-to-speech (TTS) models. Current TTS systems typically generate accented speech by conditioning on speaker embeddings associated with specific accents. While effective, this approach offers limited interpretability and controllability, as embeddings also encode traits such as timbre and emotion. In this study, we analyze the interaction between speaker embeddings and linguistically motivated phonological rules in accented speech synthesis. Using American and British English as a case study, we implement rules for flapping, rhoticity, and vowel correspondences. We propose the phoneme shift rate (PSR), a novel metric quantifying how strongly embeddings preserve or override rule-based transformations. Experiments show that combining rules with embeddings yields more authentic accents, while embeddings can attenuate or overwrite rules, revealing entanglement between accent and speaker identity. Our findings highlight rules as a lever for accent control and a framework for evaluating disentanglement in speech generation.
Interpretable Modeling of Articulatory Temporal Dynamics from real-time MRI for Phoneme Recognition
Sep 19, 2025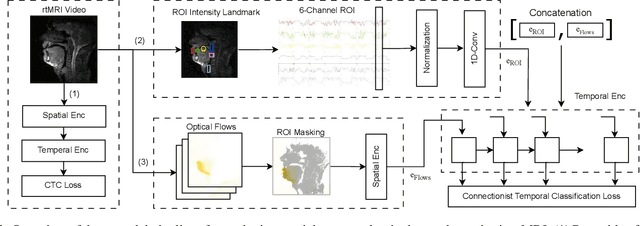
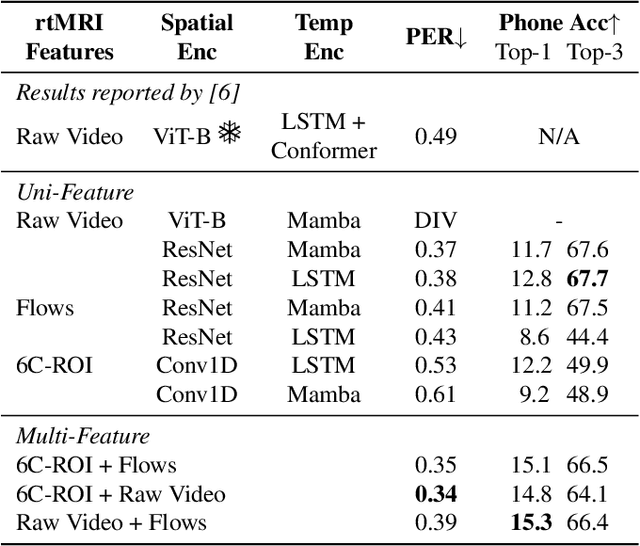
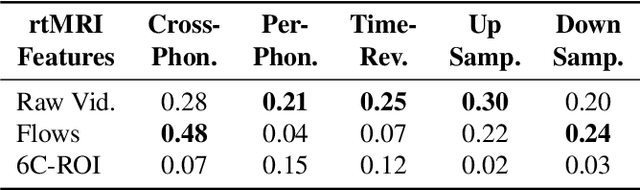
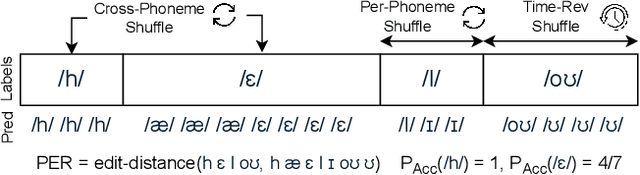
Real-time Magnetic Resonance Imaging (rtMRI) visualizes vocal tract action, offering a comprehensive window into speech articulation. However, its signals are high dimensional and noisy, hindering interpretation. We investigate compact representations of spatiotemporal articulatory dynamics for phoneme recognition from midsagittal vocal tract rtMRI videos. We compare three feature types: (1) raw video, (2) optical flow, and (3) six linguistically-relevant regions of interest (ROIs) for articulator movements. We evaluate models trained independently on each representation, as well as multi-feature combinations. Results show that multi-feature models consistently outperform single-feature baselines, with the lowest phoneme error rate (PER) of 0.34 obtained by combining ROI and raw video. Temporal fidelity experiments demonstrate a reliance on fine-grained articulatory dynamics, while ROI ablation studies reveal strong contributions from tongue and lips. Our findings highlight how rtMRI-derived features provide accuracy and interpretability, and establish strategies for leveraging articulatory data in speech processing.
Projectable Models: One-Shot Generation of Small Specialized Transformers from Large Ones
Jun 06, 2025Modern Foundation Models (FMs) are typically trained on corpora spanning a wide range of different data modalities, topics and downstream tasks. Utilizing these models can be very computationally expensive and is out of reach for most consumer devices. Furthermore, most of the broad FM knowledge may actually be irrelevant for a specific task at hand. Here we explore a technique for mapping parameters of a large Transformer to parameters of a smaller specialized model. By making this transformation task-specific, we aim to capture a narrower scope of the knowledge needed for performing a specific task by a smaller model. We study our method on image modeling tasks, showing that performance of generated models exceeds that of universal conditional models.
AMPED: Adaptive Multi-objective Projection for balancing Exploration and skill Diversification
Jun 06, 2025Skill-based reinforcement learning (SBRL) enables rapid adaptation in environments with sparse rewards by pretraining a skill-conditioned policy. Effective skill learning requires jointly maximizing both exploration and skill diversity. However, existing methods often face challenges in simultaneously optimizing for these two conflicting objectives. In this work, we propose a new method, Adaptive Multi-objective Projection for balancing Exploration and skill Diversification (AMPED), which explicitly addresses both exploration and skill diversification. We begin by conducting extensive ablation studies to identify and define a set of objectives that effectively capture the aspects of exploration and skill diversity, respectively. During the skill pretraining phase, AMPED introduces a gradient surgery technique to balance the objectives of exploration and skill diversity, mitigating conflicts and reducing reliance on heuristic tuning. In the subsequent fine-tuning phase, AMPED incorporates a skill selector module that dynamically selects suitable skills for downstream tasks, based on task-specific performance signals. Our approach achieves performance that surpasses SBRL baselines across various benchmarks. These results highlight the importance of explicitly harmonizing exploration and diversity and demonstrate the effectiveness of AMPED in enabling robust and generalizable skill learning. Project Page: https://geonwoo.me/amped/
Contextually Guided Transformers via Low-Rank Adaptation
Jun 06, 2025



Large Language Models (LLMs) based on Transformers excel at text processing, but their reliance on prompts for specialized behavior introduces computational overhead. We propose a modification to a Transformer architecture that eliminates the need for explicit prompts by learning to encode context into the model's weights. Our Contextually Guided Transformer (CGT) model maintains a contextual summary at each sequence position, allowing it to update the weights on the fly based on the preceding context. This approach enables the model to self-specialize, effectively creating a tailored model for processing information following a given prefix. We demonstrate the effectiveness of our method on synthetic in-context learning tasks and language modeling benchmarks. Furthermore, we introduce techniques for enhancing the interpretability of the learned contextual representations, drawing connections to Variational Autoencoders and promoting smoother, more consistent context encoding. This work offers a novel direction for efficient and adaptable language modeling by integrating context directly into the model's architecture.
Towards disentangling the contributions of articulation and acoustics in multimodal phoneme recognition
May 29, 2025Although many previous studies have carried out multimodal learning with real-time MRI data that captures the audio-visual kinematics of the vocal tract during speech, these studies have been limited by their reliance on multi-speaker corpora. This prevents such models from learning a detailed relationship between acoustics and articulation due to considerable cross-speaker variability. In this study, we develop unimodal audio and video models as well as multimodal models for phoneme recognition using a long-form single-speaker MRI corpus, with the goal of disentangling and interpreting the contributions of each modality. Audio and multimodal models show similar performance on different phonetic manner classes but diverge on places of articulation. Interpretation of the models' latent space shows similar encoding of the phonetic space across audio and multimodal models, while the models' attention weights highlight differences in acoustic and articulatory timing for certain phonemes.
Articulatory Feature Prediction from Surface EMG during Speech Production
May 20, 2025



We present a model for predicting articulatory features from surface electromyography (EMG) signals during speech production. The proposed model integrates convolutional layers and a Transformer block, followed by separate predictors for articulatory features. Our approach achieves a high prediction correlation of approximately 0.9 for most articulatory features. Furthermore, we demonstrate that these predicted articulatory features can be decoded into intelligible speech waveforms. To our knowledge, this is the first method to decode speech waveforms from surface EMG via articulatory features, offering a novel approach to EMG-based speech synthesis. Additionally, we analyze the relationship between EMG electrode placement and articulatory feature predictability, providing knowledge-driven insights for optimizing EMG electrode configurations. The source code and decoded speech samples are publicly available.