 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-dimensional Framework for Evaluating Generalization in EEG Foundation Models
May 27, 2026Evaluating foundation models under appropriate adaptation settings is essential for understanding the quality and transferability of the learned representations. Recent EEG foundation models have demonstrated promising transfer capabilities across tasks and datasets, motivating their growing use in neurotechnology and clinical applications. However, these models are typically evaluated under full fine-tuning on well-curated downstream datasets, a setting that does not reflect biomedical domain constraints such as limited labeled data, reduced sensor coverage, or parameter-efficient adaptation. In this work, we propose a multi-dimensional evaluation framework for assessing EEG models under realistic low-resource conditions. Empirical analysis of both supervised EEG models and recent EEG foundation models, including LaBraM, CSBrain, and CBraMod, across 6 different datasets is performed under the proposed multi-dimensional evaluation framework. We find that EEG foundation models consistently provide performance gains on long-context tasks such as sleep stage prediction and mental health state classification. In contrast, for short-window Brain Computer Interface style tasks, supervised models achieve comparable despite having substantially fewer parameters. Additional analyses demonstrate that current foundation models provide limited robustness to short-window tasks and channel constrained settings. Together, these findings motivate the use of multi-dimensional evaluation protocols that characterize model behavior under realistic use constraints.
Aperiodic and Low-Frequency Spectral Bias in Reconstruction based EEG Foundation Models
May 26, 2026EEG foundation models, pre-trained on large-scale unlabelled EEG data, have emerged as a promising direction towards learning generalizable EEG representations. Despite showing positive results in data-rich regimes, they often fail to outperform significantly smaller supervised models in low-resource settings compared to fully supervised models. We provide a mechanistic account of this shortcoming, attributing it to a fundamental mismatch between reconstruction-based pretext tasks and the idiosyncratic spectral structure of EEG signals, which decompose into distinct high-power aperiodic and low-power oscillatory components. Using controlled, synthetically-generated EEG inputs, we demonstrate that EEG foundation model embeddings are biased to capture the aperiodic components of the EEG signal while under-representing oscillatory components, particularly at higher frequencies. Additionally, linear probe evaluations on real-world BCI datasets further reveal that embeddings encode subject identity more strongly than task-relevant information, thereby reinforcing the low-frequency and aperiodic component bias in foundation model embeddings trained primarily on reconstruction based objectives. Together, these findings elucidate a failure mode in reconstruction based EEG foundation models and motivate future work to incorporate auxiliary losses explicitly targeting high-frequency oscillatory structure as a path toward more capable and generalizable EEG representations.
An Approach to Simultaneous Acquisition of Real-Time MRI Video, EEG, and Surface EMG for Articulatory, Brain, and Muscle Activity During Speech Production
Mar 05, 2026Speech production is a complex process spanning neural planning, motor control, muscle activation, and articulatory kinematics. While the acoustic speech signal is the most accessible product of the speech production act, it does not directly reveal its causal neurophysiological substrates. We present the first simultaneous acquisition of real-time (dynamic) MRI, EEG, and surface EMG, capturing several key aspects of the speech production chain: brain signals, muscle activations, and articulatory movements. This multimodal acquisition paradigm presents substantial technical challenges, including MRI-induced electromagnetic interference and myogenic artifacts. To mitigate these, we introduce an artifact suppression pipeline tailored to this tri-modal setting. Once fully developed, this framework is poised to offer an unprecedented window into speech neuroscience and insights leading to brain-computer interface advances.
Decoding Neural Signatures of Semantic Evaluations in Depression and Suicidality
Jul 30, 2025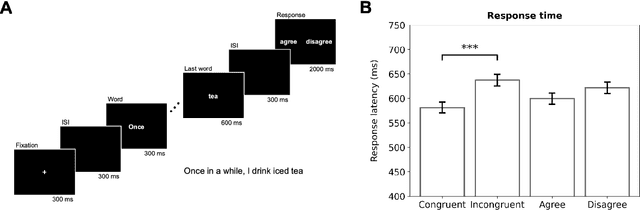
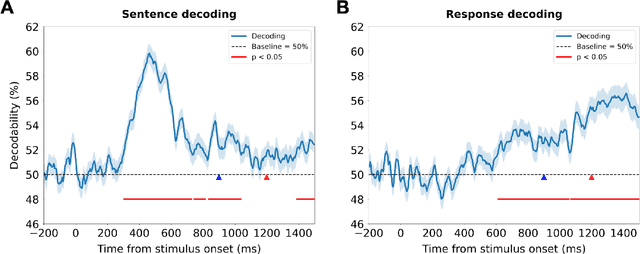
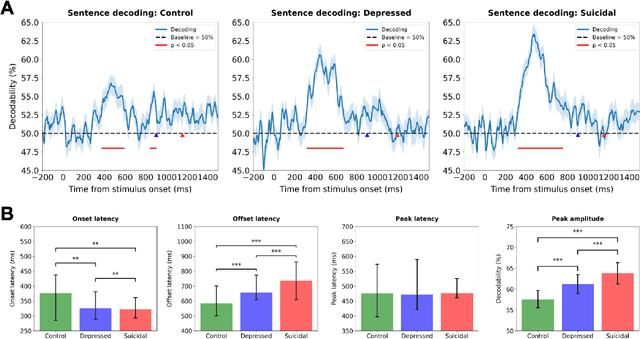
Depression and suicidality profoundly impact cognition and emotion, yet objective neurophysiological biomarkers remain elusive. We investigated the spatiotemporal neural dynamics underlying affective semantic processing in individuals with varying levels of clinical severity of depression and suicidality using multivariate decoding of electroencephalography (EEG) data. Participants (N=137) completed a sentence evaluation task involving emotionally charged self-referential statements while EEG was recorded. We identified robust, neural signatures of semantic processing, with peak decoding accuracy between 300-600 ms -- a window associated with automatic semantic evaluation and conflict monitoring. Compared to healthy controls, individuals with depression and suicidality showed earlier onset, longer duration, and greater amplitude decoding responses, along with broader cross-temporal generalization and increased activation of frontocentral and parietotemporal components. These findings suggest altered sensitivity and impaired disengagement from emotionally salient content in the clinical groups, advancing our understanding of the neurocognitive basis of mental health and providing a principled basis for developing reliable EEG-based biomarkers of depression and suicidality.
Neural Responses to Affective Sentences Reveal Signatures of Depression
Jun 06, 2025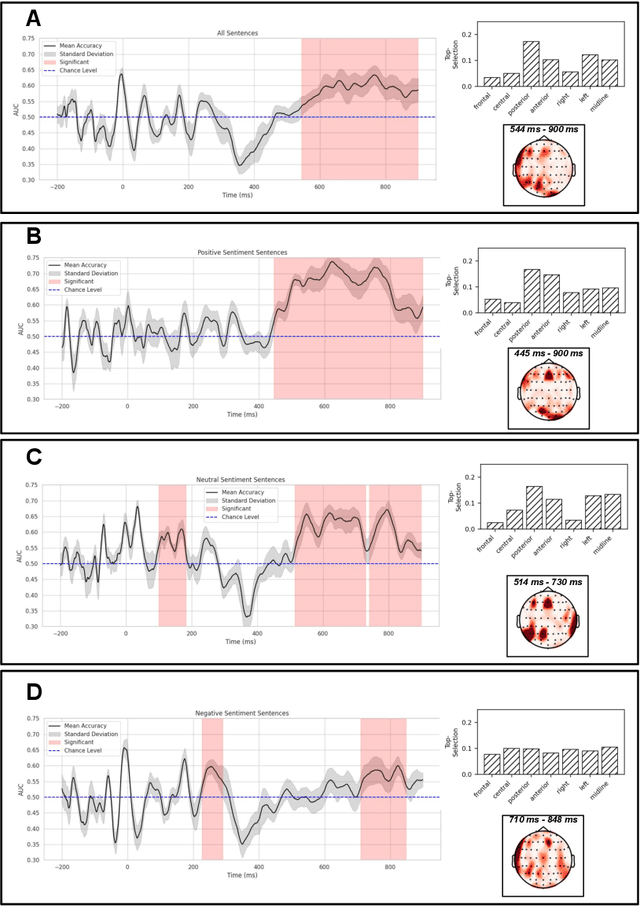
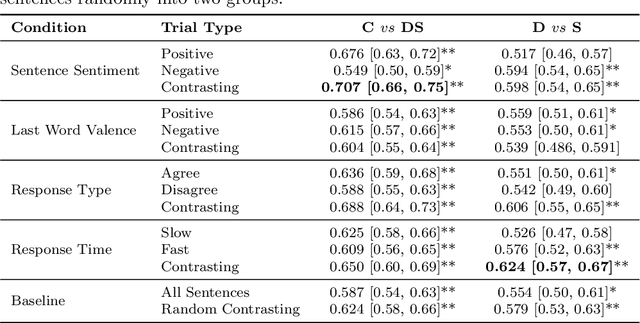
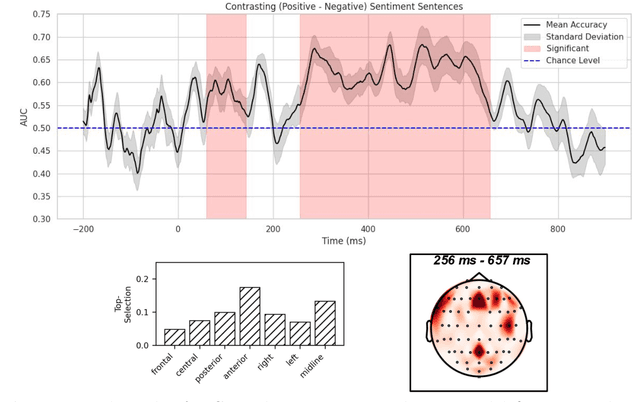

Major Depressive Disorder (MDD) is a highly prevalent mental health condition, and a deeper understanding of its neurocognitive foundations is essential for identifying how core functions such as emotional and self-referential processing are affected. We investigate how depression alters the temporal dynamics of emotional processing by measuring neural responses to self-referential affective sentences using surface electroencephalography (EEG) in healthy and depressed individuals. Our results reveal significant group-level differences in neural activity during sentence viewing, suggesting disrupted integration of emotional and self-referential information in depression. Deep learning model trained on these responses achieves an area under the receiver operating curve (AUC) of 0.707 in distinguishing healthy from depressed participants, and 0.624 in differentiating depressed subgroups with and without suicidal ideation. Spatial ablations highlight anterior electrodes associated with semantic and affective processing as key contributors. These findings suggest stable, stimulus-driven neural signatures of depression that may inform future diagnostic tools.
Deep Learning Characterizes Depression and Suicidal Ideation from Eye Movements
Apr 29, 2025Identifying physiological and behavioral markers for mental health conditions is a longstanding challenge in psychiatry. Depression and suicidal ideation, in particular, lack objective biomarkers, with screening and diagnosis primarily relying on self-reports and clinical interviews. Here, we investigate eye tracking as a potential marker modality for screening purposes. Eye movements are directly modulated by neuronal networks and have been associated with attentional and mood-related patterns; however, their predictive value for depression and suicidality remains unclear. We recorded eye-tracking sequences from 126 young adults as they read and responded to affective sentences, and subsequently developed a deep learning framework to predict their clinical status. The proposed model included separate branches for trials of positive and negative sentiment, and used 2D time-series representations to account for both intra-trial and inter-trial variations. We were able to identify depression and suicidal ideation with an area under the receiver operating curve (AUC) of 0.793 (95% CI: 0.765-0.819) against healthy controls, and suicidality specifically with 0.826 AUC (95% CI: 0.797-0.852). The model also exhibited moderate, yet significant, accuracy in differentiating depressed from suicidal participants, with 0.609 AUC (95% CI 0.571-0.646). Discriminative patterns emerge more strongly when assessing the data relative to response generation than relative to the onset time of the final word of the sentences. The most pronounced effects were observed for negative-sentiment sentences, that are congruent to depressed and suicidal participants. Our findings highlight eye tracking as an objective tool for mental health assessment and underscore the modulatory impact of emotional stimuli on cognitive processes affecting oculomotor control.
Enhancing Listened Speech Decoding from EEG via Parallel Phoneme Sequence Prediction
Jan 08, 2025



Brain-computer interfaces (BCI) offer numerous human-centered application possibilities, particularly affecting people with neurological disorders. Text or speech decoding from brain activities is a relevant domain that could augment the quality of life for people with impaired speech perception. We propose a novel approach to enhance listened speech decoding from electroencephalography (EEG) signals by utilizing an auxiliary phoneme predictor that simultaneously decodes textual phoneme sequences. The proposed model architecture consists of three main parts: EEG module, speech module, and phoneme predictor. The EEG module learns to properly represent EEG signals into EEG embeddings. The speech module generates speech waveforms from the EEG embeddings. The phoneme predictor outputs the decoded phoneme sequences in text modality. Our proposed approach allows users to obtain decoded listened speech from EEG signals in both modalities (speech waveforms and textual phoneme sequences) simultaneously, eliminating the need for a concatenated sequential pipeline for each modality. The proposed approach also outperforms previous methods in both modalities. The source code and speech samples are publicly available.
Evaluation of state-of-the-art ASR Models in Child-Adult Interactions
Sep 24, 2024



The ability to reliably transcribe child-adult conversations in a clinical setting is valuable for diagnosis and understanding of numerous developmental disorders such as Autism Spectrum Disorder. Recent advances in deep learning architectures and availability of large scale transcribed data has led to development of speech foundation models that have shown dramatic improvements in ASR performance. However, the ability of these models to translate well to conversational child-adult interactions is under studied. In this work, we provide a comprehensive evaluation of ASR performance on a dataset containing child-adult interactions from autism diagnostic sessions, using Whisper, Wav2Vec2, HuBERT, and WavLM. We find that speech foundation models show a noticeable performance drop (15-20% absolute WER) for child speech compared to adult speech in the conversational setting. Then, we employ LoRA on the best performing zero shot model (whisper-large) to probe the effectiveness of fine-tuning in a low resource setting, resulting in ~8% absolute WER improvement for child speech and ~13% absolute WER improvement for adult speech.
Toward Fully-End-to-End Listened Speech Decoding from EEG Signals
Jun 12, 2024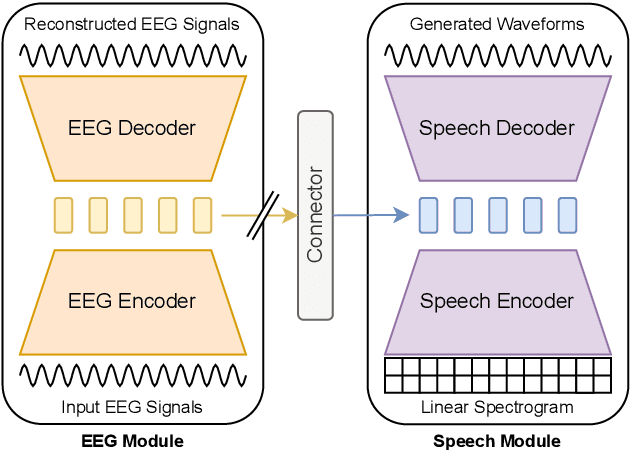



Speech decoding from EEG signals is a challenging task, where brain activity is modeled to estimate salient characteristics of acoustic stimuli. We propose FESDE, a novel framework for Fully-End-to-end Speech Decoding from EEG signals. Our approach aims to directly reconstruct listened speech waveforms given EEG signals, where no intermediate acoustic feature processing step is required. The proposed method consists of an EEG module and a speech module along with a connector. The EEG module learns to better represent EEG signals, while the speech module generates speech waveforms from model representations. The connector learns to bridge the distributions of the latent spaces of EEG and speech. The proposed framework is both simple and efficient, by allowing single-step inference, and outperforms prior works on objective metrics. A fine-grained phoneme analysis is conducted to unveil model characteristics of speech decoding. The source code is available here: github.com/lee-jhwn/fesde.
A Multi-Perspective Machine Learning Approach to Evaluate Police-Driver Interaction in Los Angeles
Feb 08, 2024Interactions between the government officials and civilians affect public wellbeing and the state legitimacy that is necessary for the functioning of democratic society. Police officers, the most visible and contacted agents of the state, interact with the public more than 20 million times a year during traffic stops. Today, these interactions are regularly recorded by body-worn cameras (BWCs), which are lauded as a means to enhance police accountability and improve police-public interactions. However, the timely analysis of these recordings is hampered by a lack of reliable automated tools that can enable the analysis of these complex and contested police-public interactions. This article proposes an approach to developing new multi-perspective, multimodal machine learning (ML) tools to analyze the audio, video, and transcript information from this BWC footage. Our approach begins by identifying the aspects of communication most salient to different stakeholders, including both community members and police officers. We move away from modeling approaches built around the existence of a single ground truth and instead utilize new advances in soft labeling to incorporate variation in how different observers perceive the same interactions. We argue that this inclusive approach to the conceptualization and design of new ML tools is broadly applicable to the study of communication and development of analytic tools across domains of human interaction, including education, medicine, and the workplace.