 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSCARD -- Causal Reasoning and De-confounding for Multimodal Opportunistic Screening of Cardiovascular Adverse Events
Jun 23, 2025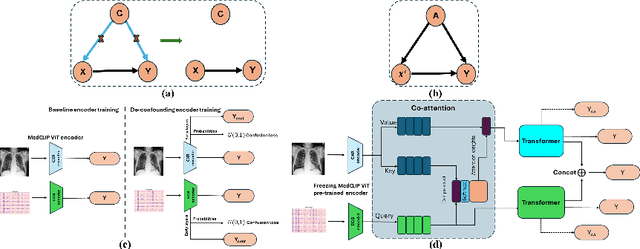
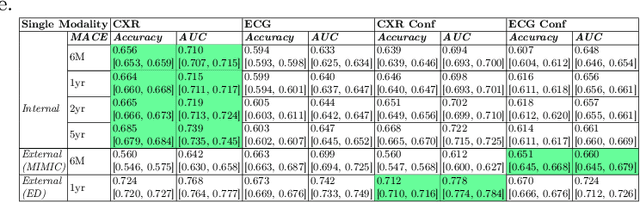


Major Adverse Cardiovascular Events (MACE) remain the leading cause of mortality globally, as reported in the Global Disease Burden Study 2021. Opportunistic screening leverages data collected from routine health check-ups and multimodal data can play a key role to identify at-risk individuals. Chest X-rays (CXR) provide insights into chronic conditions contributing to major adverse cardiovascular events (MACE), while 12-lead electrocardiogram (ECG) directly assesses cardiac electrical activity and structural abnormalities. Integrating CXR and ECG could offer a more comprehensive risk assessment than conventional models, which rely on clinical scores, computed tomography (CT) measurements, or biomarkers, which may be limited by sampling bias and single modality constraints. We propose a novel predictive modeling framework - MOSCARD, multimodal causal reasoning with co-attention to align two distinct modalities and simultaneously mitigate bias and confounders in opportunistic risk estimation. Primary technical contributions are - (i) multimodal alignment of CXR with ECG guidance; (ii) integration of causal reasoning; (iii) dual back-propagation graph for de-confounding. Evaluated on internal, shift data from emergency department (ED) and external MIMIC datasets, our model outperformed single modality and state-of-the-art foundational models - AUC: 0.75, 0.83, 0.71 respectively. Proposed cost-effective opportunistic screening enables early intervention, improving patient outcomes and reducing disparities.
Position: Restructuring of Categories and Implementation of Guidelines Essential for VLM Adoption in Healthcare
May 12, 2025The intricate and multifaceted nature of vision language model (VLM) development, adaptation, and application necessitates the establishment of clear and standardized reporting protocols, particularly within the high-stakes context of healthcare. Defining these reporting standards is inherently challenging due to the diverse nature of studies involving VLMs, which vary significantly from the development of all new VLMs or finetuning for domain alignment to off-the-shelf use of VLM for targeted diagnosis and prediction tasks. In this position paper, we argue that traditional machine learning reporting standards and evaluation guidelines must be restructured to accommodate multiphase VLM studies; it also has to be organized for intuitive understanding of developers while maintaining rigorous standards for reproducibility. To facilitate community adoption, we propose a categorization framework for VLM studies and outline corresponding reporting standards that comprehensively address performance evaluation, data reporting protocols, and recommendations for manuscript composition. These guidelines are organized according to the proposed categorization scheme. Lastly, we present a checklist that consolidates reporting standards, offering a standardized tool to ensure consistency and quality in the publication of VLM-related research.
Can Generic LLMs Help Analyze Child-adult Interactions Involving Children with Autism in Clinical Observation?
Nov 16, 2024



Large Language Models (LLMs) have shown significant potential in understanding human communication and interaction. However, their performance in the domain of child-inclusive interactions, including in clinical settings, remains less explored. In this work, we evaluate generic LLMs' ability to analyze child-adult dyadic interactions in a clinically relevant context involving children with ASD. Specifically, we explore LLMs in performing four tasks: classifying child-adult utterances, predicting engaged activities, recognizing language skills and understanding traits that are clinically relevant. Our evaluation shows that generic LLMs are highly capable of analyzing long and complex conversations in clinical observation sessions, often surpassing the performance of non-expert human evaluators. The results show their potential to segment interactions of interest, assist in language skills evaluation, identify engaged activities, and offer clinical-relevant context for assessments.
Evaluation of state-of-the-art ASR Models in Child-Adult Interactions
Sep 24, 2024



The ability to reliably transcribe child-adult conversations in a clinical setting is valuable for diagnosis and understanding of numerous developmental disorders such as Autism Spectrum Disorder. Recent advances in deep learning architectures and availability of large scale transcribed data has led to development of speech foundation models that have shown dramatic improvements in ASR performance. However, the ability of these models to translate well to conversational child-adult interactions is under studied. In this work, we provide a comprehensive evaluation of ASR performance on a dataset containing child-adult interactions from autism diagnostic sessions, using Whisper, Wav2Vec2, HuBERT, and WavLM. We find that speech foundation models show a noticeable performance drop (15-20% absolute WER) for child speech compared to adult speech in the conversational setting. Then, we employ LoRA on the best performing zero shot model (whisper-large) to probe the effectiveness of fine-tuning in a low resource setting, resulting in ~8% absolute WER improvement for child speech and ~13% absolute WER improvement for adult speech.
Robust Self Supervised Speech Embeddings for Child-Adult Classification in Interactions involving Children with Autism
Jul 31, 2023We address the problem of detecting who spoke when in child-inclusive spoken interactions i.e., automatic child-adult speaker classification. Interactions involving children are richly heterogeneous due to developmental differences. The presence of neurodiversity e.g., due to Autism, contributes additional variability. We investigate the impact of additional pre-training with more unlabelled child speech on the child-adult classification performance. We pre-train our model with child-inclusive interactions, following two recent self-supervision algorithms, Wav2vec 2.0 and WavLM, with a contrastive loss objective. We report 9 - 13% relative improvement over the state-of-the-art baseline with regards to classification F1 scores on two clinical interaction datasets involving children with Autism. We also analyze the impact of pre-training under different conditions by evaluating our model on interactions involving different subgroups of children based on various demographic factors.
Understanding Spoken Language Development of Children with ASD Using Pre-trained Speech Embeddings
May 23, 2023Speech processing techniques are useful for analyzing speech and language development in children with Autism Spectrum Disorder (ASD), who are often varied and delayed in acquiring these skills. Early identification and intervention are crucial, but traditional assessment methodologies such as caregiver reports are not adequate for the requisite behavioral phenotyping. Natural Language Sample (NLS) analysis has gained attention as a promising complement. Researchers have developed benchmarks for spoken language capabilities in children with ASD, obtainable through the analysis of NLS. This paper proposes applications of speech processing technologies in support of automated assessment of children's spoken language development by classification between child and adult speech and between speech and nonverbal vocalization in NLS, with respective F1 macro scores of 82.6% and 67.8%, underscoring the potential for accurate and scalable tools for ASD research and clinical use.
A Context-Aware Computational Approach for Measuring Vocal Entrainment in Dyadic Conversations
Nov 07, 2022



Vocal entrainment is a social adaptation mechanism in human interaction, knowledge of which can offer useful insights to an individual's cognitive-behavioral characteristics. We propose a context-aware approach for measuring vocal entrainment in dyadic conversations. We use conformers(a combination of convolutional network and transformer) for capturing both short-term and long-term conversational context to model entrainment patterns in interactions across different domains. Specifically we use cross-subject attention layers to learn intra- as well as inter-personal signals from dyadic conversations. We first validate the proposed method based on classification experiments to distinguish between real(consistent) and fake(inconsistent/shuffled) conversations. Experimental results on interactions involving individuals with Autism Spectrum Disorder also show evidence of a statistically-significant association between the introduced entrainment measure and clinical scores relevant to symptoms, including across gender and age groups.
Multilingual Speech Recognition using Knowledge Transfer across Learning Processes
Oct 15, 2021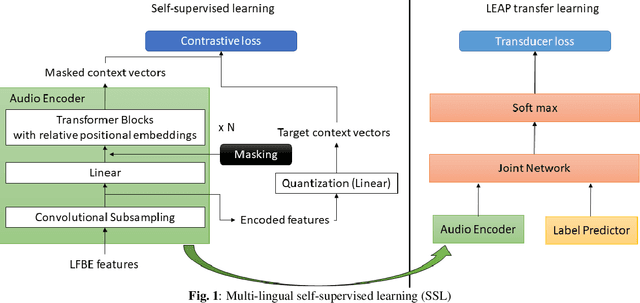
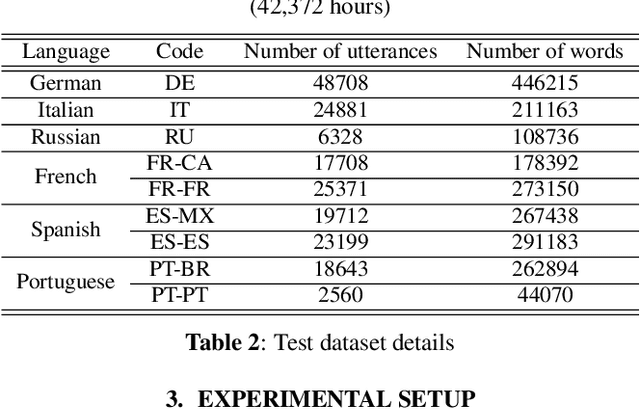
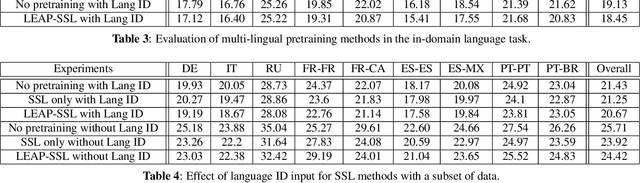
Multilingual end-to-end(E2E) models have shown a great potential in the expansion of the language coverage in the realm of automatic speech recognition(ASR). In this paper, we aim to enhance the multilingual ASR performance in two ways, 1)studying the impact of feeding a one-hot vector identifying the language, 2)formulating the task with a meta-learning objective combined with self-supervised learning (SSL). We associate every language with a distinct task manifold and attempt to improve the performance by transferring knowledge across learning processes itself as compared to transferring through final model parameters. We employ this strategy on a dataset comprising of 6 languages for an in-domain ASR task, by minimizing an objective related to expected gradient path length. Experimental results reveal the best pre-training strategy resulting in 3.55% relative reduction in overall WER. A combination of LEAP and SSL yields 3.51% relative reduction in overall WER when using language ID.
Understanding of Emotion Perception from Art
Oct 13, 2021
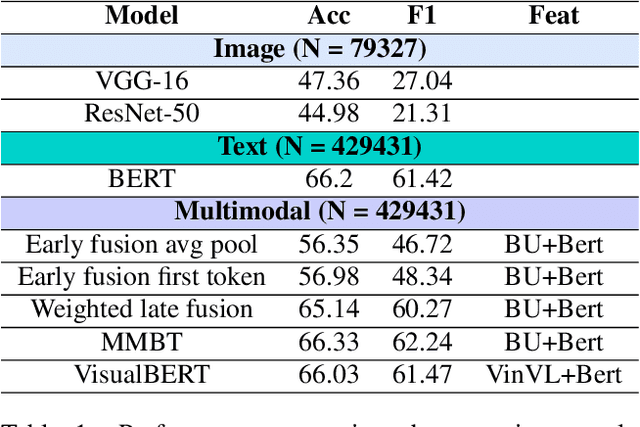

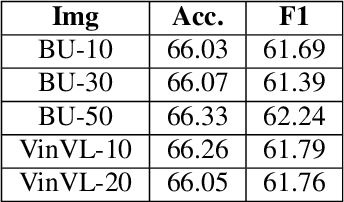
Computational modeling of the emotions evoked by art in humans is a challenging problem because of the subjective and nuanced nature of art and affective signals. In this paper, we consider the above-mentioned problem of understanding emotions evoked in viewers by artwork using both text and visual modalities. Specifically, we analyze images and the accompanying text captions from the viewers expressing emotions as a multimodal classification task. Our results show that single-stream multimodal transformer-based models like MMBT and VisualBERT perform better compared to both image-only models and dual-stream multimodal models having separate pathways for text and image modalities. We also observe improvements in performance for extreme positive and negative emotion classes, when a single-stream model like MMBT is compared with a text-only transformer model like BERT.
Learning Domain Invariant Representations for Child-Adult Classification from Speech
Oct 25, 2019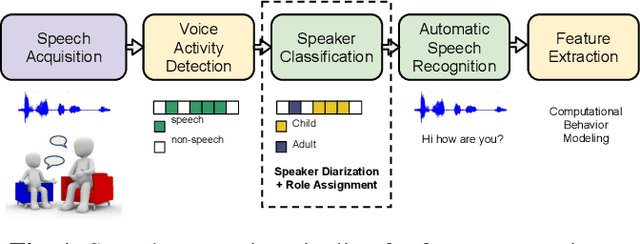
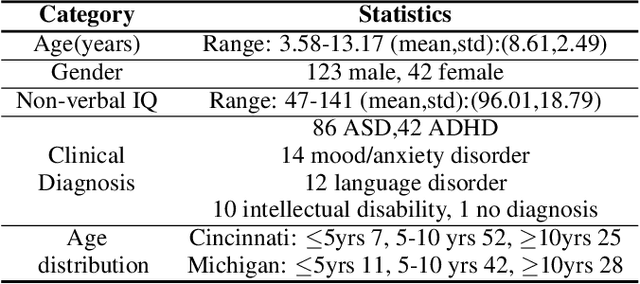

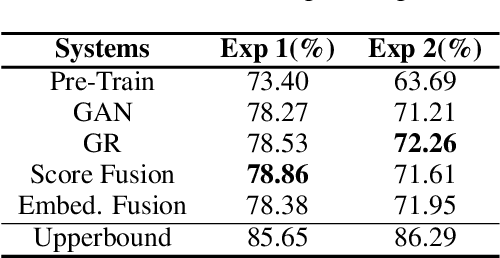
Diagnostic procedures for ASD (autism spectrum disorder) involve semi-naturalistic interactions between the child and a clinician. Computational methods to analyze these sessions require an end-to-end speech and language processing pipeline that go from raw audio to clinically-meaningful behavioral features. An important component of this pipeline is the ability to automatically detect who is speaking when i.e., perform child-adult speaker classification. This binary classification task is often confounded due to variability associated with the participants' speech and background conditions. Further, scarcity of training data often restricts direct application of conventional deep learning methods. In this work, we address two major sources of variability - age of the child and data source collection location - using domain adversarial learning which does not require labeled target domain data. We use two methods, generative adversarial training with inverted label loss and gradient reversal layer to learn speaker embeddings invariant to the above sources of variability, and analyze different conditions under which the proposed techniques improve over conventional learning methods. Using a large corpus of ADOS-2 (autism diagnostic observation schedule, 2nd edition) sessions, we demonstrate upto 13.45% and 6.44% relative improvements over conventional learning methods.