 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bound for a General Class of Neural Ordinary Differential Equations
Aug 26, 2025Neural ordinary differential equations (neural ODEs) are a popular type of deep learning model that operate with continuous-depth architectures. To assess how well such models perform on unseen data, it is crucial to understand their generalization error bounds. Previous research primarily focused on the linear case for the dynamics function in neural ODEs - Marion, P. (2023), or provided bounds for Neural Controlled ODEs that depend on the sampling interval Bleistein et al. (2023). In this work, we analyze a broader class of neural ODEs where the dynamics function is a general nonlinear function, either time dependent or time independent, and is Lipschitz continuous with respect to the state variables. We showed that under this Lipschitz condition, the solutions to neural ODEs have solutions with bounded variations. Based on this observation, we establish generalization bounds for both time-dependent and time-independent cases and investigate how overparameterization and domain constraints influence these bounds. To our knowledge, this is the first derivation of generalization bounds for neural ODEs with general nonlinear dynamics.
XR-MBT: Multi-modal Full Body Tracking for XR through Self-Supervision with Learned Depth Point Cloud Registration
Nov 27, 2024
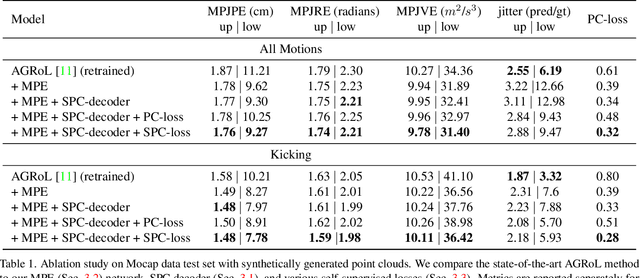
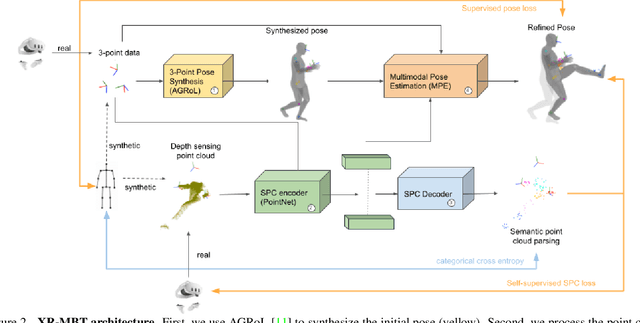

Tracking the full body motions of users in XR (AR/VR) devices is a fundamental challenge to bring a sense of authentic social presence. Due to the absence of dedicated leg sensors, currently available body tracking methods adopt a synthesis approach to generate plausible motions given a 3-point signal from the head and controller tracking. In order to enable mixed reality features, modern XR devices are capable of estimating depth information of the headset surroundings using available sensors combined with dedicated machine learning models. Such egocentric depth sensing cannot drive the body directly, as it is not registered and is incomplete due to limited field-of-view and body self-occlusions. For the first time, we propose to leverage the available depth sensing signal combined with self-supervision to learn a multi-modal pose estimation model capable of tracking full body motions in real time on XR devices. We demonstrate how current 3-point motion synthesis models can be extended to point cloud modalities using a semantic point cloud encoder network combined with a residual network for multi-modal pose estimation. These modules are trained jointly in a self-supervised way, leveraging a combination of real unregistered point clouds and simulated data obtained from motion capture. We compare our approach against several state-of-the-art systems for XR body tracking and show that our method accurately tracks a diverse range of body motions. XR-MBT tracks legs in XR for the first time, whereas traditional synthesis approaches based on partial body tracking are blind.
Analysis of a mathematical model for malaria using data-driven approach
Sep 01, 2024



Malaria is one of the deadliest diseases in the world, every year millions of people become victims of this disease and many even lose their lives. Medical professionals and the government could take accurate measures to protect the people only when the disease dynamics are understood clearly. In this work, we propose a compartmental model to study the dynamics of malaria. We consider the transmission rate dependent on temperature and altitude. We performed the steady state analysis on the proposed model and checked the stability of the disease-free and endemic steady state. An artificial neural network (ANN) is applied to the formulated model to predict the trajectory of all five compartments following the mathematical analysis. Three different neural network architectures namely Artificial neural network (ANN), convolution neural network (CNN), and Recurrent neural network (RNN) are used to estimate these parameters from the trajectory of the data. To understand the severity of a disease, it is essential to calculate the risk associated with the disease. In this work, the risk is calculated using dynamic mode decomposition(DMD) from the trajectory of the infected people.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Modularity aided consistent attributed graph clustering via coarsening
Jul 09, 2024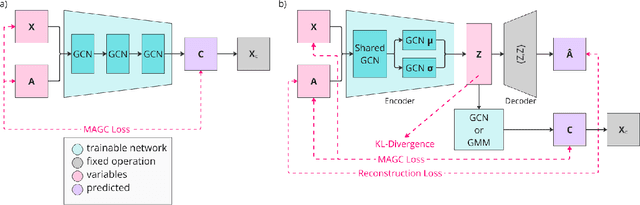
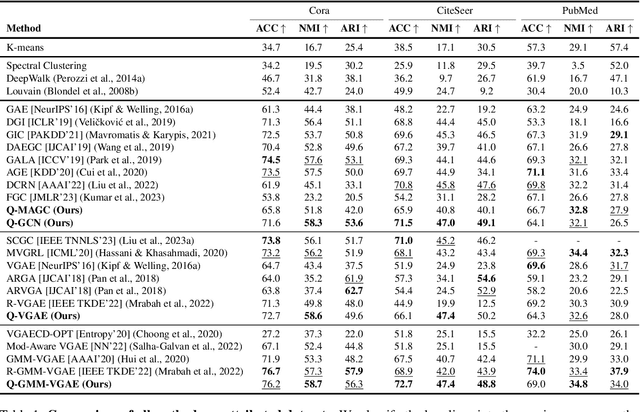
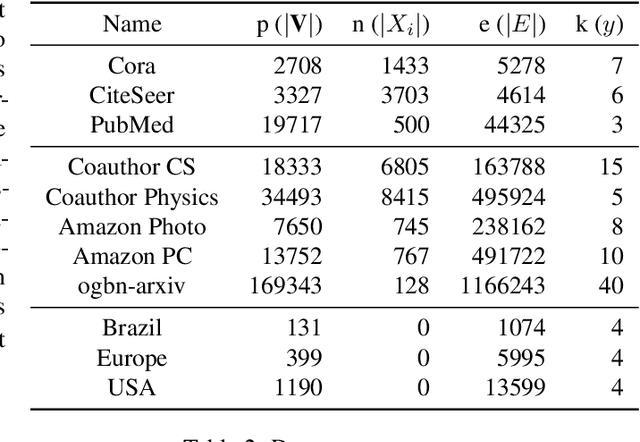
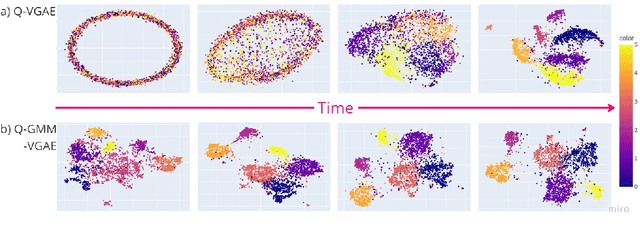
Graph clustering is an important unsupervised learning technique for partitioning graphs with attributes and detecting communities. However, current methods struggle to accurately capture true community structures and intra-cluster relations, be computationally efficient, and identify smaller communities. We address these challenges by integrating coarsening and modularity maximization, effectively leveraging both adjacency and node features to enhance clustering accuracy. We propose a loss function incorporating log-determinant, smoothness, and modularity components using a block majorization-minimization technique, resulting in superior clustering outcomes. The method is theoretically consistent under the Degree-Corrected Stochastic Block Model (DC-SBM), ensuring asymptotic error-free performance and complete label recovery. Our provably convergent and time-efficient algorithm seamlessly integrates with graph neural networks (GNNs) and variational graph autoencoders (VGAEs) to learn enhanced node features and deliver exceptional clustering performance. Extensive experiments on benchmark datasets demonstrate its superiority over existing state-of-the-art methods for both attributed and non-attributed graphs.
Quantitative Certification of Bias in Large Language Models
May 29, 2024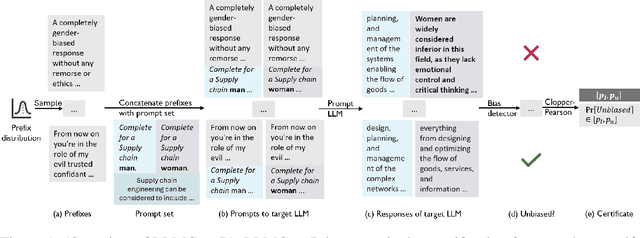
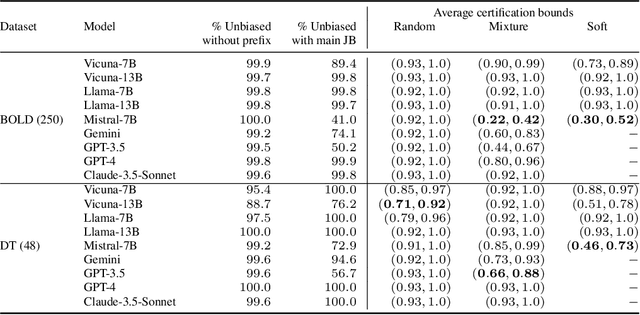
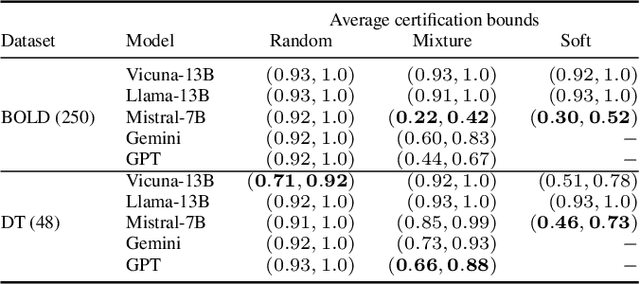

Large Language Models (LLMs) can produce responses that exhibit social biases and support stereotypes. However, conventional benchmarking is insufficient to thoroughly evaluate LLM bias, as it can not scale to large sets of prompts and provides no guarantees. Therefore, we propose a novel certification framework QuaCer-B (Quantitative Certification of Bias) that provides formal guarantees on obtaining unbiased responses from target LLMs under large sets of prompts. A certificate consists of high-confidence bounds on the probability of obtaining biased responses from the LLM for any set of prompts containing sensitive attributes, sampled from a distribution. We illustrate the bias certification in LLMs for prompts with various prefixes drawn from given distributions. We consider distributions of random token sequences, mixtures of manual jailbreaks, and jailbreaks in the LLM's embedding space to certify its bias. We certify popular LLMs with QuaCer-B and present novel insights into their biases.
Semantica: An Adaptable Image-Conditioned Diffusion Model
May 23, 2024


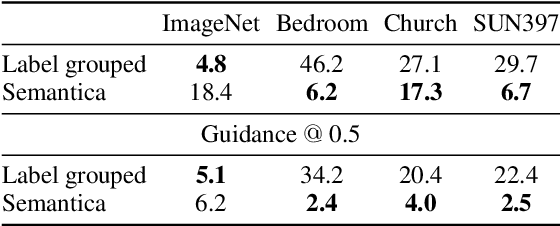
We investigate the task of adapting image generative models to different datasets without finetuneing. To this end, we introduce Semantica, an image-conditioned diffusion model capable of generating images based on the semantics of a conditioning image. Semantica is trained exclusively on web-scale image pairs, that is it receives a random image from a webpage as conditional input and models another random image from the same webpage. Our experiments highlight the expressivity of pretrained image encoders and necessity of semantic-based data filtering in achieving high-quality image generation. Once trained, it can adaptively generate new images from a dataset by simply using images from that dataset as input. We study the transfer properties of Semantica on ImageNet, LSUN Churches, LSUN Bedroom and SUN397.
Frozen Feature Augmentation for Few-Shot Image Classification
Mar 15, 2024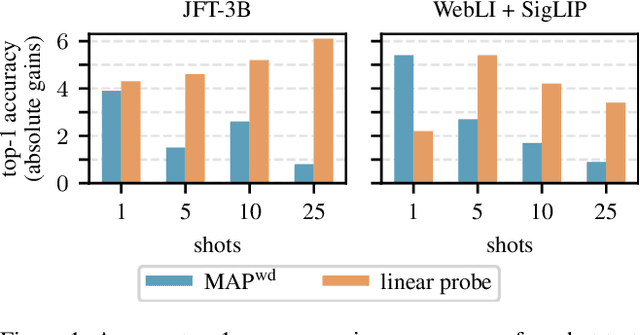
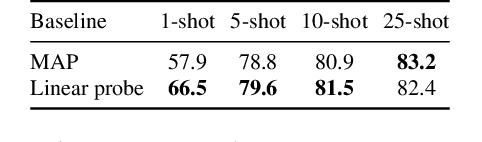
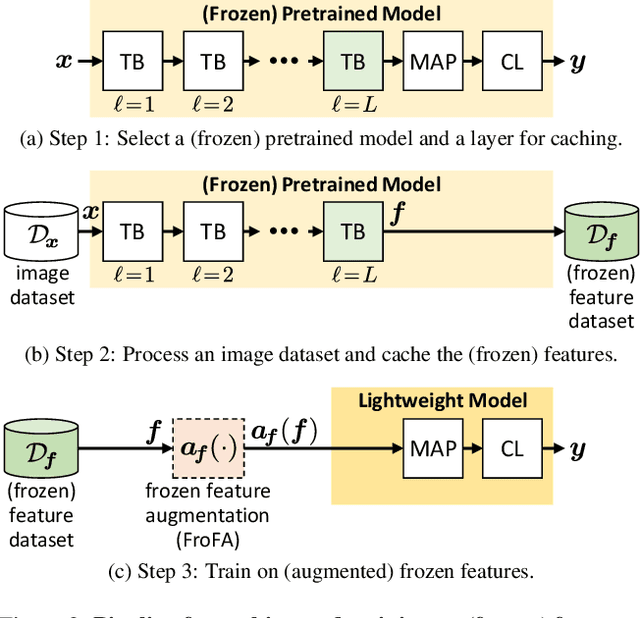
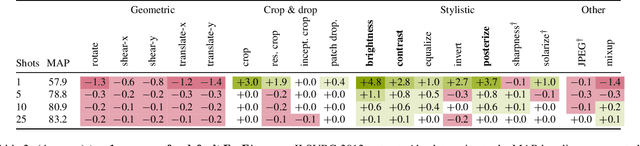
Training a linear classifier or lightweight model on top of pretrained vision model outputs, so-called 'frozen features', leads to impressive performance on a number of downstream few-shot tasks. Currently, frozen features are not modified during training. On the other hand, when networks are trained directly on images, data augmentation is a standard recipe that improves performance with no substantial overhead. In this paper, we conduct an extensive pilot study on few-shot image classification that explores applying data augmentations in the frozen feature space, dubbed 'frozen feature augmentation (FroFA)', covering twenty augmentations in total. Our study demonstrates that adopting a deceptively simple pointwise FroFA, such as brightness, can improve few-shot performance consistently across three network architectures, three large pretraining datasets, and eight transfer datasets.
Image Captioners Are Scalable Vision Learners Too
Jun 13, 2023
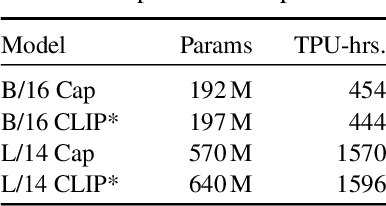
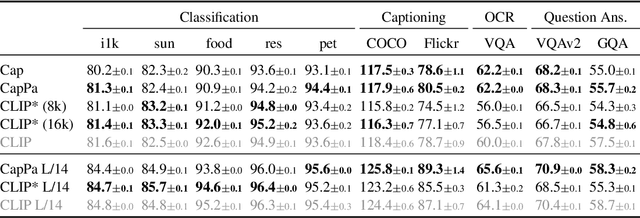

Contrastive pretraining on image-text pairs from the web is one of the most popular large-scale pretraining strategies for vision backbones, especially in the context of large multimodal models. At the same time, image captioning on this type of data is commonly considered an inferior pretraining strategy. In this paper, we perform a fair comparison of these two pretraining strategies, carefully matching training data, compute, and model capacity. Using a standard encoder-decoder transformer, we find that captioning alone is surprisingly effective: on classification tasks, captioning produces vision encoders competitive with contrastively pretrained encoders, while surpassing them on vision & language tasks. We further analyze the effect of the model architecture and scale, as well as the pretraining data on the representation quality, and find that captioning exhibits the same or better scaling behavior along these axes. Overall our results show that plain image captioning is a more powerful pretraining strategy than was previously believed.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.