 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recipe for Generating 3D Worlds From a Single Image
Mar 20, 2025

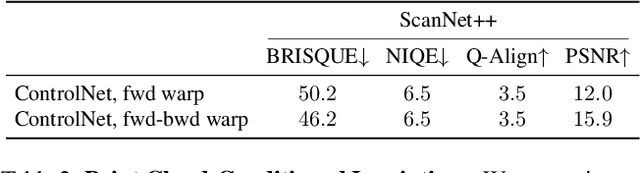

We introduce a recipe for generating immersive 3D worlds from a single image by framing the task as an in-context learning problem for 2D inpainting models. This approach requires minimal training and uses existing generative models. Our process involves two steps: generating coherent panoramas using a pre-trained diffusion model and lifting these into 3D with a metric depth estimator. We then fill unobserved regions by conditioning the inpainting model on rendered point clouds, requiring minimal fine-tuning. Tested on both synthetic and real images, our method produces high-quality 3D environments suitable for VR display. By explicitly modeling the 3D structure of the generated environment from the start, our approach consistently outperforms state-of-the-art, video synthesis-based methods along multiple quantitative image quality metrics. Project Page: https://katjaschwarz.github.io/worlds/
Deblur Gaussian Splatting SLAM
Mar 16, 2025We present Deblur-SLAM, a robust RGB SLAM pipeline designed to recover sharp reconstructions from motion-blurred inputs. The proposed method bridges the strengths of both frame-to-frame and frame-to-model approaches to model sub-frame camera trajectories that lead to high-fidelity reconstructions in motion-blurred settings. Moreover, our pipeline incorporates techniques such as online loop closure and global bundle adjustment to achieve a dense and precise global trajectory. We model the physical image formation process of motion-blurred images and minimize the error between the observed blurry images and rendered blurry images obtained by averaging sharp virtual sub-frame images. Additionally, by utilizing a monocular depth estimator alongside the online deformation of Gaussians, we ensure precise mapping and enhanced image deblurring. The proposed SLAM pipeline integrates all these components to improve the results. We achieve state-of-the-art results for sharp map estimation and sub-frame trajectory recovery both on synthetic and real-world blurry input data.
Explaining Human Preferences via Metrics for Structured 3D Reconstruction
Mar 11, 2025



"What cannot be measured cannot be improved" while likely never uttered by Lord Kelvin, summarizes effectively the purpose of this work. This paper presents a detailed evaluation of automated metrics for evaluating structured 3D reconstructions. Pitfalls of each metric are discussed, and a thorough analyses through the lens of expert 3D modelers' preferences is presented. A set of systematic "unit tests" are proposed to empirically verify desirable properties, and context aware recommendations as to which metric to use depending on application are provided. Finally, a learned metric distilled from human expert judgments is proposed and analyzed.
XR-MBT: Multi-modal Full Body Tracking for XR through Self-Supervision with Learned Depth Point Cloud Registration
Nov 27, 2024
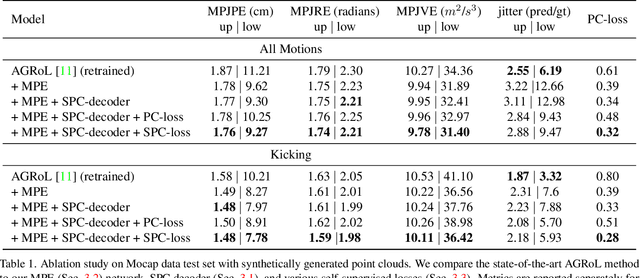
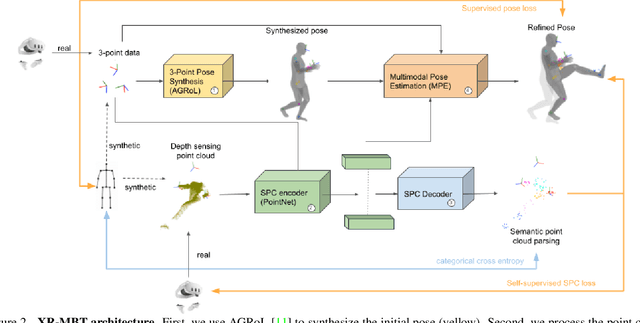

Tracking the full body motions of users in XR (AR/VR) devices is a fundamental challenge to bring a sense of authentic social presence. Due to the absence of dedicated leg sensors, currently available body tracking methods adopt a synthesis approach to generate plausible motions given a 3-point signal from the head and controller tracking. In order to enable mixed reality features, modern XR devices are capable of estimating depth information of the headset surroundings using available sensors combined with dedicated machine learning models. Such egocentric depth sensing cannot drive the body directly, as it is not registered and is incomplete due to limited field-of-view and body self-occlusions. For the first time, we propose to leverage the available depth sensing signal combined with self-supervision to learn a multi-modal pose estimation model capable of tracking full body motions in real time on XR devices. We demonstrate how current 3-point motion synthesis models can be extended to point cloud modalities using a semantic point cloud encoder network combined with a residual network for multi-modal pose estimation. These modules are trained jointly in a self-supervised way, leveraging a combination of real unregistered point clouds and simulated data obtained from motion capture. We compare our approach against several state-of-the-art systems for XR body tracking and show that our method accurately tracks a diverse range of body motions. XR-MBT tracks legs in XR for the first time, whereas traditional synthesis approaches based on partial body tracking are blind.
Retrieval Robust to Object Motion Blur
Apr 27, 2024
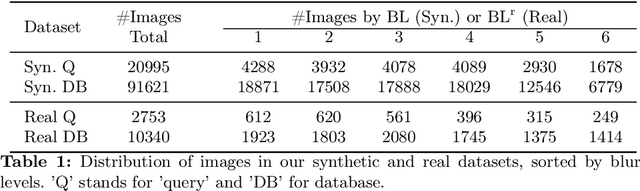

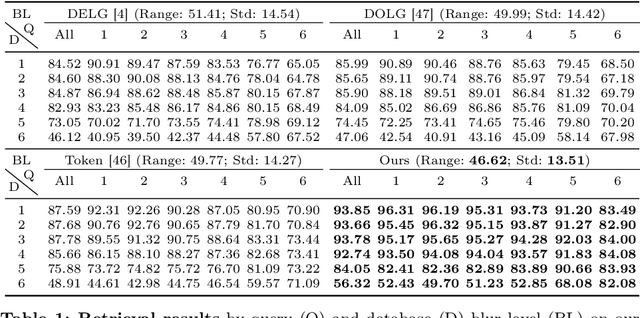
Moving objects are frequently seen in daily life and usually appear blurred in images due to their motion. While general object retrieval is a widely explored area in computer vision, it primarily focuses on sharp and static objects, and retrieval of motion-blurred objects in large image collections remains unexplored. We propose a method for object retrieval in images that are affected by motion blur. The proposed method learns a robust representation capable of matching blurred objects to their deblurred versions and vice versa. To evaluate our approach, we present the first large-scale datasets for blurred object retrieval, featuring images with objects exhibiting varying degrees of blur in various poses and scales. We conducted extensive experiments, showing that our method outperforms state-of-the-art retrieval methods on the new blur-retrieval datasets, which validates the effectiveness of the proposed approach.
Estimating Generic 3D Room Structures from 2D Annotations
Jun 15, 2023



Indoor rooms are among the most common use cases in 3D scene understanding. Current state-of-the-art methods for this task are driven by large annotated datasets. Room layouts are especially important, consisting of structural elements in 3D, such as wall, floor, and ceiling. However, they are difficult to annotate, especially on pure RGB video. We propose a novel method to produce generic 3D room layouts just from 2D segmentation masks, which are easy to annotate for humans. Based on these 2D annotations, we automatically reconstruct 3D plane equations for the structural elements and their spatial extent in the scene, and connect adjacent elements at the appropriate contact edges. We annotate and publicly release 2266 3D room layouts on the RealEstate10k dataset, containing YouTube videos. We demonstrate the high quality of these 3D layouts annotations with extensive experiments.
Tracking by 3D Model Estimation of Unknown Objects in Videos
Apr 13, 2023
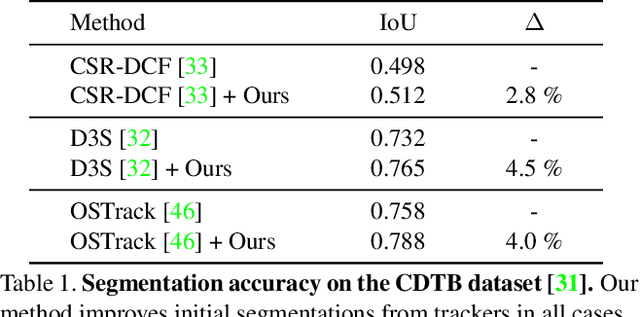
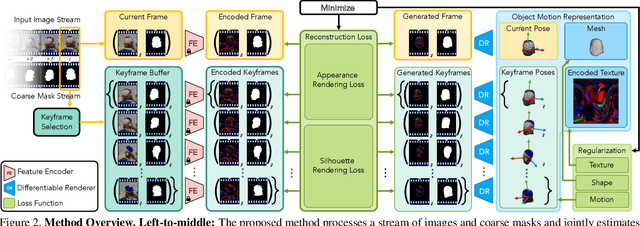
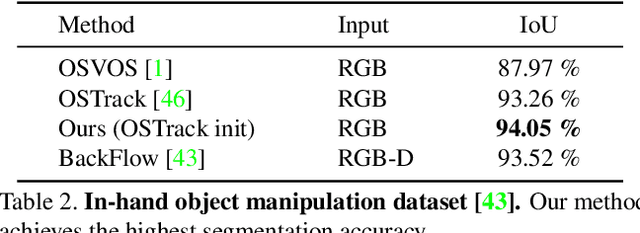
Most model-free visual object tracking methods formulate the tracking task as object location estimation given by a 2D segmentation or a bounding box in each video frame. We argue that this representation is limited and instead propose to guide and improve 2D tracking with an explicit object representation, namely the textured 3D shape and 6DoF pose in each video frame. Our representation tackles a complex long-term dense correspondence problem between all 3D points on the object for all video frames, including frames where some points are invisible. To achieve that, the estimation is driven by re-rendering the input video frames as well as possible through differentiable rendering, which has not been used for tracking before. The proposed optimization minimizes a novel loss function to estimate the best 3D shape, texture, and 6DoF pose. We improve the state-of-the-art in 2D segmentation tracking on three different datasets with mostly rigid objects.
Human from Blur: Human Pose Tracking from Blurry Images
Mar 30, 2023We propose a method to estimate 3D human poses from substantially blurred images. The key idea is to tackle the inverse problem of image deblurring by modeling the forward problem with a 3D human model, a texture map, and a sequence of poses to describe human motion. The blurring process is then modeled by a temporal image aggregation step. Using a differentiable renderer, we can solve the inverse problem by backpropagating the pixel-wise reprojection error to recover the best human motion representation that explains a single or multiple input images. Since the image reconstruction loss alone is insufficient, we present additional regularization terms. To the best of our knowledge, we present the first method to tackle this problem. Our method consistently outperforms other methods on significantly blurry inputs since they lack one or multiple key functionalities that our method unifies, i.e. image deblurring with sub-frame accuracy and explicit 3D modeling of non-rigid human motion.
Motion-from-Blur: 3D Shape and Motion Estimation of Motion-blurred Objects in Videos
Nov 29, 2021
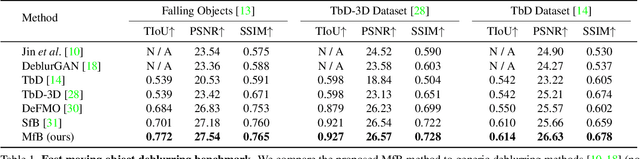
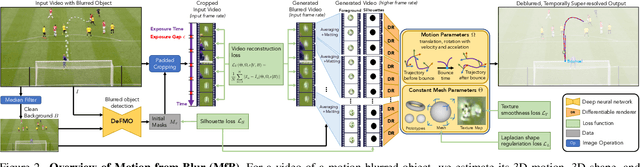
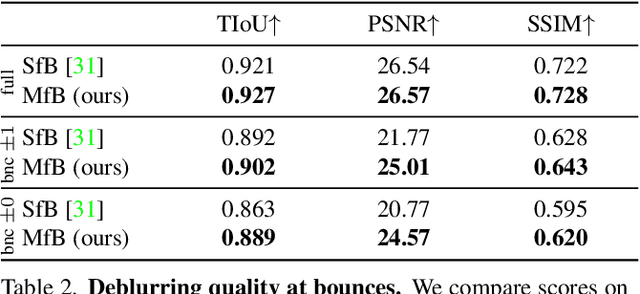
We propose a method for jointly estimating the 3D motion, 3D shape, and appearance of highly motion-blurred objects from a video. To this end, we model the blurred appearance of a fast moving object in a generative fashion by parametrizing its 3D position, rotation, velocity, acceleration, bounces, shape, and texture over the duration of a predefined time window spanning multiple frames. Using differentiable rendering, we are able to estimate all parameters by minimizing the pixel-wise reprojection error to the input video via backpropagating through a rendering pipeline that accounts for motion blur by averaging the graphics output over short time intervals. For that purpose, we also estimate the camera exposure gap time within the same optimization. To account for abrupt motion changes like bounces, we model the motion trajectory as a piece-wise polynomial, and we are able to estimate the specific time of the bounce at sub-frame accuracy. Experiments on established benchmark datasets demonstrate that our method outperforms previous methods for fast moving object deblurring and 3D reconstruction.
Shape from Blur: Recovering Textured 3D Shape and Motion of Fast Moving Objects
Jun 16, 2021
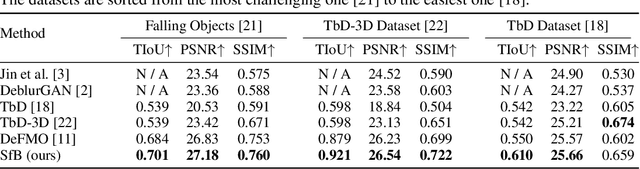
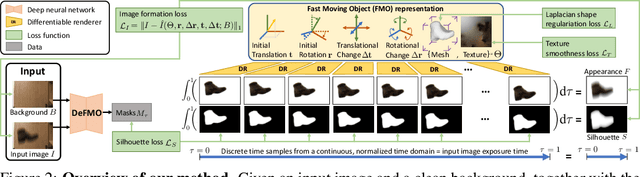
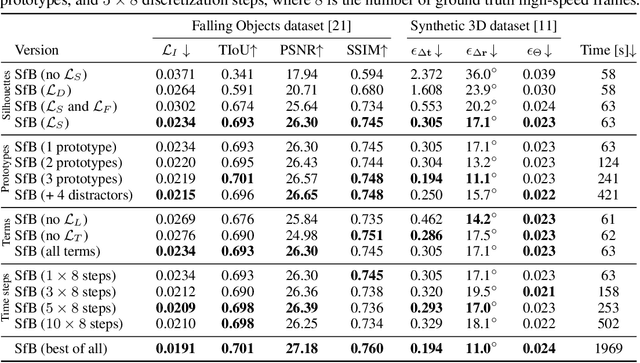
We address the novel task of jointly reconstructing the 3D shape, texture, and motion of an object from a single motion-blurred image. While previous approaches address the deblurring problem only in the 2D image domain, our proposed rigorous modeling of all object properties in the 3D domain enables the correct description of arbitrary object motion. This leads to significantly better image decomposition and sharper deblurring results. We model the observed appearance of a motion-blurred object as a combination of the background and a 3D object with constant translation and rotation. Our method minimizes a loss on reconstructing the input image via differentiable rendering with suitable regularizers. This enables estimating the textured 3D mesh of the blurred object with high fidelity. Our method substantially outperforms competing approaches on several benchmarks for fast moving objects deblurring. Qualitative results show that the reconstructed 3D mesh generates high-quality temporal super-resolution and novel views of the deblurred object.