 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXR-MBT: Multi-modal Full Body Tracking for XR through Self-Supervision with Learned Depth Point Cloud Registration
Nov 27, 2024
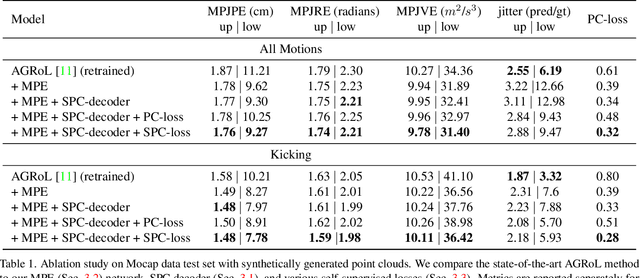
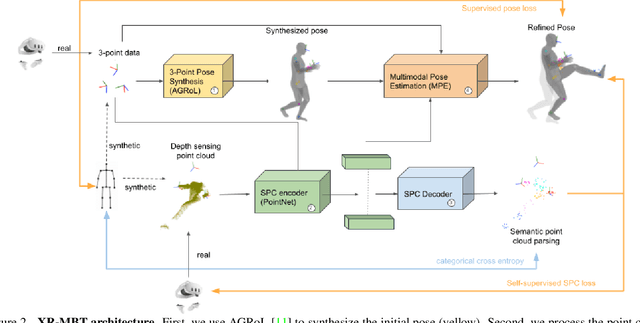

Tracking the full body motions of users in XR (AR/VR) devices is a fundamental challenge to bring a sense of authentic social presence. Due to the absence of dedicated leg sensors, currently available body tracking methods adopt a synthesis approach to generate plausible motions given a 3-point signal from the head and controller tracking. In order to enable mixed reality features, modern XR devices are capable of estimating depth information of the headset surroundings using available sensors combined with dedicated machine learning models. Such egocentric depth sensing cannot drive the body directly, as it is not registered and is incomplete due to limited field-of-view and body self-occlusions. For the first time, we propose to leverage the available depth sensing signal combined with self-supervision to learn a multi-modal pose estimation model capable of tracking full body motions in real time on XR devices. We demonstrate how current 3-point motion synthesis models can be extended to point cloud modalities using a semantic point cloud encoder network combined with a residual network for multi-modal pose estimation. These modules are trained jointly in a self-supervised way, leveraging a combination of real unregistered point clouds and simulated data obtained from motion capture. We compare our approach against several state-of-the-art systems for XR body tracking and show that our method accurately tracks a diverse range of body motions. XR-MBT tracks legs in XR for the first time, whereas traditional synthesis approaches based on partial body tracking are blind.
fMPI: Fast Novel View Synthesis in the Wild with Layered Scene Representations
Dec 26, 2023



In this study, we propose two novel input processing paradigms for novel view synthesis (NVS) methods based on layered scene representations that significantly improve their runtime without compromising quality. Our approach identifies and mitigates the two most time-consuming aspects of traditional pipelines: building and processing the so-called plane sweep volume (PSV), which is a high-dimensional tensor of planar re-projections of the input camera views. In particular, we propose processing this tensor in parallel groups for improved compute efficiency as well as super-sampling adjacent input planes to generate denser, and hence more accurate scene representation. The proposed enhancements offer significant flexibility, allowing for a balance between performance and speed, thus making substantial steps toward real-time applications. Furthermore, they are very general in the sense that any PSV-based method can make use of them, including methods that employ multiplane images, multisphere images, and layered depth images. In a comprehensive set of experiments, we demonstrate that our proposed paradigms enable the design of an NVS method that achieves state-of-the-art on public benchmarks while being up to $50x$ faster than existing state-of-the-art methods. It also beats the current forerunner in terms of speed by over $3x$, while achieving significantly better rendering quality.
Multimodal deep networks for text and image-based document classification
Jul 15, 2019


Classification of document images is a critical step for archival of old manuscripts, online subscription and administrative procedures. Computer vision and deep learning have been suggested as a first solution to classify documents based on their visual appearance. However, achieving the fine-grained classification that is required in real-world setting cannot be achieved by visual analysis alone. Often, the relevant information is in the actual text content of the document. We design a multimodal neural network that is able to learn from word embeddings, computed on text extracted by OCR, and from the image. We show that this approach boosts pure image accuracy by 3% on Tobacco3482 and RVL-CDIP augmented by our new QS-OCR text dataset (https://github.com/Quicksign/ocrized-text-dataset), even without clean text information.