 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
Space-Time-Modulated Wideband Radiation-Type Programmable Metasurface for Low Sidelobe Beamforming
Dec 06, 2024



Programmable metasurfaces promise a great potential to construct low-cost phased array systems due to the capability of elaborate modulation over electromagnetic (EM) waves. However, they are in either reflective or transmissive mode, and usually possess a relatively high profile as a result of the external feed source. Besides, it is difficult to conduct multibit phase shift in metasurfaces, when comparing with conventional phased arrays. Here, we propose a strategy of space-time modulated wideband radiation-type programmable metasurface for low side-lobe beamforming. The wideband programmable metasurface avoids the space-feed external source required by its traditional counterpart, thus achieving a significant reduction of profile through integration of a highefficiency microwave-fed excitation network and metasurface. Furthermore, through introducing space-time-modulated strategy, the high-accuracy amplitude-phase weight algorithm can also be synchronously carried out on the first harmonic component for low side-lobe beam-scanning. Most importantly, adaptive beamforming and generation of interference null can further be created after analyzing the harmonic component characteristics of received signals.
XR-MBT: Multi-modal Full Body Tracking for XR through Self-Supervision with Learned Depth Point Cloud Registration
Nov 27, 2024
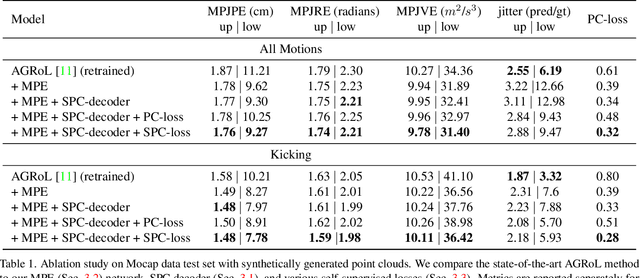
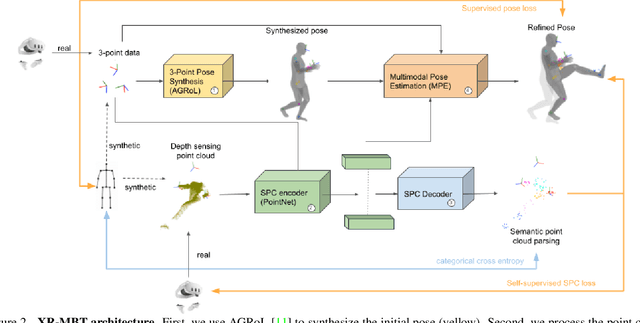

Tracking the full body motions of users in XR (AR/VR) devices is a fundamental challenge to bring a sense of authentic social presence. Due to the absence of dedicated leg sensors, currently available body tracking methods adopt a synthesis approach to generate plausible motions given a 3-point signal from the head and controller tracking. In order to enable mixed reality features, modern XR devices are capable of estimating depth information of the headset surroundings using available sensors combined with dedicated machine learning models. Such egocentric depth sensing cannot drive the body directly, as it is not registered and is incomplete due to limited field-of-view and body self-occlusions. For the first time, we propose to leverage the available depth sensing signal combined with self-supervision to learn a multi-modal pose estimation model capable of tracking full body motions in real time on XR devices. We demonstrate how current 3-point motion synthesis models can be extended to point cloud modalities using a semantic point cloud encoder network combined with a residual network for multi-modal pose estimation. These modules are trained jointly in a self-supervised way, leveraging a combination of real unregistered point clouds and simulated data obtained from motion capture. We compare our approach against several state-of-the-art systems for XR body tracking and show that our method accurately tracks a diverse range of body motions. XR-MBT tracks legs in XR for the first time, whereas traditional synthesis approaches based on partial body tracking are blind.
Using Motion Cues to Supervise Single-Frame Body Pose and Shape Estimation in Low Data Regimes
Feb 05, 2024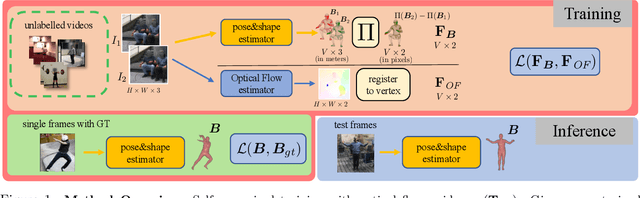
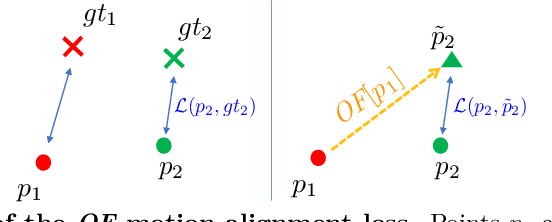
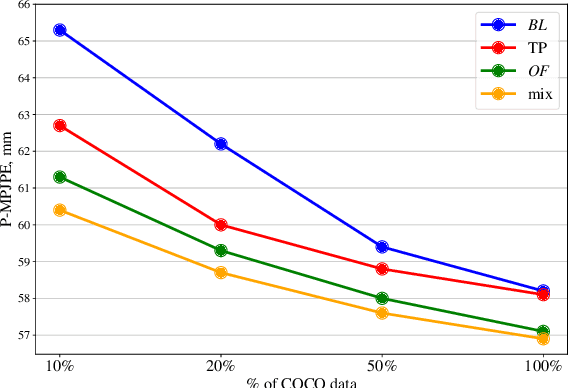
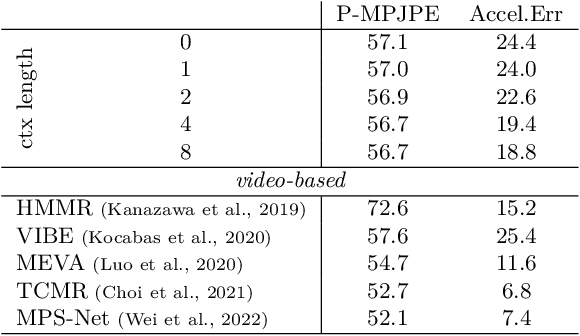
When enough annotated training data is available, supervised deep-learning algorithms excel at estimating human body pose and shape using a single camera. The effects of too little such data being available can be mitigated by using other information sources, such as databases of body shapes, to learn priors. Unfortunately, such sources are not always available either. We show that, in such cases, easy-to-obtain unannotated videos can be used instead to provide the required supervisory signals. Given a trained model using too little annotated data, we compute poses in consecutive frames along with the optical flow between them. We then enforce consistency between the image optical flow and the one that can be inferred from the change in pose from one frame to the next. This provides enough additional supervision to effectively refine the network weights and to perform on par with methods trained using far more annotated data.
A Phase-Coded Time-Domain Interleaved OTFS Waveform with Improved Ambiguity Function
Jul 26, 2023



Integrated sensing and communication (ISAC) is a significant application scenario in future wireless communication networks, and sensing is always evaluated by the ambiguity function. To enhance the sensing performance of the orthogonal time frequency space (OTFS) waveform, we propose a novel time-domain interleaved cyclic-shifted P4-coded OTFS (TICP4-OTFS) with improved ambiguity function. TICP4-OTFS can achieve superior autocorrelation features in both the time and frequency domains by exploiting the multicarrier-like form of OTFS after interleaved and the favorable autocorrelation attributes of the P4 code. Furthermore, we present the vectorized formulation of TICP4-OTFS modulation as well as its signal structure in each domain. Numerical simulations show that our proposed TICP4-OTFS waveform outperforms OTFS with a narrower mainlobe as well as lower and more distant sidelobes in terms of delay and Doppler-dimensional ambiguity functions, and an instance of range estimation using pulse compression is illustrated to exhibit the proposed waveform\u2019s greater resolution. Besides, TICP4-OTFS achieves better performance of bit error rate for communication in low signal-to-noise ratio (SNR) scenarios.
Data-Consistent Non-Cartesian Deep Subspace Learning for Efficient Dynamic MR Image Reconstruction
May 03, 2022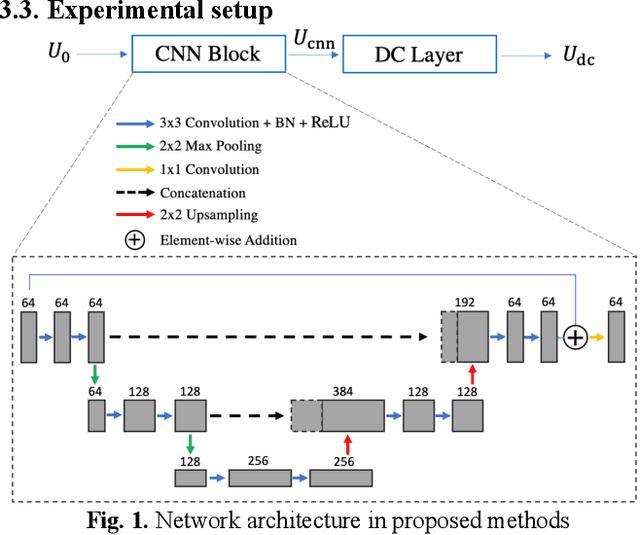
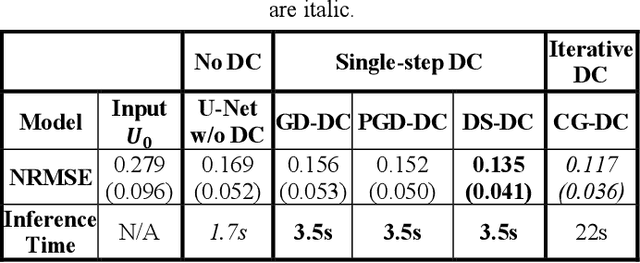
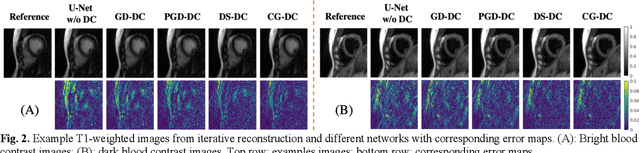
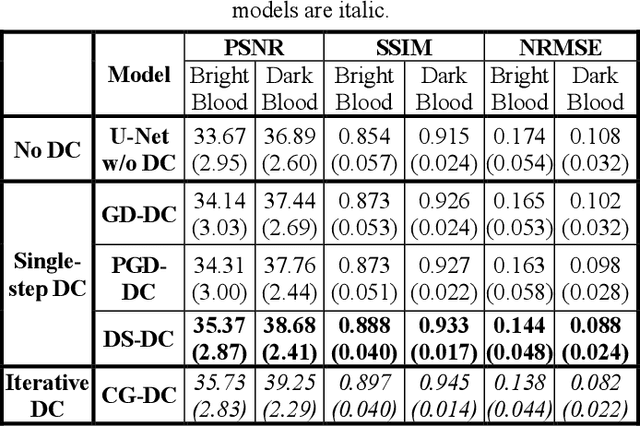
Non-Cartesian sampling with subspace-constrained image reconstruction is a popular approach to dynamic MRI, but slow iterative reconstruction limits its clinical application. Data-consistent (DC) deep learning can accelerate reconstruction with good image quality, but has not been formulated for non-Cartesian subspace imaging. In this study, we propose a DC non-Cartesian deep subspace learning framework for fast, accurate dynamic MR image reconstruction. Four novel DC formulations are developed and evaluated: two gradient decent approaches, a directly solved approach, and a conjugate gradient approach. We applied a U-Net model with and without DC layers to reconstruct T1-weighted images for cardiac MR Multitasking (an advanced multidimensional imaging method), comparing our results to the iteratively reconstructed reference. Experimental results show that the proposed framework significantly improves reconstruction accuracy over the U-Net model without DC, while significantly accelerating the reconstruction over conventional iterative reconstruction.
Improving Semi-Supervised and Domain-Adaptive Semantic Segmentation with Self-Supervised Depth Estimation
Aug 28, 2021



Training deep networks for semantic segmentation requires large amounts of labeled training data, which presents a major challenge in practice, as labeling segmentation masks is a highly labor-intensive process. To address this issue, we present a framework for semi-supervised and domain-adaptive semantic segmentation, which is enhanced by self-supervised monocular depth estimation (SDE) trained only on unlabeled image sequences. In particular, we utilize SDE as an auxiliary task comprehensively across the entire learning framework: First, we automatically select the most useful samples to be annotated for semantic segmentation based on the correlation of sample diversity and difficulty between SDE and semantic segmentation. Second, we implement a strong data augmentation by mixing images and labels using the geometry of the scene. Third, we transfer knowledge from features learned during SDE to semantic segmentation by means of transfer and multi-task learning. And fourth, we exploit additional labeled synthetic data with Cross-Domain DepthMix and Matching Geometry Sampling to align synthetic and real data. We validate the proposed model on the Cityscapes dataset, where all four contributions demonstrate significant performance gains, and achieve state-of-the-art results for semi-supervised semantic segmentation as well as for semi-supervised domain adaptation. In particular, with only 1/30 of the Cityscapes labels, our method achieves 92% of the fully-supervised baseline performance and even 97% when exploiting additional data from GTA. The source code is available at https://github.com/lhoyer/improving_segmentation_with_selfsupervised_depth.
Learning to Relate Depth and Semantics for Unsupervised Domain Adaptation
May 17, 2021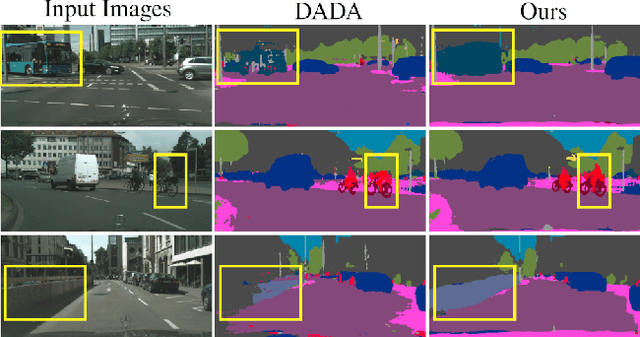
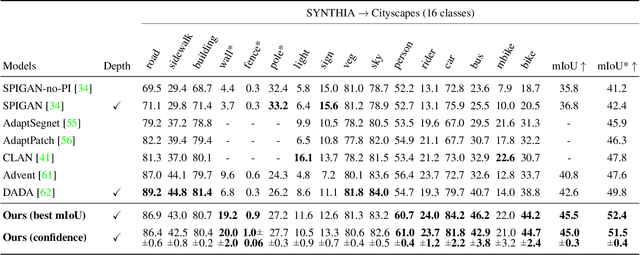

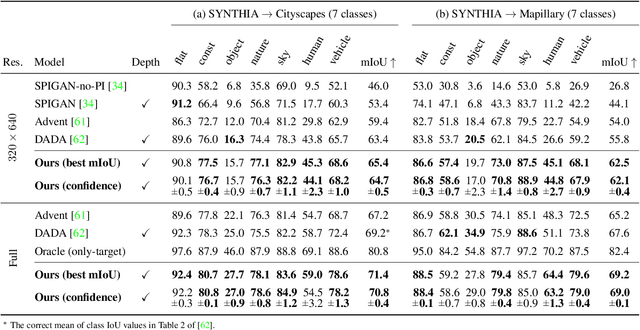
We present an approach for encoding visual task relationships to improve model performance in an Unsupervised Domain Adaptation (UDA) setting. Semantic segmentation and monocular depth estimation are shown to be complementary tasks; in a multi-task learning setting, a proper encoding of their relationships can further improve performance on both tasks. Motivated by this observation, we propose a novel Cross-Task Relation Layer (CTRL), which encodes task dependencies between the semantic and depth predictions. To capture the cross-task relationships, we propose a neural network architecture that contains task-specific and cross-task refinement heads. Furthermore, we propose an Iterative Self-Learning (ISL) training scheme, which exploits semantic pseudo-labels to provide extra supervision on the target domain. We experimentally observe improvements in both tasks' performance because the complementary information present in these tasks is better captured. Specifically, we show that: (1) our approach improves performance on all tasks when they are complementary and mutually dependent; (2) the CTRL helps to improve both semantic segmentation and depth estimation tasks performance in the challenging UDA setting; (3) the proposed ISL training scheme further improves the semantic segmentation performance. The implementation is available at https://github.com/susaha/ctrl-uda.
Three Ways to Improve Semantic Segmentation with Self-Supervised Depth Estimation
Dec 19, 2020

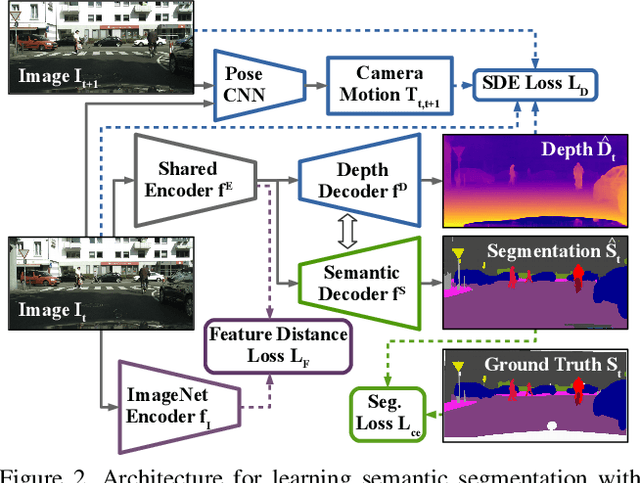
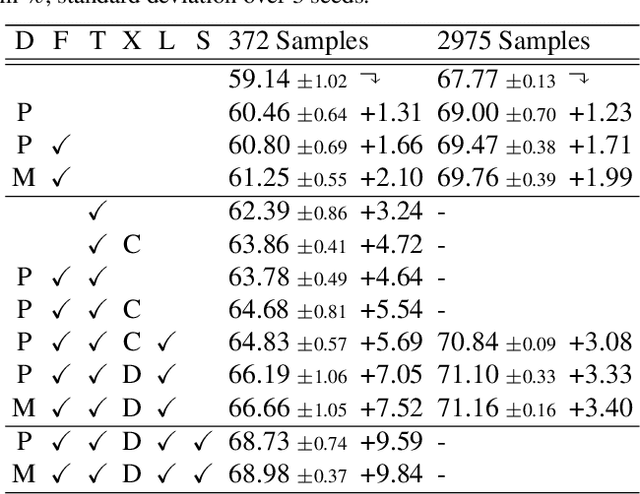
Training deep networks for semantic segmentation requires large amounts of labeled training data, which presents a major challenge in practice, as labeling segmentation masks is a highly labor-intensive process. To address this issue, we present a framework for semi-supervised semantic segmentation, which is enhanced by self-supervised monocular depth estimation from unlabeled images. In particular, we propose three key contributions: (1) We transfer knowledge from features learned during self-supervised depth estimation to semantic segmentation, (2) we implement a strong data augmentation by blending images and labels using the structure of the scene, and (3) we utilize the depth feature diversity as well as the level of difficulty of learning depth in a student-teacher framework to select the most useful samples to be annotated for semantic segmentation. We validate the proposed model on the Cityscapes dataset, where all three modules demonstrate significant performance gains, and we achieve state-of-the-art results for semi-supervised semantic segmentation. The implementation is available at https://github.com/lhoyer/improving_segmentation_with_selfsupervised_depth.
mDALU: Multi-Source Domain Adaptation and Label Unification with Partial Datasets
Dec 15, 2020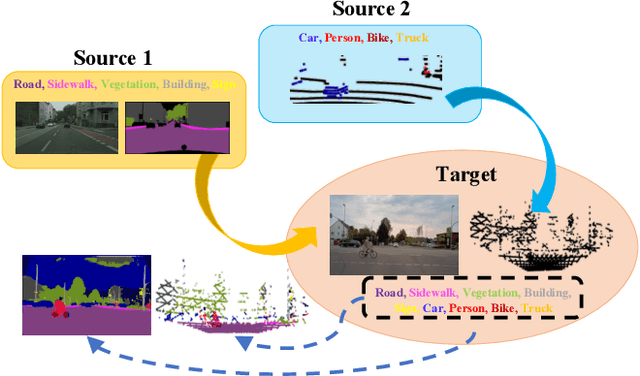


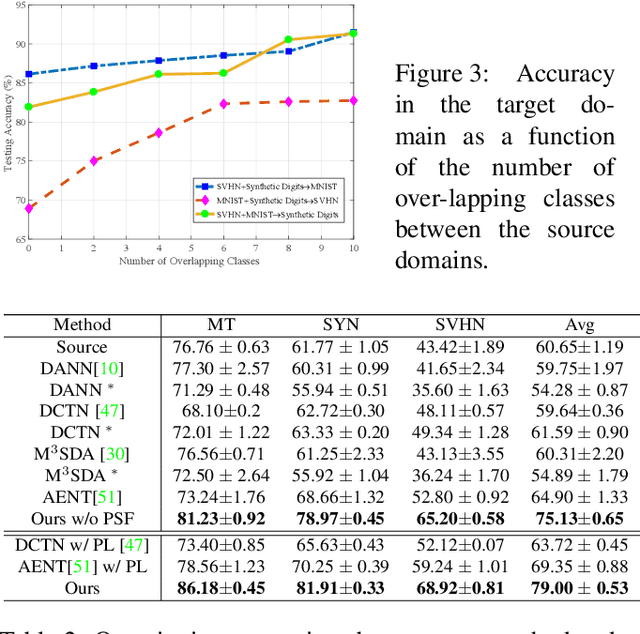
Object recognition advances very rapidly these days. One challenge is to generalize existing methods to new domains, to more classes and/or to new data modalities. In order to avoid annotating one dataset for each of these new cases, one needs to combine and reuse existing datasets that may belong to different domains, have partial annotations, and/or have different data modalities. This paper treats this task as a multi-source domain adaptation and label unification (mDALU) problem and proposes a novel method for it. Our method consists of a partially-supervised adaptation stage and a fully-supervised adaptation stage. In the former, partial knowledge is transferred from multiple source domains to the target domain and fused therein. Negative transfer between unmatched label space is mitigated via three new modules: domain attention, uncertainty maximization and attention-guided adversarial alignment. In the latter, knowledge is transferred in the unified label space after a label completion process with pseudo-labels. We verify the method on three different tasks, image classification, 2D semantic image segmentation, and joint 2D-3D semantic segmentation. Extensive experiments show that our method outperforms all competing methods significantly.