 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2D: Sparse-To-Dense Keymask Distillation for Unsupervised Video Instance Segmentation
Dec 16, 2025In recent years, the state-of-the-art in unsupervised video instance segmentation has heavily relied on synthetic video data, generated from object-centric image datasets such as ImageNet. However, video synthesis by artificially shifting and scaling image instance masks fails to accurately model realistic motion in videos, such as perspective changes, movement by parts of one or multiple instances, or camera motion. To tackle this issue, we propose an unsupervised video instance segmentation model trained exclusively on real video data. We start from unsupervised instance segmentation masks on individual video frames. However, these single-frame segmentations exhibit temporal noise and their quality varies through the video. Therefore, we establish temporal coherence by identifying high-quality keymasks in the video by leveraging deep motion priors. The sparse keymask pseudo-annotations are then used to train a segmentation model for implicit mask propagation, for which we propose a Sparse-To-Dense Distillation approach aided by a Temporal DropLoss. After training the final model on the resulting dense labelset, our approach outperforms the current state-of-the-art across various benchmarks.
From Open-Vocabulary to Vocabulary-Free Semantic Segmentation
Feb 17, 2025Open-vocabulary semantic segmentation enables models to identify novel object categories beyond their training data. While this flexibility represents a significant advancement, current approaches still rely on manually specified class names as input, creating an inherent bottleneck in real-world applications. This work proposes a Vocabulary-Free Semantic Segmentation pipeline, eliminating the need for predefined class vocabularies. Specifically, we address the chicken-and-egg problem where users need knowledge of all potential objects within a scene to identify them, yet the purpose of segmentation is often to discover these objects. The proposed approach leverages Vision-Language Models to automatically recognize objects and generate appropriate class names, aiming to solve the challenge of class specification and naming quality. Through extensive experiments on several public datasets, we highlight the crucial role of the text encoder in model performance, particularly when the image text classes are paired with generated descriptions. Despite the challenges introduced by the sensitivity of the segmentation text encoder to false negatives within the class tagging process, which adds complexity to the task, we demonstrate that our fully automated pipeline significantly enhances vocabulary-free segmentation accuracy across diverse real-world scenarios.
MICDrop: Masking Image and Depth Features via Complementary Dropout for Domain-Adaptive Semantic Segmentation
Aug 29, 2024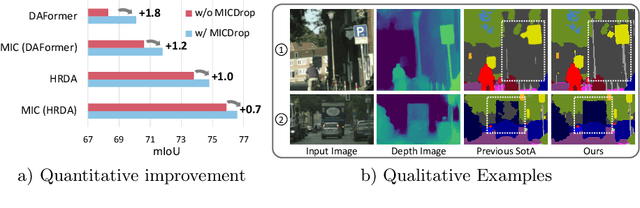
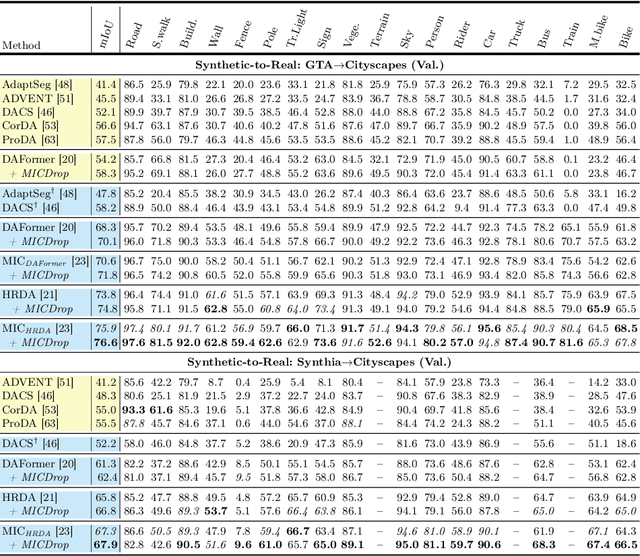
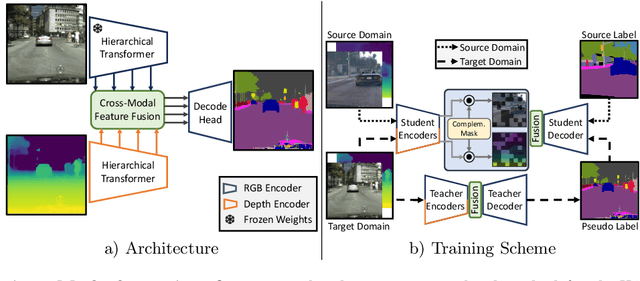

Unsupervised Domain Adaptation (UDA) is the task of bridging the domain gap between a labeled source domain, e.g., synthetic data, and an unlabeled target domain. We observe that current UDA methods show inferior results on fine structures and tend to oversegment objects with ambiguous appearance. To address these shortcomings, we propose to leverage geometric information, i.e., depth predictions, as depth discontinuities often coincide with segmentation boundaries. We show that naively incorporating depth into current UDA methods does not fully exploit the potential of this complementary information. To this end, we present MICDrop, which learns a joint feature representation by masking image encoder features while inversely masking depth encoder features. With this simple yet effective complementary masking strategy, we enforce the use of both modalities when learning the joint feature representation. To aid this process, we propose a feature fusion module to improve both global as well as local information sharing while being robust to errors in the depth predictions. We show that our method can be plugged into various recent UDA methods and consistently improve results across standard UDA benchmarks, obtaining new state-of-the-art performances.
Scribbles for All: Benchmarking Scribble Supervised Segmentation Across Datasets
Aug 22, 2024
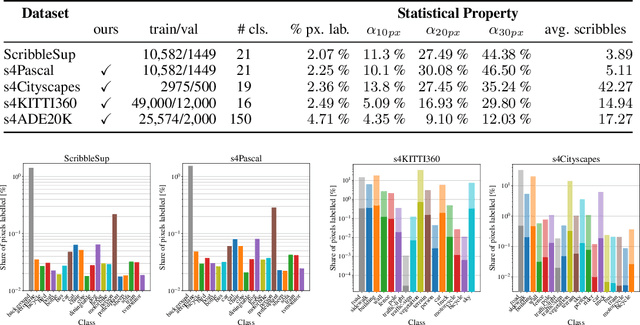
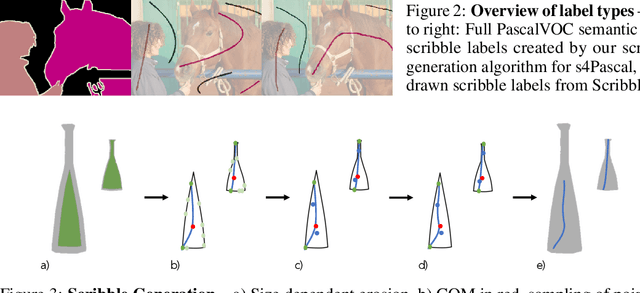

In this work, we introduce Scribbles for All, a label and training data generation algorithm for semantic segmentation trained on scribble labels. Training or fine-tuning semantic segmentation models with weak supervision has become an important topic recently and was subject to significant advances in model quality. In this setting, scribbles are a promising label type to achieve high quality segmentation results while requiring a much lower annotation effort than usual pixel-wise dense semantic segmentation annotations. The main limitation of scribbles as source for weak supervision is the lack of challenging datasets for scribble segmentation, which hinders the development of novel methods and conclusive evaluations. To overcome this limitation, Scribbles for All provides scribble labels for several popular segmentation datasets and provides an algorithm to automatically generate scribble labels for any dataset with dense annotations, paving the way for new insights and model advancements in the field of weakly supervised segmentation. In addition to providing datasets and algorithm, we evaluate state-of-the-art segmentation models on our datasets and show that models trained with our synthetic labels perform competitively with respect to models trained on manual labels. Thus, our datasets enable state-of-the-art research into methods for scribble-labeled semantic segmentation. The datasets, scribble generation algorithm, and baselines are publicly available at https://github.com/wbkit/Scribbles4All
DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
Dec 05, 2023
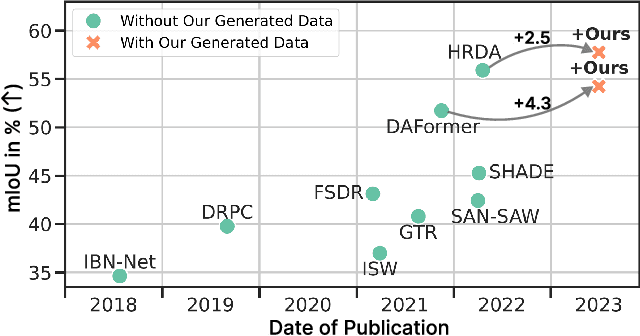
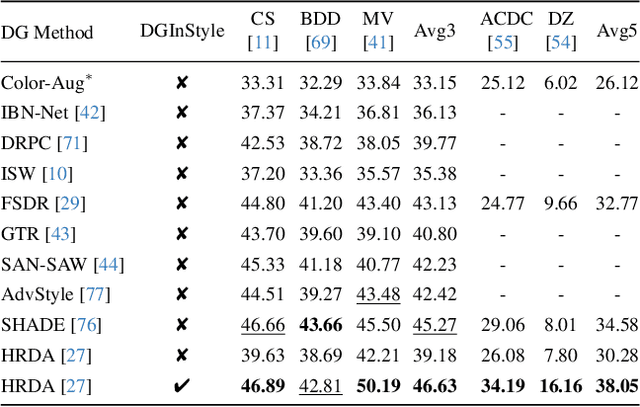
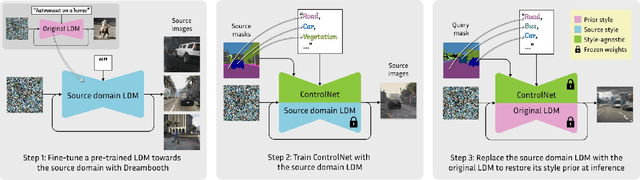
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding "yes". We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Third, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods, in some cases by +2.5 mIoU compared to the previous state-of-the-art method without our generative augmentation scheme. Source code and dataset are available at https://dginstyle.github.io .
SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance
Nov 27, 2023In semi-supervised semantic segmentation, a model is trained with a limited number of labeled images along with a large corpus of unlabeled images to reduce the high annotation effort. While previous methods are able to learn good segmentation boundaries, they are prone to confuse classes with similar visual appearance due to the limited supervision. On the other hand, vision-language models (VLMs) are able to learn diverse semantic knowledge from image-caption datasets but produce noisy segmentation due to the image-level training. In SemiVL, we propose to integrate rich priors from VLM pre-training into semi-supervised semantic segmentation to learn better semantic decision boundaries. To adapt the VLM from global to local reasoning, we introduce a spatial fine-tuning strategy for label-efficient learning. Further, we design a language-guided decoder to jointly reason over vision and language. Finally, we propose to handle inherent ambiguities in class labels by providing the model with language guidance in the form of class definitions. We evaluate SemiVL on 4 semantic segmentation datasets, where it significantly outperforms previous semi-supervised methods. For instance, SemiVL improves the state-of-the-art by +13.5 mIoU on COCO with 232 annotated images and by +6.1 mIoU on Pascal VOC with 92 labels. Project page: https://github.com/google-research/semivl
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
SILC: Improving Vision Language Pretraining with Self-Distillation
Oct 20, 2023



Image-Text pretraining on web-scale image caption dataset has become the default recipe for open vocabulary classification and retrieval models thanks to the success of CLIP and its variants. Several works have also used CLIP features for dense prediction tasks and have shown the emergence of open-set abilities. However, the contrastive objective only focuses on image-text alignment and does not incentivise image feature learning for dense prediction tasks. In this work, we propose the simple addition of local-to-global correspondence learning by self-distillation as an additional objective for contrastive pre-training to propose SILC. We show that distilling local image features from an exponential moving average (EMA) teacher model significantly improves model performance on several computer vision tasks including classification, retrieval, and especially segmentation. We further show that SILC scales better with the same training duration compared to the baselines. Our model SILC sets a new state of the art for zero-shot classification, few shot classification, image and text retrieval, zero-shot segmentation, and open vocabulary segmentation.
LiDAR Meta Depth Completion
Aug 16, 2023



Depth estimation is one of the essential tasks to be addressed when creating mobile autonomous systems. While monocular depth estimation methods have improved in recent times, depth completion provides more accurate and reliable depth maps by additionally using sparse depth information from other sensors such as LiDAR. However, current methods are specifically trained for a single LiDAR sensor. As the scanning pattern differs between sensors, every new sensor would require re-training a specialized depth completion model, which is computationally inefficient and not flexible. Therefore, we propose to dynamically adapt the depth completion model to the used sensor type enabling LiDAR adaptive depth completion. Specifically, we propose a meta depth completion network that uses data patterns derived from the data to learn a task network to alter weights of the main depth completion network to solve a given depth completion task effectively. The method demonstrates a strong capability to work on multiple LiDAR scanning patterns and can also generalize to scanning patterns that are unseen during training. While using a single model, our method yields significantly better results than a non-adaptive baseline trained on different LiDAR patterns. It outperforms LiDAR-specific expert models for very sparse cases. These advantages allow flexible deployment of a single depth completion model on different sensors, which could also prove valuable to process the input of nascent LiDAR technology with adaptive instead of fixed scanning patterns.
EDAPS: Enhanced Domain-Adaptive Panoptic Segmentation
Apr 27, 2023



With autonomous industries on the rise, domain adaptation of the visual perception stack is an important research direction due to the cost savings promise. Much prior art was dedicated to domain-adaptive semantic segmentation in the synthetic-to-real context. Despite being a crucial output of the perception stack, panoptic segmentation has been largely overlooked by the domain adaptation community. Therefore, we revisit well-performing domain adaptation strategies from other fields, adapt them to panoptic segmentation, and show that they can effectively enhance panoptic domain adaptation. Further, we study the panoptic network design and propose a novel architecture (EDAPS) designed explicitly for domain-adaptive panoptic segmentation. It uses a shared, domain-robust transformer encoder to facilitate the joint adaptation of semantic and instance features, but task-specific decoders tailored for the specific requirements of both domain-adaptive semantic and instance segmentation. As a result, the performance gap seen in challenging panoptic benchmarks is substantially narrowed. EDAPS significantly improves the state-of-the-art performance for panoptic segmentation UDA by a large margin of 25% on SYNTHIA-to-Cityscapes and even 72% on the more challenging SYNTHIA-to-Mapillary Vistas. The implementation is available at https://github.com/susaha/edaps.