 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonSeg3R: Monocular Online Zero-Shot Segment Anything in 3D with Reconstructive Foundation Priors
Dec 17, 2025In this paper, we focus on online zero-shot monocular 3D instance segmentation, a novel practical setting where existing approaches fail to perform because they rely on posed RGB-D sequences. To overcome this limitation, we leverage CUT3R, a recent Reconstructive Foundation Model (RFM), to provide reliable geometric priors from a single RGB stream. We propose MoonSeg3R, which introduces three key components: (1) a self-supervised query refinement module with spatial-semantic distillation that transforms segmentation masks from 2D visual foundation models (VFMs) into discriminative 3D queries; (2) a 3D query index memory that provides temporal consistency by retrieving contextual queries; and (3) a state-distribution token from CUT3R that acts as a mask identity descriptor to strengthen cross-frame fusion. Experiments on ScanNet200 and SceneNN show that MoonSeg3R is the first method to enable online monocular 3D segmentation and achieves performance competitive with state-of-the-art RGB-D-based systems. Code and models will be released.
MoLingo: Motion-Language Alignment for Text-to-Motion Generation
Dec 15, 2025We introduce MoLingo, a text-to-motion (T2M) model that generates realistic, lifelike human motion by denoising in a continuous latent space. Recent works perform latent space diffusion, either on the whole latent at once or auto-regressively over multiple latents. In this paper, we study how to make diffusion on continuous motion latents work best. We focus on two questions: (1) how to build a semantically aligned latent space so diffusion becomes more effective, and (2) how to best inject text conditioning so the motion follows the description closely. We propose a semantic-aligned motion encoder trained with frame-level text labels so that latents with similar text meaning stay close, which makes the latent space more diffusion-friendly. We also compare single-token conditioning with a multi-token cross-attention scheme and find that cross-attention gives better motion realism and text-motion alignment. With semantically aligned latents, auto-regressive generation, and cross-attention text conditioning, our model sets a new state of the art in human motion generation on standard metrics and in a user study. We will release our code and models for further research and downstream usage.
AnyUp: Universal Feature Upsampling
Oct 14, 2025
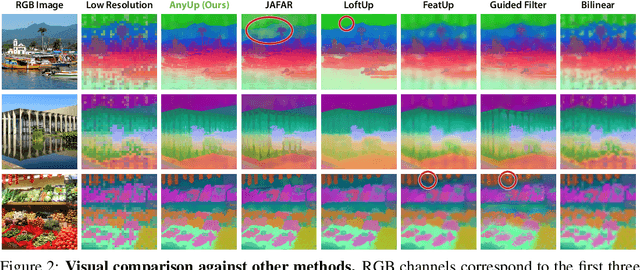

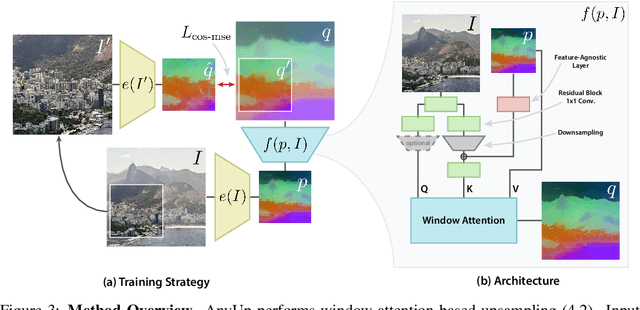
We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for every feature extractor and thus do not generalize to different feature types at inference time. In this work, we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.
RefAM: Attention Magnets for Zero-Shot Referral Segmentation
Sep 26, 2025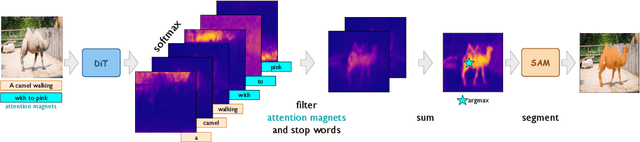
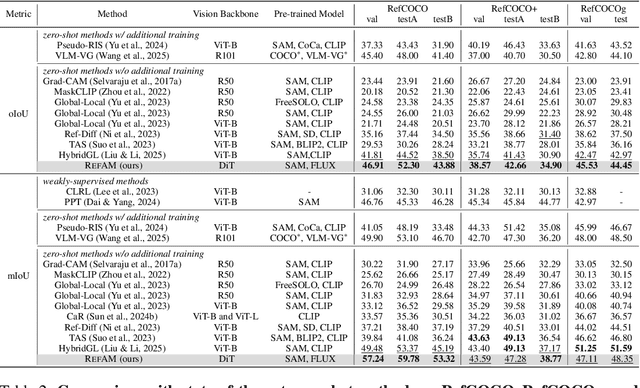

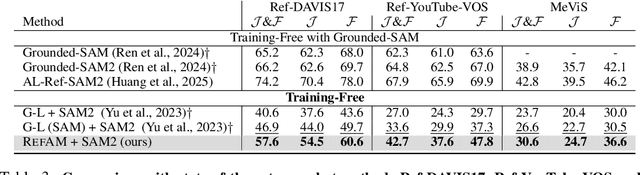
Most existing approaches to referring segmentation achieve strong performance only through fine-tuning or by composing multiple pre-trained models, often at the cost of additional training and architectural modifications. Meanwhile, large-scale generative diffusion models encode rich semantic information, making them attractive as general-purpose feature extractors. In this work, we introduce a new method that directly exploits features, attention scores, from diffusion transformers for downstream tasks, requiring neither architectural modifications nor additional training. To systematically evaluate these features, we extend benchmarks with vision-language grounding tasks spanning both images and videos. Our key insight is that stop words act as attention magnets: they accumulate surplus attention and can be filtered to reduce noise. Moreover, we identify global attention sinks (GAS) emerging in deeper layers and show that they can be safely suppressed or redirected onto auxiliary tokens, leading to sharper and more accurate grounding maps. We further propose an attention redistribution strategy, where appended stop words partition background activations into smaller clusters, yielding sharper and more localized heatmaps. Building on these findings, we develop RefAM, a simple training-free grounding framework that combines cross-attention maps, GAS handling, and redistribution. Across zero-shot referring image and video segmentation benchmarks, our approach consistently outperforms prior methods, establishing a new state of the art without fine-tuning or additional components.
PyG 2.0: Scalable Learning on Real World Graphs
Jul 22, 2025PyG (PyTorch Geometric) has evolved significantly since its initial release, establishing itself as a leading framework for Graph Neural Networks. In this paper, we present Pyg 2.0 (and its subsequent minor versions), a comprehensive update that introduces substantial improvements in scalability and real-world application capabilities. We detail the framework's enhanced architecture, including support for heterogeneous and temporal graphs, scalable feature/graph stores, and various optimizations, enabling researchers and practitioners to tackle large-scale graph learning problems efficiently. Over the recent years, PyG has been supporting graph learning in a large variety of application areas, which we will summarize, while providing a deep dive into the important areas of relational deep learning and large language modeling.
Spatial Reasoning with Denoising Models
Feb 28, 2025We introduce Spatial Reasoning Models (SRMs), a framework to perform reasoning over sets of continuous variables via denoising generative models. SRMs infer continuous representations on a set of unobserved variables, given observations on observed variables. Current generative models on spatial domains, such as diffusion and flow matching models, often collapse to hallucination in case of complex distributions. To measure this, we introduce a set of benchmark tasks that test the quality of complex reasoning in generative models and can quantify hallucination. The SRM framework allows to report key findings about importance of sequentialization in generation, the associated order, as well as the sampling strategies during training. It demonstrates, for the first time, that order of generation can successfully be predicted by the denoising network itself. Using these findings, we can increase the accuracy of specific reasoning tasks from <1% to >50%.
MEt3R: Measuring Multi-View Consistency in Generated Images
Jan 10, 2025We introduce MEt3R, a metric for multi-view consistency in generated images. Large-scale generative models for multi-view image generation are rapidly advancing the field of 3D inference from sparse observations. However, due to the nature of generative modeling, traditional reconstruction metrics are not suitable to measure the quality of generated outputs and metrics that are independent of the sampling procedure are desperately needed. In this work, we specifically address the aspect of consistency between generated multi-view images, which can be evaluated independently of the specific scene. Our approach uses DUSt3R to obtain dense 3D reconstructions from image pairs in a feed-forward manner, which are used to warp image contents from one view into the other. Then, feature maps of these images are compared to obtain a similarity score that is invariant to view-dependent effects. Using MEt3R, we evaluate the consistency of a large set of previous methods for novel view and video generation, including our open, multi-view latent diffusion model.
PersonaHOI: Effortlessly Improving Personalized Face with Human-Object Interaction Generation
Jan 10, 2025We introduce PersonaHOI, a training- and tuning-free framework that fuses a general StableDiffusion model with a personalized face diffusion (PFD) model to generate identity-consistent human-object interaction (HOI) images. While existing PFD models have advanced significantly, they often overemphasize facial features at the expense of full-body coherence, PersonaHOI introduces an additional StableDiffusion (SD) branch guided by HOI-oriented text inputs. By incorporating cross-attention constraints in the PFD branch and spatial merging at both latent and residual levels, PersonaHOI preserves personalized facial details while ensuring interactive non-facial regions. Experiments, validated by a novel interaction alignment metric, demonstrate the superior realism and scalability of PersonaHOI, establishing a new standard for practical personalized face with HOI generation. Our code will be available at https://github.com/JoyHuYY1412/PersonaHOI
SLayR: Scene Layout Generation with Rectified Flow
Dec 06, 2024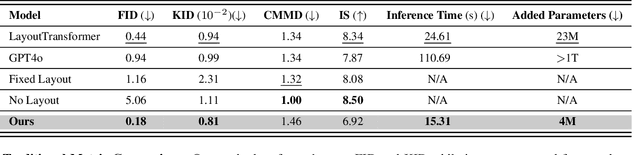
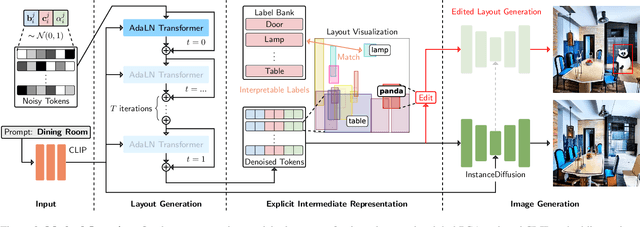
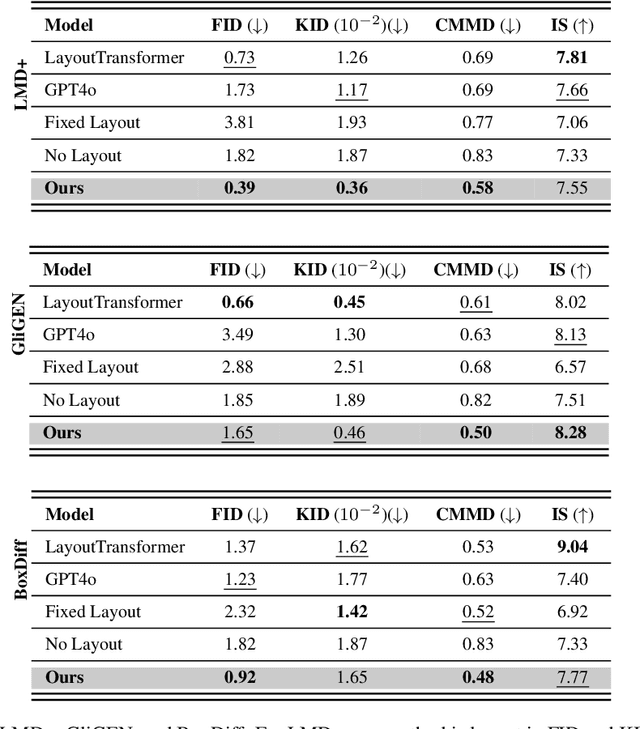
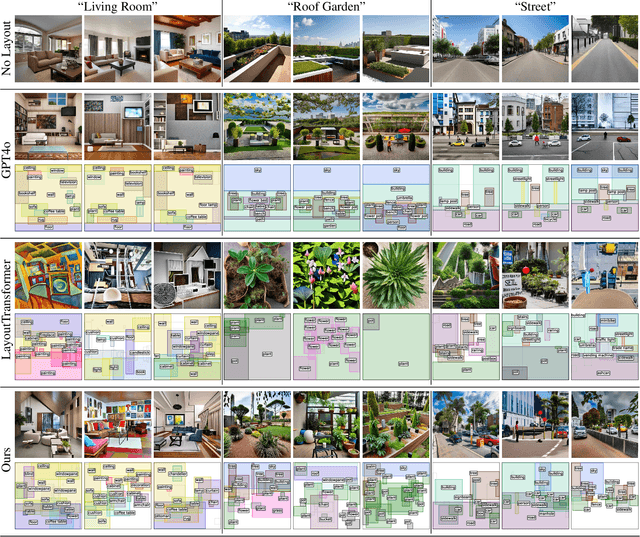
We introduce SLayR, Scene Layout Generation with Rectified flow. State-of-the-art text-to-image models achieve impressive results. However, they generate images end-to-end, exposing no fine-grained control over the process. SLayR presents a novel transformer-based rectified flow model for layout generation over a token space that can be decoded into bounding boxes and corresponding labels, which can then be transformed into images using existing models. We show that established metrics for generated images are inconclusive for evaluating their underlying scene layout, and introduce a new benchmark suite, including a carefully designed repeatable human-evaluation procedure that assesses the plausibility and variety of generated layouts. In contrast to previous works, which perform well in either high variety or plausibility, we show that our approach performs well on both of these axes at the same time. It is also at least 5x times smaller in the number of parameters and 37% faster than the baselines. Our complete text-to-image pipeline demonstrates the added benefits of an interpretable and editable intermediate representation.
ContextGNN: Beyond Two-Tower Recommendation Systems
Nov 29, 2024



Recommendation systems predominantly utilize two-tower architectures, which evaluate user-item rankings through the inner product of their respective embeddings. However, one key limitation of two-tower models is that they learn a pair-agnostic representation of users and items. In contrast, pair-wise representations either scale poorly due to their quadratic complexity or are too restrictive on the candidate pairs to rank. To address these issues, we introduce Context-based Graph Neural Networks (ContextGNNs), a novel deep learning architecture for link prediction in recommendation systems. The method employs a pair-wise representation technique for familiar items situated within a user's local subgraph, while leveraging two-tower representations to facilitate the recommendation of exploratory items. A final network then predicts how to fuse both pair-wise and two-tower recommendations into a single ranking of items. We demonstrate that ContextGNN is able to adapt to different data characteristics and outperforms existing methods, both traditional and GNN-based, on a diverse set of practical recommendation tasks, improving performance by 20% on average.