 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionPlan: Future-Aware Streaming Motion Synthesis via Frame-Level Action Planning
Mar 13, 2026We present ActionPlan, a unified motion diffusion framework that bridges real-time streaming with high-quality offline generation within a single model. The core idea is to introduce a per-frame action plan: the model predicts frame-level text latents that act as dense semantic anchors throughout denoising, and uses them to denoise the full motion sequence with combined semantic and motion cues. To support this structured workflow, we design latent-specific diffusion steps, allowing each motion latent to be denoised independently and sampled in flexible orders at inference. As a result, ActionPlan can run in a history-conditioned, future-aware mode for real-time streaming, while also supporting high-quality offline generation. The same mechanism further enables zero-shot motion editing and in-betweening without additional models. Experiments demonstrate that our real-time streaming is 5.25x faster while also achieving 18% motion quality improvement over the best previous method in terms of FID.
Hoi3DGen: Generating High-Quality Human-Object-Interactions in 3D
Mar 12, 2026Modeling and generating 3D human-object interactions from text is crucial for applications in AR, XR, and gaming. Existing approaches often rely on score distillation from text-to-image models, but their results suffer from the Janus problem and do not follow text prompts faithfully due to the scarcity of high-quality interaction data. We introduce Hoi3DGen, a framework that generates high-quality textured meshes of human-object interaction that follow the input interaction descriptions precisely. We first curate realistic and high-quality interaction data leveraging multimodal large language models, and then create a full text-to-3D pipeline, which achieves orders-of-magnitude improvements in interaction fidelity. Our method surpasses baselines by 4-15x in text consistency and 3-7x in 3D model quality, exhibiting strong generalization to diverse categories and interaction types, while maintaining high-quality 3D generation.
FrankenMotion: Part-level Human Motion Generation and Composition
Jan 15, 2026Human motion generation from text prompts has made remarkable progress in recent years. However, existing methods primarily rely on either sequence-level or action-level descriptions due to the absence of fine-grained, part-level motion annotations. This limits their controllability over individual body parts. In this work, we construct a high-quality motion dataset with atomic, temporally-aware part-level text annotations, leveraging the reasoning capabilities of large language models (LLMs). Unlike prior datasets that either provide synchronized part captions with fixed time segments or rely solely on global sequence labels, our dataset captures asynchronous and semantically distinct part movements at fine temporal resolution. Based on this dataset, we introduce a diffusion-based part-aware motion generation framework, namely FrankenMotion, where each body part is guided by its own temporally-structured textual prompt. This is, to our knowledge, the first work to provide atomic, temporally-aware part-level motion annotations and have a model that allows motion generation with both spatial (body part) and temporal (atomic action) control. Experiments demonstrate that FrankenMotion outperforms all previous baseline models adapted and retrained for our setting, and our model can compose motions unseen during training. Our code and dataset will be publicly available upon publication.
CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
Dec 12, 2025Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.
Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy
Dec 09, 2024Creating realistic 3D objects and clothed avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot guarantee the generated multi-view images are 3D consistent. In this paper, we propose Gen-3Diffusion: Realistic Image-to-3D Generation via 2D & 3D Diffusion Synergy. We leverage a pre-trained 2D diffusion model and a 3D diffusion model via our elegantly designed process that synchronizes two diffusion models at both training and sampling time. The synergy between the 2D and 3D diffusion models brings two major advantages: 1) 2D helps 3D in generalization: the pretrained 2D model has strong generalization ability to unseen images, providing strong shape priors for the 3D diffusion model; 2) 3D helps 2D in multi-view consistency: the 3D diffusion model enhances the 3D consistency of 2D multi-view sampling process, resulting in more accurate multi-view generation. We validate our idea through extensive experiments in image-based objects and clothed avatar generation tasks. Results show that our method generates realistic 3D objects and avatars with high-fidelity geometry and texture. Extensive ablations also validate our design choices and demonstrate the strong generalization ability to diverse clothing and compositional shapes. Our code and pretrained models will be publicly released on https://yuxuan-xue.com/gen-3diffusion.
InterTrack: Tracking Human Object Interaction without Object Templates
Aug 25, 2024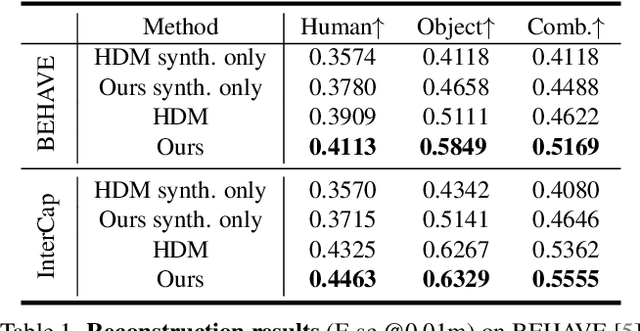
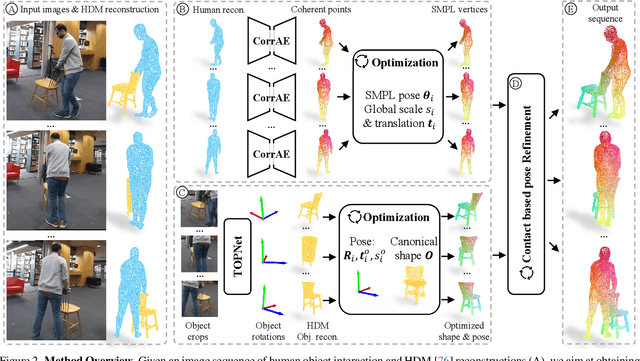
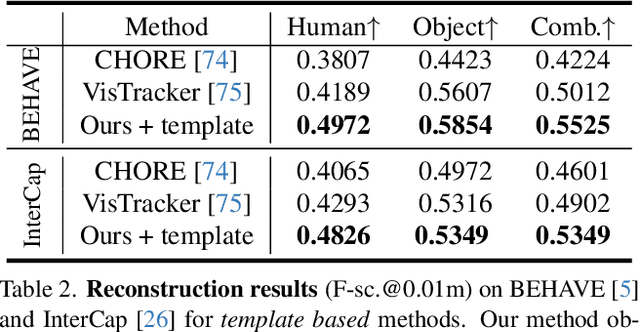
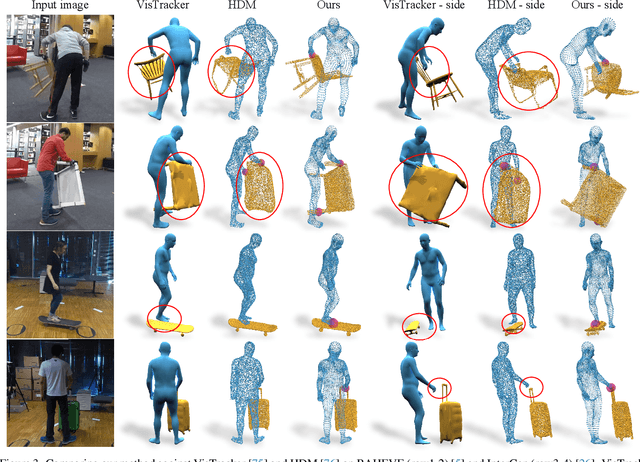
Tracking human object interaction from videos is important to understand human behavior from the rapidly growing stream of video data. Previous video-based methods require predefined object templates while single-image-based methods are template-free but lack temporal consistency. In this paper, we present a method to track human object interaction without any object shape templates. We decompose the 4D tracking problem into per-frame pose tracking and canonical shape optimization. We first apply a single-view reconstruction method to obtain temporally-inconsistent per-frame interaction reconstructions. Then, for the human, we propose an efficient autoencoder to predict SMPL vertices directly from the per-frame reconstructions, introducing temporally consistent correspondence. For the object, we introduce a pose estimator that leverages temporal information to predict smooth object rotations under occlusions. To train our model, we propose a method to generate synthetic interaction videos and synthesize in total 10 hour videos of 8.5k sequences with full 3D ground truth. Experiments on BEHAVE and InterCap show that our method significantly outperforms previous template-based video tracking and single-frame reconstruction methods. Our proposed synthetic video dataset also allows training video-based methods that generalize to real-world videos. Our code and dataset will be publicly released.
Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Jun 12, 2024Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
RHOBIN Challenge: Reconstruction of Human Object Interaction
Jan 07, 2024Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.
Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation
Dec 12, 2023



Reconstructing human-object interaction in 3D from a single RGB image is a challenging task and existing data driven methods do not generalize beyond the objects present in the carefully curated 3D interaction datasets. Capturing large-scale real data to learn strong interaction and 3D shape priors is very expensive due to the combinatorial nature of human-object interactions. In this paper, we propose ProciGen (Procedural interaction Generation), a method to procedurally generate datasets with both, plausible interaction and diverse object variation. We generate 1M+ human-object interaction pairs in 3D and leverage this large-scale data to train our HDM (Hierarchical Diffusion Model), a novel method to reconstruct interacting human and unseen objects, without any templates. Our HDM is an image-conditioned diffusion model that learns both realistic interaction and highly accurate human and object shapes. Experiments show that our HDM trained with ProciGen significantly outperforms prior methods that requires template meshes and that our dataset allows training methods with strong generalization ability to unseen object instances. Our code and data will be publicly released at: https://virtualhumans.mpi-inf.mpg.de/procigen-hdm.
Visibility Aware Human-Object Interaction Tracking from Single RGB Camera
Mar 29, 2023



Capturing the interactions between humans and their environment in 3D is important for many applications in robotics, graphics, and vision. Recent works to reconstruct the 3D human and object from a single RGB image do not have consistent relative translation across frames because they assume a fixed depth. Moreover, their performance drops significantly when the object is occluded. In this work, we propose a novel method to track the 3D human, object, contacts between them, and their relative translation across frames from a single RGB camera, while being robust to heavy occlusions. Our method is built on two key insights. First, we condition our neural field reconstructions for human and object on per-frame SMPL model estimates obtained by pre-fitting SMPL to a video sequence. This improves neural reconstruction accuracy and produces coherent relative translation across frames. Second, human and object motion from visible frames provides valuable information to infer the occluded object. We propose a novel transformer-based neural network that explicitly uses object visibility and human motion to leverage neighbouring frames to make predictions for the occluded frames. Building on these insights, our method is able to track both human and object robustly even under occlusions. Experiments on two datasets show that our method significantly improves over the state-of-the-art methods. Our code and pretrained models are available at: https://virtualhumans.mpi-inf.mpg.de/VisTracker