 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCon3R: Contact-aware 3D Human-Scene Reconstruction from Monocular Video
Apr 21, 2026We introduce UniCon3R (Unified Contact-aware 3D Reconstruction), a unified feed-forward framework for online human-scene 4D reconstruction from monocular videos. Recent feed-forward methods enable real-time world-coordinate human motion and scene reconstruction, but they often produce physically implausible artifacts such as bodies floating above the ground or penetrating parts of the scene. The key reason is that existing approaches fail to model physical interactions between the human and the environment. A natural next step is to predict human-scene contact as an auxiliary output -- yet we find this alone is not sufficient: contact must actively correct the reconstruction. To address this, we explicitly model interaction by inferring 3D contact from the human pose and scene geometry and use the contact as a corrective cue for generating the final pose. This enables UniCon3R to jointly recover high-fidelity scene geometry and spatially aligned 3D humans within the scene. Experiments on standard human-centric video benchmarks such as RICH, EMDB, 3DPW and SLOPER4D show that UniCon3R outperforms state-of-the-art baselines on physical plausibility and global human motion estimation while achieving real-time online inference. We experimentally demonstrate that contact serves as a powerful internal prior rather than just an external metric, thus establishing a new paradigm for physically grounded joint human-scene reconstruction. Project page is available at https://surtantheta.github.io/UniCon3R .
FUSION: Full-Body Unified Motion Prior for Body and Hands via Diffusion
Jan 07, 2026Hands are central to interacting with our surroundings and conveying gestures, making their inclusion essential for full-body motion synthesis. Despite this, existing human motion synthesis methods fall short: some ignore hand motions entirely, while others generate full-body motions only for narrowly scoped tasks under highly constrained settings. A key obstacle is the lack of large-scale datasets that jointly capture diverse full-body motion with detailed hand articulation. While some datasets capture both, they are limited in scale and diversity. Conversely, large-scale datasets typically focus either on body motion without hands or on hand motions without the body. To overcome this, we curate and unify existing hand motion datasets with large-scale body motion data to generate full-body sequences that capture both hand and body. We then propose the first diffusion-based unconditional full-body motion prior, FUSION, which jointly models body and hand motion. Despite using a pose-based motion representation, FUSION surpasses state-of-the-art skeletal control models on the Keypoint Tracking task in the HumanML3D dataset and achieves superior motion naturalness. Beyond standard benchmarks, we demonstrate that FUSION can go beyond typical uses of motion priors through two applications: (1) generating detailed full-body motion including fingers during interaction given the motion of an object, and (2) generating Self-Interaction motions using an LLM to transform natural language cues into actionable motion constraints. For these applications, we develop an optimization pipeline that refines the latent space of our diffusion model to generate task-specific motions. Experiments on these tasks highlight precise control over hand motion while maintaining plausible full-body coordination. The code will be public.
FormCoach: Lift Smarter, Not Harder
Aug 10, 2025Good form is the difference between strength and strain, yet for the fast-growing community of at-home fitness enthusiasts, expert feedback is often out of reach. FormCoach transforms a simple camera into an always-on, interactive AI training partner, capable of spotting subtle form errors and delivering tailored corrections in real time, leveraging vision-language models (VLMs). We showcase this capability through a web interface and benchmark state-of-the-art VLMs on a dataset of 1,700 expert-annotated user-reference video pairs spanning 22 strength and mobility exercises. To accelerate research in AI-driven coaching, we release both the dataset and an automated, rubric-based evaluation pipeline, enabling standardized comparison across models. Our benchmarks reveal substantial gaps compared to human-level coaching, underscoring both the challenges and opportunities in integrating nuanced, context-aware movement analysis into interactive AI systems. By framing form correction as a collaborative and creative process between humans and machines, FormCoach opens a new frontier in embodied AI.
MotionFix: Text-Driven 3D Human Motion Editing
Aug 01, 2024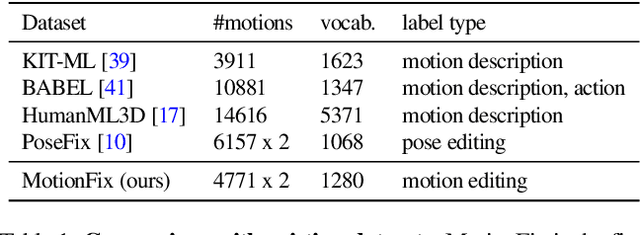

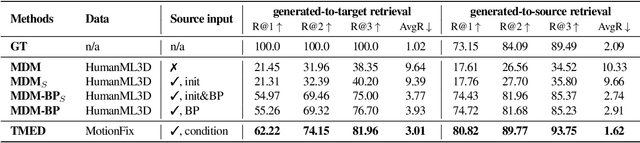
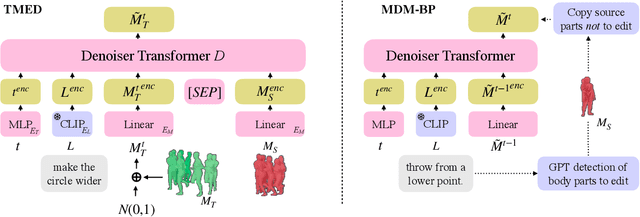
The focus of this paper is 3D motion editing. Given a 3D human motion and a textual description of the desired modification, our goal is to generate an edited motion as described by the text. The challenges include the lack of training data and the design of a model that faithfully edits the source motion. In this paper, we address both these challenges. We build a methodology to semi-automatically collect a dataset of triplets in the form of (i) a source motion, (ii) a target motion, and (iii) an edit text, and create the new MotionFix dataset. Having access to such data allows us to train a conditional diffusion model, TMED, that takes both the source motion and the edit text as input. We further build various baselines trained only on text-motion pairs datasets, and show superior performance of our model trained on triplets. We introduce new retrieval-based metrics for motion editing and establish a new benchmark on the evaluation set of MotionFix. Our results are encouraging, paving the way for further research on finegrained motion generation. Code and models will be made publicly available.
WANDR: Intention-guided Human Motion Generation
Apr 23, 2024Synthesizing natural human motions that enable a 3D human avatar to walk and reach for arbitrary goals in 3D space remains an unsolved problem with many applications. Existing methods (data-driven or using reinforcement learning) are limited in terms of generalization and motion naturalness. A primary obstacle is the scarcity of training data that combines locomotion with goal reaching. To address this, we introduce WANDR, a data-driven model that takes an avatar's initial pose and a goal's 3D position and generates natural human motions that place the end effector (wrist) on the goal location. To solve this, we introduce novel intention features that drive rich goal-oriented movement. Intention guides the agent to the goal, and interactively adapts the generation to novel situations without needing to define sub-goals or the entire motion path. Crucially, intention allows training on datasets that have goal-oriented motions as well as those that do not. WANDR is a conditional Variational Auto-Encoder (c-VAE), which we train using the AMASS and CIRCLE datasets. We evaluate our method extensively and demonstrate its ability to generate natural and long-term motions that reach 3D goals and generalize to unseen goal locations. Our models and code are available for research purposes at wandr.is.tue.mpg.de.
RHOBIN Challenge: Reconstruction of Human Object Interaction
Jan 07, 2024Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.
Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Dec 07, 2023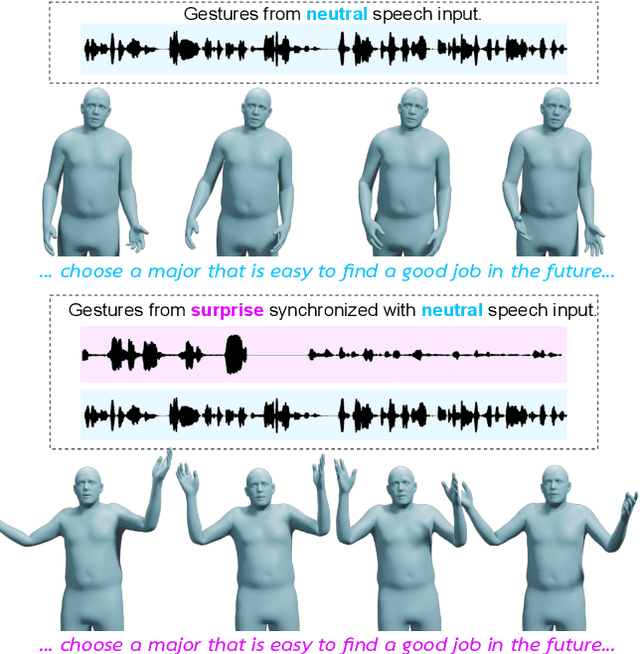



Existing methods for synthesizing 3D human gestures from speech have shown promising results, but they do not explicitly model the impact of emotions on the generated gestures. Instead, these methods directly output animations from speech without control over the expressed emotion. To address this limitation, we present AMUSE, an emotional speech-driven body animation model based on latent diffusion. Our observation is that content (i.e., gestures related to speech rhythm and word utterances), emotion, and personal style are separable. To account for this, AMUSE maps the driving audio to three disentangled latent vectors: one for content, one for emotion, and one for personal style. A latent diffusion model, trained to generate gesture motion sequences, is then conditioned on these latent vectors. Once trained, AMUSE synthesizes 3D human gestures directly from speech with control over the expressed emotions and style by combining the content from the driving speech with the emotion and style of another speech sequence. Randomly sampling the noise of the diffusion model further generates variations of the gesture with the same emotional expressivity. Qualitative, quantitative, and perceptual evaluations demonstrate that AMUSE outputs realistic gesture sequences. Compared to the state of the art, the generated gestures are better synchronized with the speech content and better represent the emotion expressed by the input speech. Our project website is amuse.is.tue.mpg.de.
SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation
Apr 20, 2023



Our goal is to synthesize 3D human motions given textual inputs describing simultaneous actions, for example 'waving hand' while 'walking' at the same time. We refer to generating such simultaneous movements as performing 'spatial compositions'. In contrast to temporal compositions that seek to transition from one action to another, spatial compositing requires understanding which body parts are involved in which action, to be able to move them simultaneously. Motivated by the observation that the correspondence between actions and body parts is encoded in powerful language models, we extract this knowledge by prompting GPT-3 with text such as "what are the body parts involved in the action <action name>?", while also providing the parts list and few-shot examples. Given this action-part mapping, we combine body parts from two motions together and establish the first automated method to spatially compose two actions. However, training data with compositional actions is always limited by the combinatorics. Hence, we further create synthetic data with this approach, and use it to train a new state-of-the-art text-to-motion generation model, called SINC ("SImultaneous actioN Compositions for 3D human motions"). In our experiments, we find training on additional synthetic GPT-guided compositional motions improves text-to-motion generation.
TEACH: Temporal Action Composition for 3D Humans
Sep 12, 2022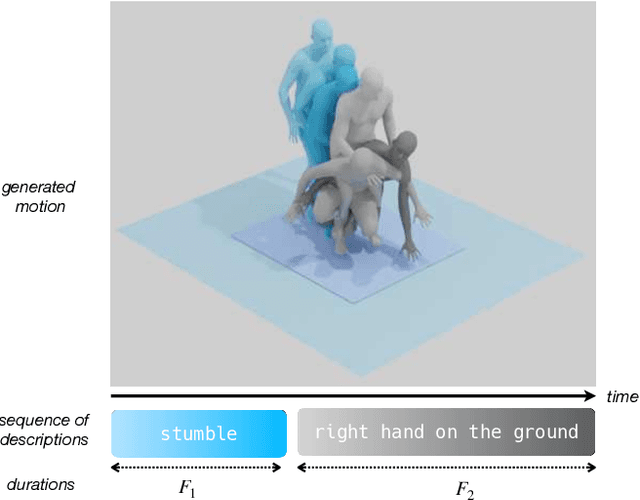

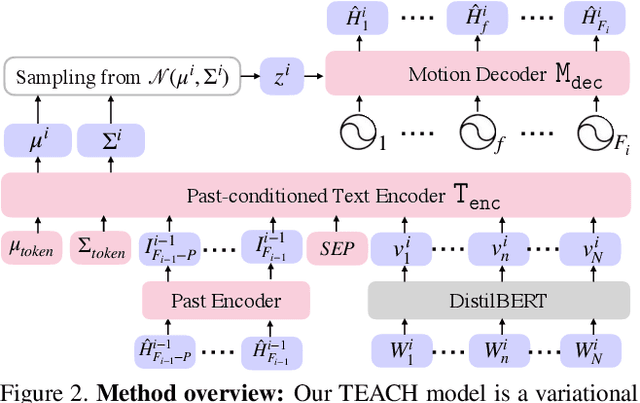

Given a series of natural language descriptions, our task is to generate 3D human motions that correspond semantically to the text, and follow the temporal order of the instructions. In particular, our goal is to enable the synthesis of a series of actions, which we refer to as temporal action composition. The current state of the art in text-conditioned motion synthesis only takes a single action or a single sentence as input. This is partially due to lack of suitable training data containing action sequences, but also due to the computational complexity of their non-autoregressive model formulation, which does not scale well to long sequences. In this work, we address both issues. First, we exploit the recent BABEL motion-text collection, which has a wide range of labeled actions, many of which occur in a sequence with transitions between them. Next, we design a Transformer-based approach that operates non-autoregressively within an action, but autoregressively within the sequence of actions. This hierarchical formulation proves effective in our experiments when compared with multiple baselines. Our approach, called TEACH for "TEmporal Action Compositions for Human motions", produces realistic human motions for a wide variety of actions and temporal compositions from language descriptions. To encourage work on this new task, we make our code available for research purposes at our $\href{teach.is.tue.mpg.de}{\text{website}}$.
Learning to Regress Bodies from Images using Differentiable Semantic Rendering
Oct 07, 2021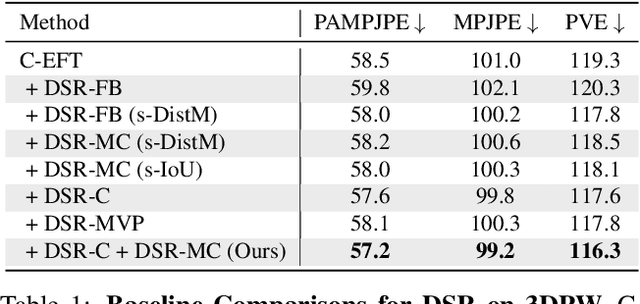
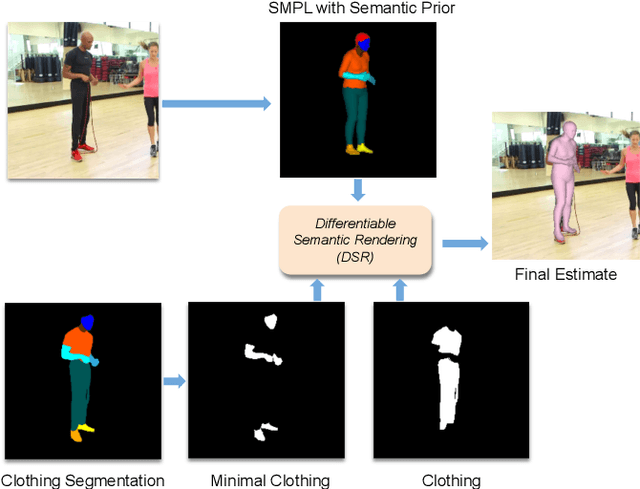

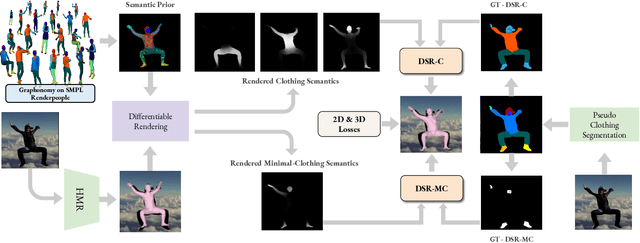
Learning to regress 3D human body shape and pose (e.g.~SMPL parameters) from monocular images typically exploits losses on 2D keypoints, silhouettes, and/or part-segmentation when 3D training data is not available. Such losses, however, are limited because 2D keypoints do not supervise body shape and segmentations of people in clothing do not match projected minimally-clothed SMPL shapes. To exploit richer image information about clothed people, we introduce higher-level semantic information about clothing to penalize clothed and non-clothed regions of the image differently. To do so, we train a body regressor using a novel Differentiable Semantic Rendering - DSR loss. For Minimally-Clothed regions, we define the DSR-MC loss, which encourages a tight match between a rendered SMPL body and the minimally-clothed regions of the image. For clothed regions, we define the DSR-C loss to encourage the rendered SMPL body to be inside the clothing mask. To ensure end-to-end differentiable training, we learn a semantic clothing prior for SMPL vertices from thousands of clothed human scans. We perform extensive qualitative and quantitative experiments to evaluate the role of clothing semantics on the accuracy of 3D human pose and shape estimation. We outperform all previous state-of-the-art methods on 3DPW and Human3.6M and obtain on par results on MPI-INF-3DHP. Code and trained models are available for research at https://dsr.is.tue.mpg.de/.