 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiShape: 3D Shape Modelling of Mitochondria in Microscopy
Mar 02, 2023



Fluorescence microscopy is a quintessential tool for observing cells and understanding the underlying mechanisms of life-sustaining processes of all living organisms. The problem of extracting 3D shape of mitochondria from fluorescence microscopy images remains unsolved due to the complex and varied shapes expressed by mitochondria and the poor resolving capacity of these microscopes. We propose an approach to bridge this gap by learning a shape prior for mitochondria termed as MiShape, by leveraging high-resolution electron microscopy data. MiShape is a generative model learned using implicit representations of mitochondrial shapes. It provides a shape distribution that can be used to generate infinite realistic mitochondrial shapes. We demonstrate the representation power of MiShape and its utility for 3D shape reconstruction given a single 2D fluorescence image or a small 3D stack of 2D slices. We also showcase applications of our method by deriving simulated fluorescence microscope datasets that have realistic 3D ground truths for the problem of 2D segmentation and microscope-to-microscope transformation.
BABEL: Bodies, Action and Behavior with English Labels
Jun 23, 2021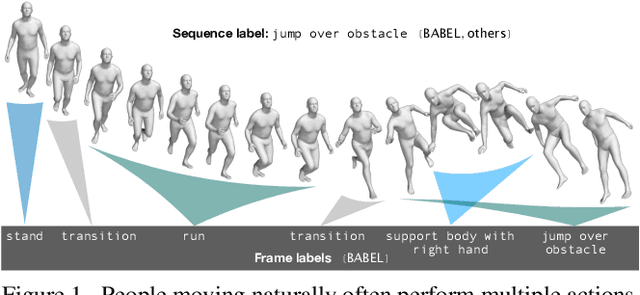
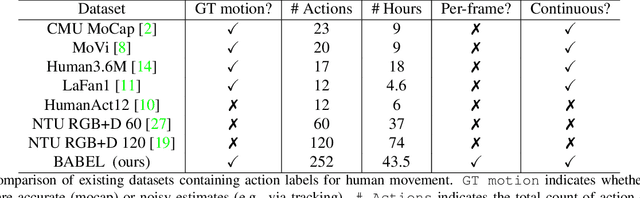


Understanding the semantics of human movement -- the what, how and why of the movement -- is an important problem that requires datasets of human actions with semantic labels. Existing datasets take one of two approaches. Large-scale video datasets contain many action labels but do not contain ground-truth 3D human motion. Alternatively, motion-capture (mocap) datasets have precise body motions but are limited to a small number of actions. To address this, we present BABEL, a large dataset with language labels describing the actions being performed in mocap sequences. BABEL consists of action labels for about 43 hours of mocap sequences from AMASS. Action labels are at two levels of abstraction -- sequence labels describe the overall action in the sequence, and frame labels describe all actions in every frame of the sequence. Each frame label is precisely aligned with the duration of the corresponding action in the mocap sequence, and multiple actions can overlap. There are over 28k sequence labels, and 63k frame labels in BABEL, which belong to over 250 unique action categories. Labels from BABEL can be leveraged for tasks like action recognition, temporal action localization, motion synthesis, etc. To demonstrate the value of BABEL as a benchmark, we evaluate the performance of models on 3D action recognition. We demonstrate that BABEL poses interesting learning challenges that are applicable to real-world scenarios, and can serve as a useful benchmark of progress in 3D action recognition. The dataset, baseline method, and evaluation code is made available, and supported for academic research purposes at https://babel.is.tue.mpg.de/.