 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepacketLSTM: Dynamic LSTM Framework for Streaming Data with Varying Feature Space
Oct 22, 2024



We study the online learning problem characterized by the varying input feature space of streaming data. Although LSTMs have been employed to effectively capture the temporal nature of streaming data, they cannot handle the dimension-varying streams in an online learning setting. Therefore, we propose a dynamic LSTM-based novel method, called packetLSTM, to model the dimension-varying streams. The packetLSTM's dynamic framework consists of an evolving packet of LSTMs, each dedicated to processing one input feature. Each LSTM retains the local information of its corresponding feature, while a shared common memory consolidates global information. This configuration facilitates continuous learning and mitigates the issue of forgetting, even when certain features are absent for extended time periods. The idea of utilizing one LSTM per feature coupled with a dimension-invariant operator for information aggregation enhances the dynamic nature of packetLSTM. This dynamic nature is evidenced by the model's ability to activate, deactivate, and add new LSTMs as required, thus seamlessly accommodating varying input dimensions. The packetLSTM achieves state-of-the-art results on five datasets, and its underlying principle is extended to other RNN types, like GRU and vanilla RNN.
Hedging Is Not All You Need: A Simple Baseline for Online Learning Under Haphazard Inputs
Sep 16, 2024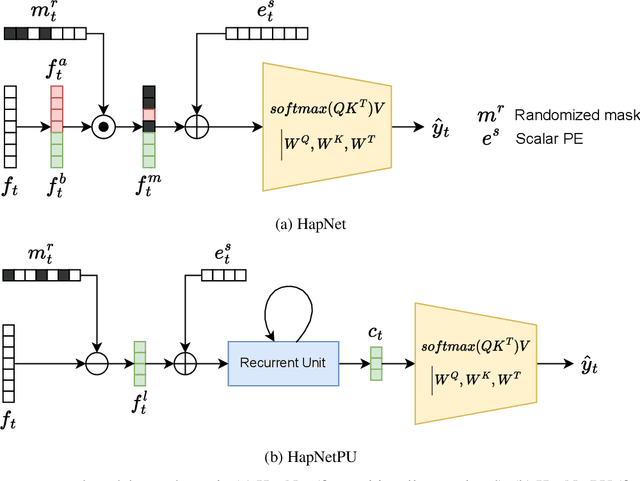
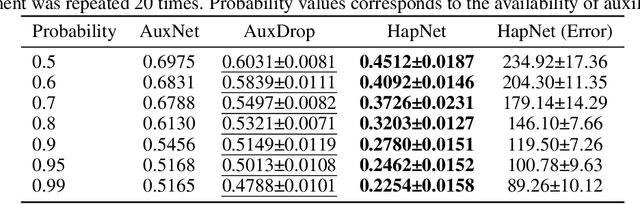


Handling haphazard streaming data, such as data from edge devices, presents a challenging problem. Over time, the incoming data becomes inconsistent, with missing, faulty, or new inputs reappearing. Therefore, it requires models that are reliable. Recent methods to solve this problem depend on a hedging-based solution and require specialized elements like auxiliary dropouts, forked architectures, and intricate network design. We observed that hedging can be reduced to a special case of weighted residual connection; this motivated us to approximate it with plain self-attention. In this work, we propose HapNet, a simple baseline that is scalable, does not require online backpropagation, and is adaptable to varying input types. All present methods are restricted to scaling with a fixed window; however, we introduce a more complex problem of scaling with a variable window where the data becomes positionally uncorrelated, and cannot be addressed by present methods. We demonstrate that a variant of the proposed approach can work even for this complex scenario. We extensively evaluated the proposed approach on five benchmarks and found competitive performance.
Towards a More Inclusive AI: Progress and Perspectives in Large Language Model Training for the Sámi Language
May 09, 2024S\'ami, an indigenous language group comprising multiple languages, faces digital marginalization due to the limited availability of data and sophisticated language models designed for its linguistic intricacies. This work focuses on increasing technological participation for the S\'ami language. We draw the attention of the ML community towards the language modeling problem of Ultra Low Resource (ULR) languages. ULR languages are those for which the amount of available textual resources is very low, and the speaker count for them is also very low. ULRLs are also not supported by mainstream Large Language Models (LLMs) like ChatGPT, due to which gathering artificial training data for them becomes even more challenging. Mainstream AI foundational model development has given less attention to this category of languages. Generally, these languages have very few speakers, making it hard to find them. However, it is important to develop foundational models for these ULR languages to promote inclusion and the tangible abilities and impact of LLMs. To this end, we have compiled the available S\'ami language resources from the web to create a clean dataset for training language models. In order to study the behavior of modern LLM models with ULR languages (S\'ami), we have experimented with different kinds of LLMs, mainly at the order of $\sim$ seven billion parameters. We have also explored the effect of multilingual LLM training for ULRLs. We found that the decoder-only models under a sequential multilingual training scenario perform better than joint multilingual training, whereas multilingual training with high semantic overlap, in general, performs better than training from scratch.This is the first study on the S\'ami language for adapting non-statistical language models that use the latest developments in the field of natural language processing (NLP).
Online Learning under Haphazard Input Conditions: A Comprehensive Review and Analysis
Apr 07, 2024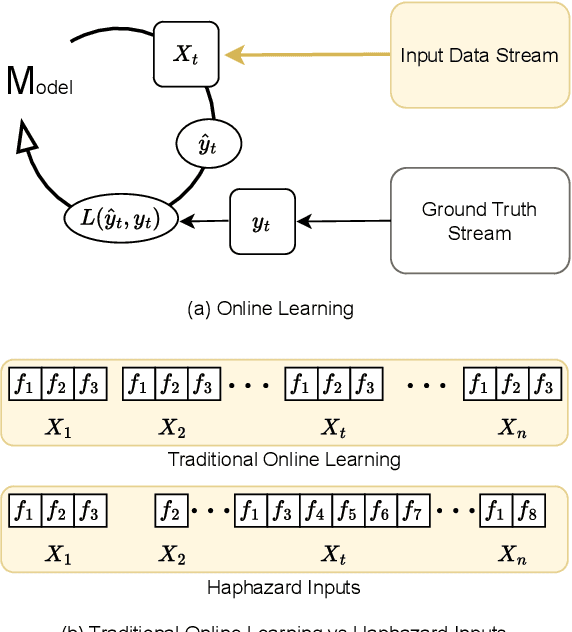
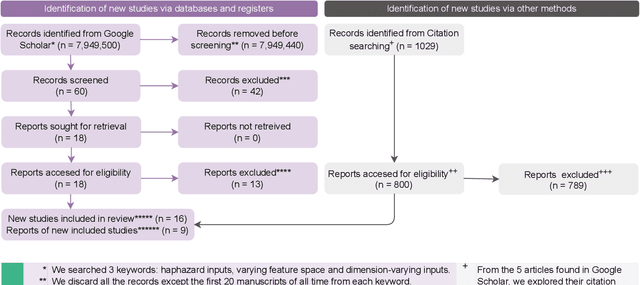
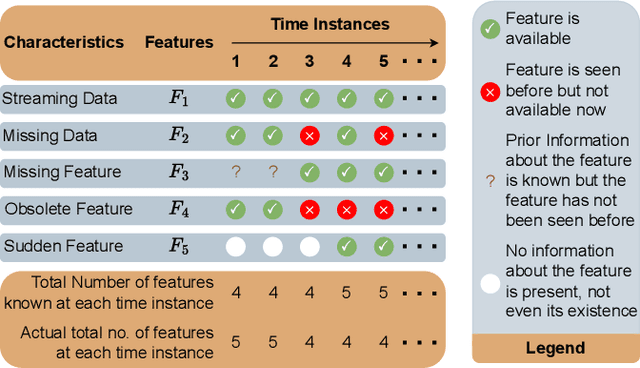
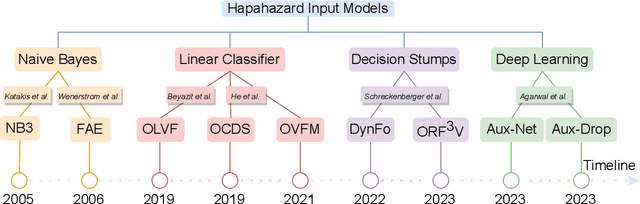
The domain of online learning has experienced multifaceted expansion owing to its prevalence in real-life applications. Nonetheless, this progression operates under the assumption that the input feature space of the streaming data remains constant. In this survey paper, we address the topic of online learning in the context of haphazard inputs, explicitly foregoing such an assumption. We discuss, classify, evaluate, and compare the methodologies that are adept at modeling haphazard inputs, additionally providing the corresponding code implementations and their carbon footprint. Moreover, we classify the datasets related to the field of haphazard inputs and introduce evaluation metrics specifically designed for datasets exhibiting imbalance. The code of each methodology can be found at https://github.com/Rohit102497/HaphazardInputsReview
Dense Video Captioning: A Survey of Techniques, Datasets and Evaluation Protocols
Nov 05, 2023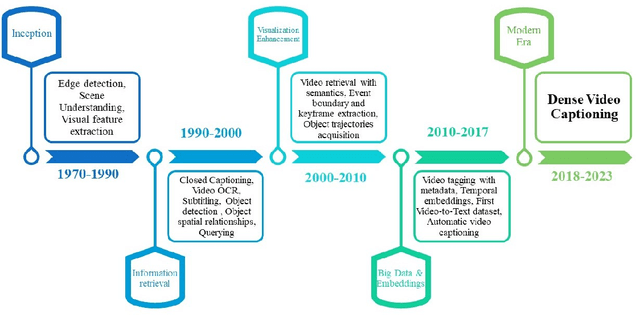
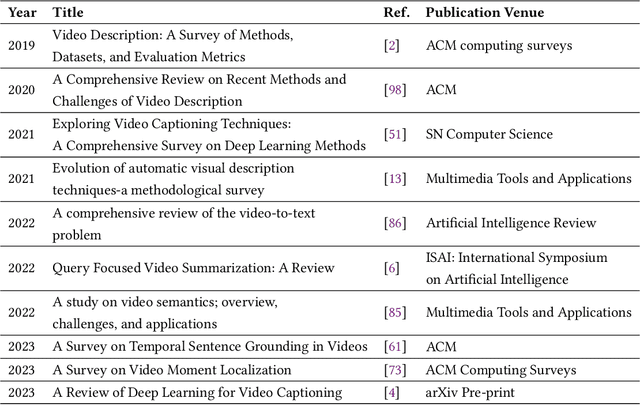
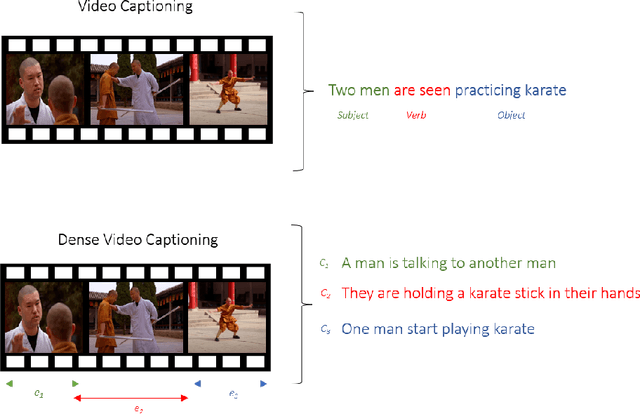

Untrimmed videos have interrelated events, dependencies, context, overlapping events, object-object interactions, domain specificity, and other semantics that are worth highlighting while describing a video in natural language. Owing to such a vast diversity, a single sentence can only correctly describe a portion of the video. Dense Video Captioning (DVC) aims at detecting and describing different events in a given video. The term DVC originated in the 2017 ActivityNet challenge, after which considerable effort has been made to address the challenge. Dense Video Captioning is divided into three sub-tasks: (1) Video Feature Extraction (VFE), (2) Temporal Event Localization (TEL), and (3) Dense Caption Generation (DCG). This review aims to discuss all the studies that claim to perform DVC along with its sub-tasks and summarize their results. We also discuss all the datasets that have been used for DVC. Lastly, we highlight some emerging challenges and future trends in the field.
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023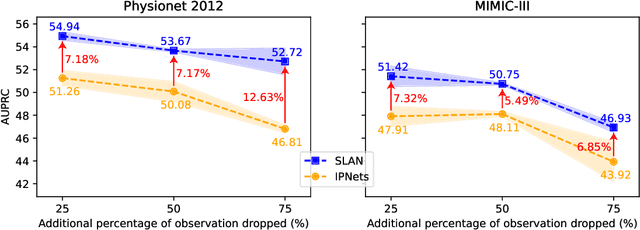
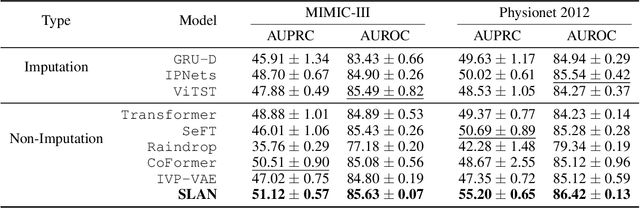
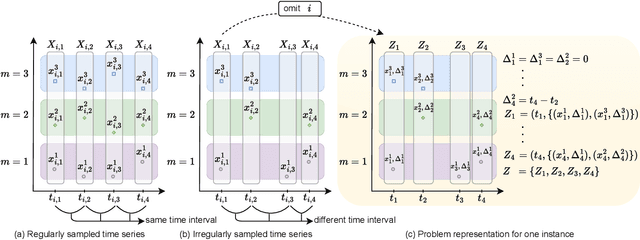
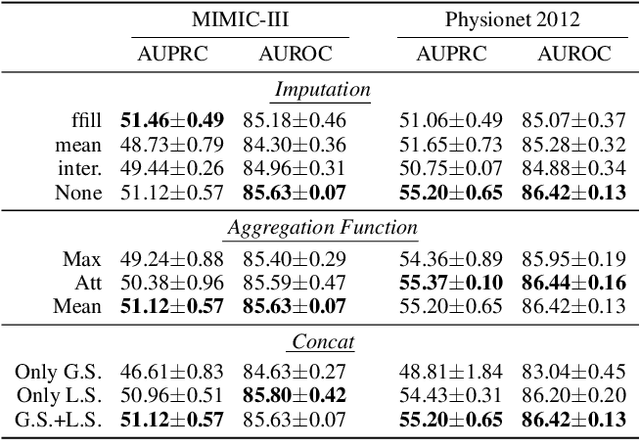
Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.
pNNCLR: Stochastic Pseudo Neighborhoods for Contrastive Learning based Unsupervised Representation Learning Problems
Aug 14, 2023
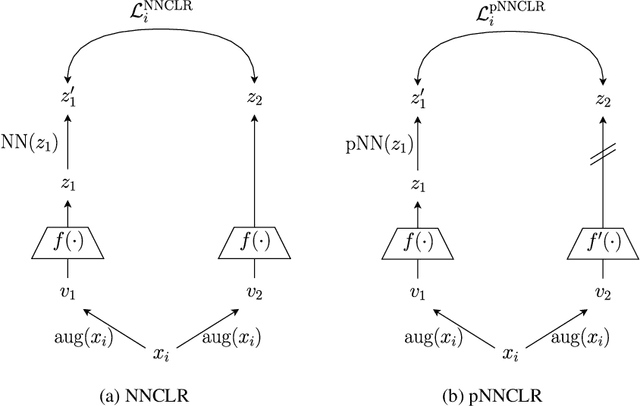
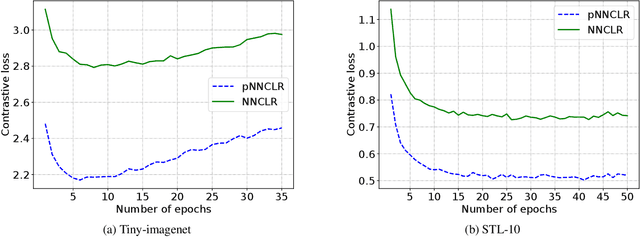

Nearest neighbor (NN) sampling provides more semantic variations than pre-defined transformations for self-supervised learning (SSL) based image recognition problems. However, its performance is restricted by the quality of the support set, which holds positive samples for the contrastive loss. In this work, we show that the quality of the support set plays a crucial role in any nearest neighbor based method for SSL. We then provide a refined baseline (pNNCLR) to the nearest neighbor based SSL approach (NNCLR). To this end, we introduce pseudo nearest neighbors (pNN) to control the quality of the support set, wherein, rather than sampling the nearest neighbors, we sample in the vicinity of hard nearest neighbors by varying the magnitude of the resultant vector and employing a stochastic sampling strategy to improve the performance. Additionally, to stabilize the effects of uncertainty in NN-based learning, we employ a smooth-weight-update approach for training the proposed network. Evaluation of the proposed method on multiple public image recognition and medical image recognition datasets shows that it performs up to 8 percent better than the baseline nearest neighbor method, and is comparable to other previously proposed SSL methods.
Latent Graph Attention for Enhanced Spatial Context
Jul 12, 2023
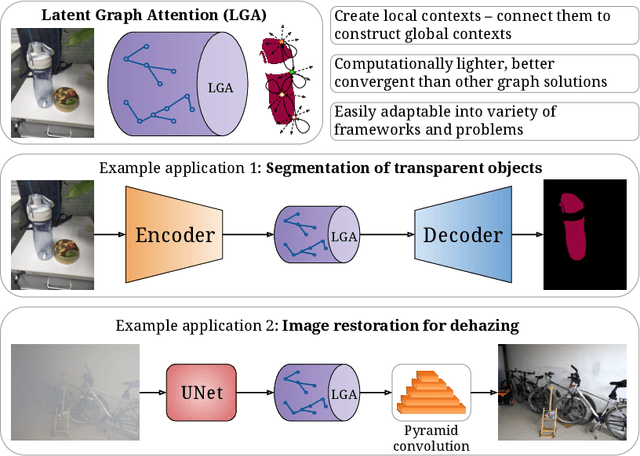
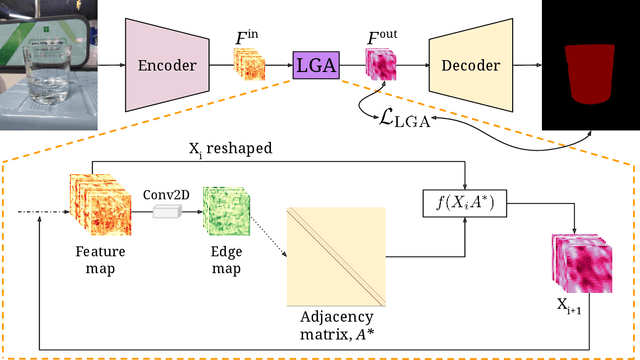
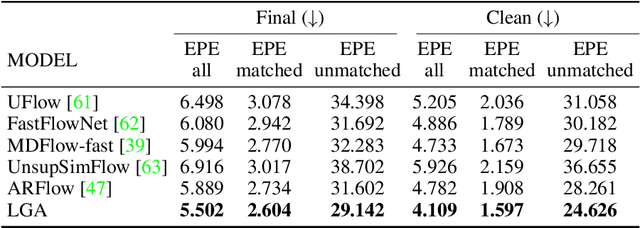
Global contexts in images are quite valuable in image-to-image translation problems. Conventional attention-based and graph-based models capture the global context to a large extent, however, these are computationally expensive. Moreover, the existing approaches are limited to only learning the pairwise semantic relation between any two points on the image. In this paper, we present Latent Graph Attention (LGA) a computationally inexpensive (linear to the number of nodes) and stable, modular framework for incorporating the global context in the existing architectures, especially empowering small-scale architectures to give performance closer to large size architectures, thus making the light-weight architectures more useful for edge devices with lower compute power and lower energy needs. LGA propagates information spatially using a network of locally connected graphs, thereby facilitating to construct a semantically coherent relation between any two spatially distant points that also takes into account the influence of the intermediate pixels. Moreover, the depth of the graph network can be used to adapt the extent of contextual spread to the target dataset, thereby being able to explicitly control the added computational cost. To enhance the learning mechanism of LGA, we also introduce a novel contrastive loss term that helps our LGA module to couple well with the original architecture at the expense of minimal additional computational load. We show that incorporating LGA improves the performance on three challenging applications, namely transparent object segmentation, image restoration for dehazing and optical flow estimation.
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
Aux-Drop: Handling Haphazard Inputs in Online Learning Using Auxiliary Dropouts
Mar 09, 2023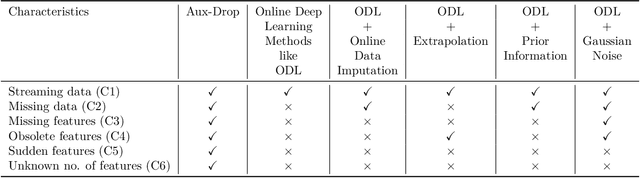
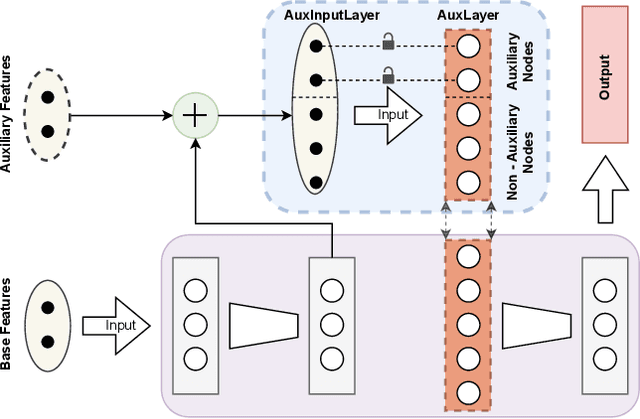
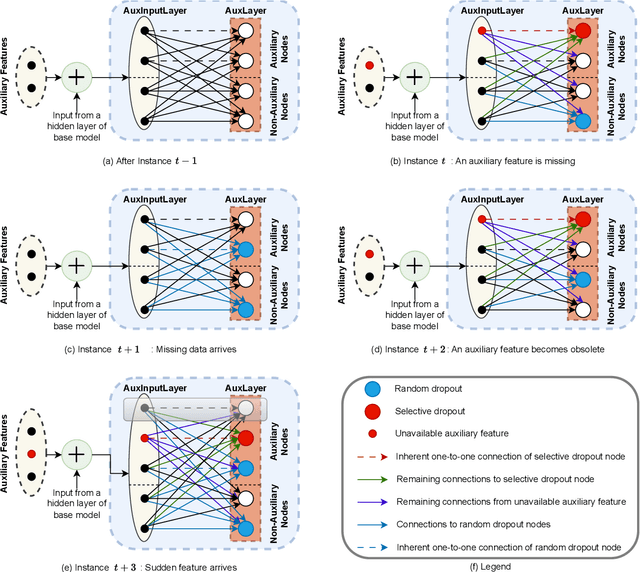

Many real-world applications based on online learning produce streaming data that is haphazard in nature, i.e., contains missing features, features becoming obsolete in time, the appearance of new features at later points in time and a lack of clarity on the total number of input features. These challenges make it hard to build a learnable system for such applications, and almost no work exists in deep learning that addresses this issue. In this paper, we present Aux-Drop, an auxiliary dropout regularization strategy for online learning that handles the haphazard input features in an effective manner. Aux-Drop adapts the conventional dropout regularization scheme for the haphazard input feature space ensuring that the final output is minimally impacted by the chaotic appearance of such features. It helps to prevent the co-adaptation of especially the auxiliary and base features, as well as reduces the strong dependence of the output on any of the auxiliary inputs of the model. This helps in better learning for scenarios where certain features disappear in time or when new features are to be modeled. The efficacy of Aux-Drop has been demonstrated through extensive numerical experiments on SOTA benchmarking datasets that include Italy Power Demand, HIGGS, SUSY and multiple UCI datasets.