 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATPO: Critique-Augmented Tree Policy Optimization
Jun 06, 2026Reinforcement learning with verifiable rewards (RLVR) has become a dominant paradigm for improving the reasoning capabilities of large language models (LLMs). Recent tree-based methods such as TreeRPO extend flat trajectory sampling with tree-structured rollouts to obtain dense, step-level reward signals without a separate process reward model. However, not all trees are equally informative: trees where all leaves succeed, all leaves fail, or the policy already predicts the reward distribution contribute little to gradient updates, wasting compute. We introduce CATPO (Critique-Augmented Tree Policy Optimization), which diagnoses and addresses this waste at the tree level. CATPO first scores each tree via a tree informativeness score, F(T), combining leaf-outcome diversity with policy-reward decorrelation at zero extra compute. For dead-wrong trees where all branches fail, CATPO applies critique-guided healing: it locates the shallowest failure point, generates a natural-language critique, and grafts refined continuations to recover training signal. Finally, an informativeness-weighted loss scales each tree's gradient contribution by its normalized score, concentrating parameter updates on the most informative trees while preserving overall gradient magnitude. Experiments on Qwen2.5-Math-1.5B trained with the MATH dataset show that CATPO achieves 37.5% macro accuracy across four benchmarks (AIME24, MATH-500, OlympiadBench, and MinervaMath), improving over TreeRPO by 1.9% and GRPO by 4.8%.
SIDiffAgent: Self-Improving Diffusion Agent
Feb 02, 2026Text-to-image diffusion models have revolutionized generative AI, enabling high-quality and photorealistic image synthesis. However, their practical deployment remains hindered by several limitations: sensitivity to prompt phrasing, ambiguity in semantic interpretation (e.g., ``mouse" as animal vs. a computer peripheral), artifacts such as distorted anatomy, and the need for carefully engineered input prompts. Existing methods often require additional training and offer limited controllability, restricting their adaptability in real-world applications. We introduce Self-Improving Diffusion Agent (SIDiffAgent), a training-free agentic framework that leverages the Qwen family of models (Qwen-VL, Qwen-Image, Qwen-Edit, Qwen-Embedding) to address these challenges. SIDiffAgent autonomously manages prompt engineering, detects and corrects poor generations, and performs fine-grained artifact removal, yielding more reliable and consistent outputs. It further incorporates iterative self-improvement by storing a memory of previous experiences in a database. This database of past experiences is then used to inject prompt-based guidance at each stage of the agentic pipeline. \modelour achieved an average VQA score of 0.884 on GenAIBench, significantly outperforming open-source, proprietary models and agentic methods. We will publicly release our code upon acceptance.
RAVU: Retrieval Augmented Video Understanding with Compositional Reasoning over Graph
May 06, 2025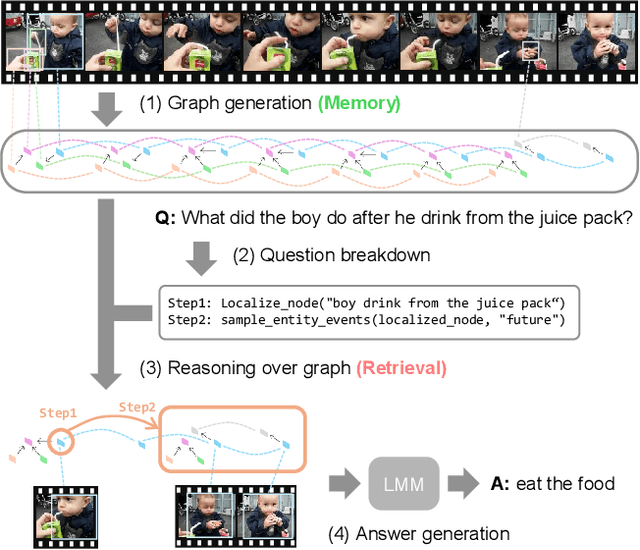
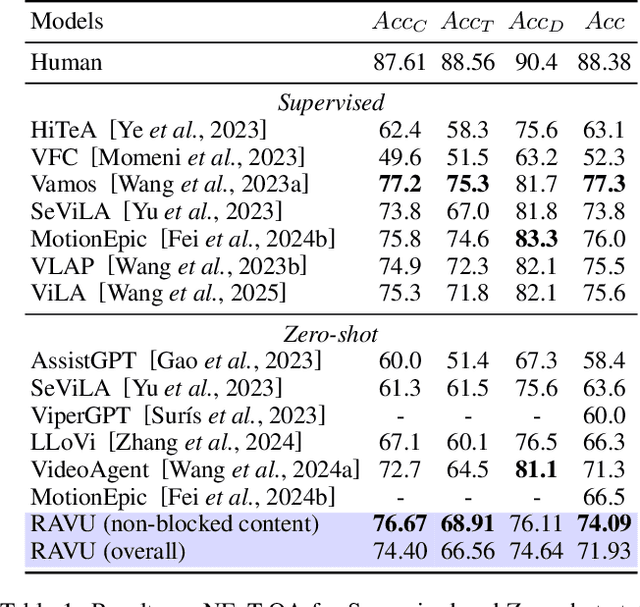
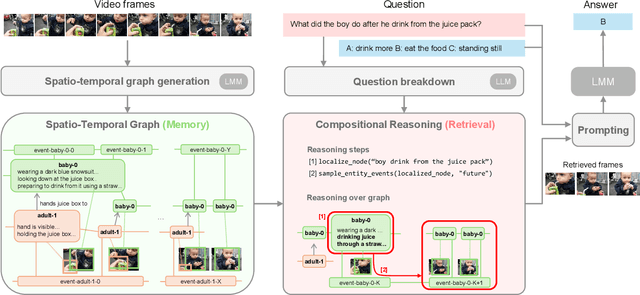
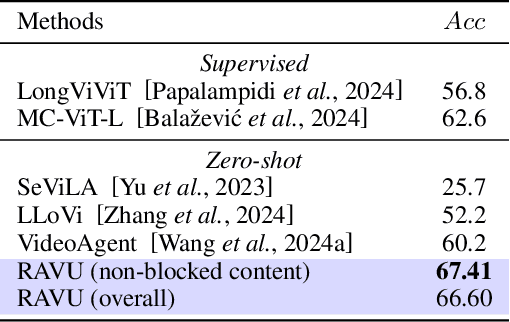
Comprehending long videos remains a significant challenge for Large Multi-modal Models (LMMs). Current LMMs struggle to process even minutes to hours videos due to their lack of explicit memory and retrieval mechanisms. To address this limitation, we propose RAVU (Retrieval Augmented Video Understanding), a novel framework for video understanding enhanced by retrieval with compositional reasoning over a spatio-temporal graph. We construct a graph representation of the video, capturing both spatial and temporal relationships between entities. This graph serves as a long-term memory, allowing us to track objects and their actions across time. To answer complex queries, we decompose the queries into a sequence of reasoning steps and execute these steps on the graph, retrieving relevant key information. Our approach enables more accurate understanding of long videos, particularly for queries that require multi-hop reasoning and tracking objects across frames. Our approach demonstrate superior performances with limited retrieved frames (5-10) compared with other SOTA methods and baselines on two major video QA datasets, NExT-QA and EgoSchema.
IPO: Your Language Model is Secretly a Preference Classifier
Feb 22, 2025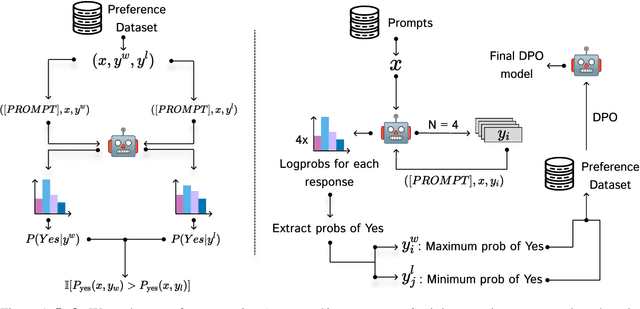
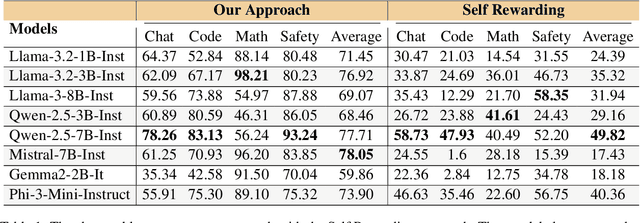

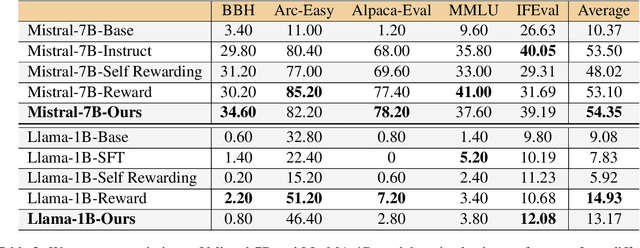
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. While it enables LLMs to achieve human-level alignment, it often incurs significant computational and financial costs due to its reliance on training external reward models or human-labeled preferences. In this work, we propose \textbf{Implicit Preference Optimization (IPO)}, an alternative approach that leverages generative LLMs as preference classifiers, thereby reducing the dependence on external human feedback or reward models to obtain preferences. We conduct a comprehensive evaluation on the preference classification ability of LLMs using RewardBench, assessing models across different sizes, architectures, and training levels to validate our hypothesis. Furthermore, we investigate the self-improvement capabilities of LLMs by generating multiple responses for a given instruction and employing the model itself as a preference classifier for Direct Preference Optimization (DPO)-based training. Our findings demonstrate that models trained through IPO achieve performance comparable to those utilizing state-of-the-art reward models for obtaining preferences.
Adaptive Urban Planning: A Hybrid Framework for Balanced City Development
Dec 19, 2024



Urban planning faces a critical challenge in balancing city-wide infrastructure needs with localized demographic preferences, particularly in rapidly developing regions. Although existing approaches typically focus on top-down optimization or bottom-up community planning, only some frameworks successfully integrate both perspectives. Our methodology employs a two-tier approach: First, a deterministic solver optimizes basic infrastructure requirements in the city region. Second, four specialized planning agents, each representing distinct sub-regions, propose demographic-specific modifications to a master planner. The master planner then evaluates and integrates these suggestions to ensure cohesive urban development. We validate our framework using a newly created dataset comprising detailed region and sub-region maps from three developing cities in India, focusing on areas undergoing rapid urbanization. The results demonstrate that this hybrid approach enables more nuanced urban development while maintaining overall city functionality.
LoRA-Mini : Adaptation Matrices Decomposition and Selective Training
Nov 24, 2024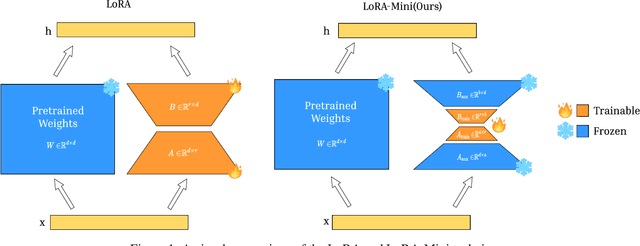
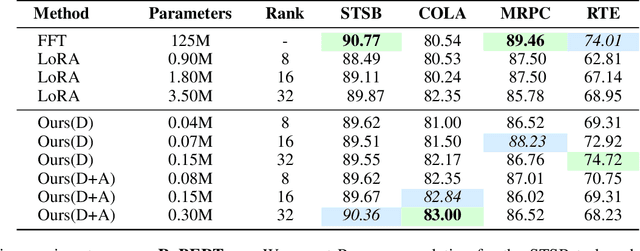

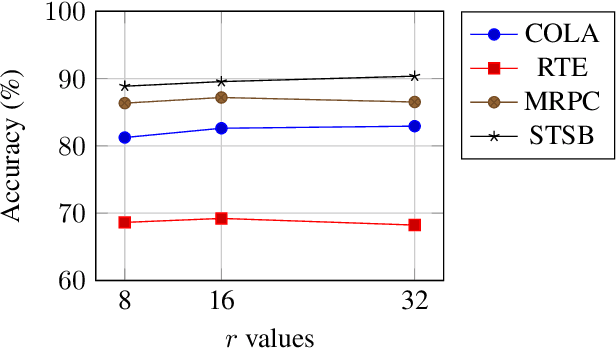
The rapid advancements in large language models (LLMs) have revolutionized natural language processing, creating an increased need for efficient, task-specific fine-tuning methods. Traditional fine-tuning of LLMs involves updating a large number of parameters, which is computationally expensive and memory-intensive. Low-Rank Adaptation (LoRA) has emerged as a promising solution, enabling parameter-efficient fine-tuning by reducing the number of trainable parameters. However, while LoRA reduces the number of trainable parameters, LoRA modules still create significant storage challenges. We propose LoRA-Mini, an optimized adaptation of LoRA that improves parameter efficiency by splitting low-rank matrices into four parts, with only the two inner matrices being trainable. This approach achieves upto a 20x reduction compared to standard LoRA in the number of trainable parameters while preserving performance levels comparable to standard LoRA, addressing both computational and storage efficiency in LLM fine-tuning.
Are VLMs Really Blind
Oct 29, 2024

Vision Language Models excel in handling a wide range of complex tasks, including Optical Character Recognition (OCR), Visual Question Answering (VQA), and advanced geometric reasoning. However, these models fail to perform well on low-level basic visual tasks which are especially easy for humans. Our goal in this work was to determine if these models are truly "blind" to geometric reasoning or if there are ways to enhance their capabilities in this area. Our work presents a novel automatic pipeline designed to extract key information from images in response to specific questions. Instead of just relying on direct VQA, we use question-derived keywords to create a caption that highlights important details in the image related to the question. This caption is then used by a language model to provide a precise answer to the question without requiring external fine-tuning.
Beyond Captioning: Task-Specific Prompting for Improved VLM Performance in Mathematical Reasoning
Oct 08, 2024



Vision-Language Models (VLMs) have transformed tasks requiring visual and reasoning abilities, such as image retrieval and Visual Question Answering (VQA). Despite their success, VLMs face significant challenges with tasks involving geometric reasoning, algebraic problem-solving, and counting. These limitations stem from difficulties effectively integrating multiple modalities and accurately interpreting geometry-related tasks. Various works claim that introducing a captioning pipeline before VQA tasks enhances performance. We incorporated this pipeline for tasks involving geometry, algebra, and counting. We found that captioning results are not generalizable, specifically with larger VLMs primarily trained on downstream QnA tasks showing random performance on math-related challenges. However, we present a promising alternative: task-based prompting, enriching the prompt with task-specific guidance. This approach shows promise and proves more effective than direct captioning methods for math-heavy problems.
Robustness of LLMs to Perturbations in Text
Jul 12, 2024



Having a clean dataset has been the foundational assumption of most natural language processing (NLP) systems. However, properly written text is rarely found in real-world scenarios and hence, oftentimes invalidates the aforementioned foundational assumption. Recently, Large language models (LLMs) have shown impressive performance, but can they handle the inevitable noise in real-world data? This work tackles this critical question by investigating LLMs' resilience against morphological variations in text. To that end, we artificially introduce varying levels of noise into a diverse set of datasets and systematically evaluate LLMs' robustness against the corrupt variations of the original text. Our findings show that contrary to popular beliefs, generative LLMs are quiet robust to noisy perturbations in text. This is a departure from pre-trained models like BERT or RoBERTa whose performance has been shown to be sensitive to deteriorating noisy text. Additionally, we test LLMs' resilience on multiple real-world benchmarks that closely mimic commonly found errors in the wild. With minimal prompting, LLMs achieve a new state-of-the-art on the benchmark tasks of Grammar Error Correction (GEC) and Lexical Semantic Change (LSC). To empower future research, we also release a dataset annotated by humans stating their preference for LLM vs. human-corrected outputs along with the code to reproduce our results.
Can GPT Redefine Medical Understanding? Evaluating GPT on Biomedical Machine Reading Comprehension
May 29, 2024

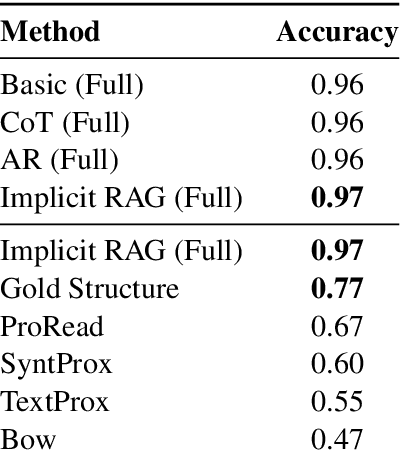

Large language models (LLMs) have shown remarkable performance on many tasks in different domains. However, their performance in closed-book biomedical machine reading comprehension (MRC) has not been evaluated in depth. In this work, we evaluate GPT on four closed-book biomedical MRC benchmarks. We experiment with different conventional prompting techniques as well as introduce our own novel prompting method. To solve some of the retrieval problems inherent to LLMs, we propose a prompting strategy named Implicit Retrieval Augmented Generation (RAG) that alleviates the need for using vector databases to retrieve important chunks in traditional RAG setups. Moreover, we report qualitative assessments on the natural language generation outputs from our approach. The results show that our new prompting technique is able to get the best performance in two out of four datasets and ranks second in rest of them. Experiments show that modern-day LLMs like GPT even in a zero-shot setting can outperform supervised models, leading to new state-of-the-art (SoTA) results on two of the benchmarks.