 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT Redefine Medical Understanding? Evaluating GPT on Biomedical Machine Reading Comprehension
Paper and Code
May 29, 2024

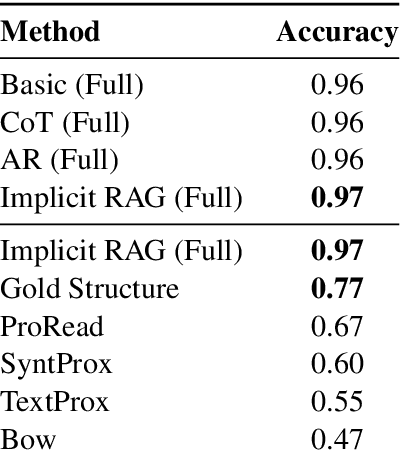

Large language models (LLMs) have shown remarkable performance on many tasks in different domains. However, their performance in closed-book biomedical machine reading comprehension (MRC) has not been evaluated in depth. In this work, we evaluate GPT on four closed-book biomedical MRC benchmarks. We experiment with different conventional prompting techniques as well as introduce our own novel prompting method. To solve some of the retrieval problems inherent to LLMs, we propose a prompting strategy named Implicit Retrieval Augmented Generation (RAG) that alleviates the need for using vector databases to retrieve important chunks in traditional RAG setups. Moreover, we report qualitative assessments on the natural language generation outputs from our approach. The results show that our new prompting technique is able to get the best performance in two out of four datasets and ranks second in rest of them. Experiments show that modern-day LLMs like GPT even in a zero-shot setting can outperform supervised models, leading to new state-of-the-art (SoTA) results on two of the benchmarks.