 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI in Healthcare & Medicine: A Seven-Dimensional Taxonomy for Empirical Evaluation of LLM-based Agents
Feb 04, 2026Large Language Model (LLM)-based agents that plan, use tools and act has begun to shape healthcare and medicine. Reported studies demonstrate competence on various tasks ranging from EHR analysis and differential diagnosis to treatment planning and research workflows. Yet the literature largely consists of overviews which are either broad surveys or narrow dives into a single capability (e.g., memory, planning, reasoning), leaving healthcare work without a common frame. We address this by reviewing 49 studies using a seven-dimensional taxonomy: Cognitive Capabilities, Knowledge Management, Interaction Patterns, Adaptation & Learning, Safety & Ethics, Framework Typology and Core Tasks & Subtasks with 29 operational sub-dimensions. Using explicit inclusion and exclusion criteria and a labeling rubric (Fully Implemented, Partially Implemented, Not Implemented), we map each study to the taxonomy and report quantitative summaries of capability prevalence and co-occurrence patterns. Our empirical analysis surfaces clear asymmetries. For instance, the External Knowledge Integration sub-dimension under Knowledge Management is commonly realized (~76% Fully Implemented) whereas Event-Triggered Activation sub-dimenison under Interaction Patterns is largely absent (~92% Not Implemented) and Drift Detection & Mitigation sub-dimension under Adaptation & Learning is rare (~98% Not Implemented). Architecturally, Multi-Agent Design sub-dimension under Framework Typology is the dominant pattern (~82% Fully Implemented) while orchestration layers remain mostly partial. Across Core Tasks & Subtasks, information centric capabilities lead e.g., Medical Question Answering & Decision Support and Benchmarking & Simulation, while action and discovery oriented areas such as Treatment Planning & Prescription still show substantial gaps (~59% Not Implemented).
Multilingual Prompt Engineering in Large Language Models: A Survey Across NLP Tasks
May 16, 2025Large language models (LLMs) have demonstrated impressive performance across a wide range of Natural Language Processing (NLP) tasks. However, ensuring their effectiveness across multiple languages presents unique challenges. Multilingual prompt engineering has emerged as a key approach to enhance LLMs' capabilities in diverse linguistic settings without requiring extensive parameter re-training or fine-tuning. With growing interest in multilingual prompt engineering over the past two to three years, researchers have explored various strategies to improve LLMs' performance across languages and NLP tasks. By crafting structured natural language prompts, researchers have successfully extracted knowledge from LLMs across different languages, making these techniques an accessible pathway for a broader audience, including those without deep expertise in machine learning, to harness the capabilities of LLMs. In this paper, we survey and categorize different multilingual prompting techniques based on the NLP tasks they address across a diverse set of datasets that collectively span around 250 languages. We further highlight the LLMs employed, present a taxonomy of approaches and discuss potential state-of-the-art (SoTA) methods for specific multilingual datasets. Additionally, we derive a range of insights across language families and resource levels (high-resource vs. low-resource), including analyses such as the distribution of NLP tasks by language resource type and the frequency of prompting methods across different language families. Our survey reviews 36 research papers covering 39 prompting techniques applied to 30 multilingual NLP tasks, with the majority of these studies published in the last two years.
A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
Jul 17, 2024



Large language models (LLMs) have shown remarkable performance on many different Natural Language Processing (NLP) tasks. Prompt engineering plays a key role in adding more to the already existing abilities of LLMs to achieve significant performance gains on various NLP tasks. Prompt engineering requires composing natural language instructions called prompts to elicit knowledge from LLMs in a structured way. Unlike previous state-of-the-art (SoTA) models, prompt engineering does not require extensive parameter re-training or fine-tuning based on the given NLP task and thus solely operates on the embedded knowledge of LLMs. Additionally, LLM enthusiasts can intelligently extract LLMs' knowledge through a basic natural language conversational exchange or prompt engineering, allowing more and more people even without deep mathematical machine learning background to experiment with LLMs. With prompt engineering gaining popularity in the last two years, researchers have come up with numerous engineering techniques around designing prompts to improve accuracy of information extraction from the LLMs. In this paper, we summarize different prompting techniques and club them together based on different NLP tasks that they have been used for. We further granularly highlight the performance of these prompting strategies on various datasets belonging to that NLP task, talk about the corresponding LLMs used, present a taxonomy diagram and discuss the possible SoTA for specific datasets. In total, we read and present a survey of 44 research papers which talk about 39 different prompting methods on 29 different NLP tasks of which most of them have been published in the last two years.
Robustness of LLMs to Perturbations in Text
Jul 12, 2024



Having a clean dataset has been the foundational assumption of most natural language processing (NLP) systems. However, properly written text is rarely found in real-world scenarios and hence, oftentimes invalidates the aforementioned foundational assumption. Recently, Large language models (LLMs) have shown impressive performance, but can they handle the inevitable noise in real-world data? This work tackles this critical question by investigating LLMs' resilience against morphological variations in text. To that end, we artificially introduce varying levels of noise into a diverse set of datasets and systematically evaluate LLMs' robustness against the corrupt variations of the original text. Our findings show that contrary to popular beliefs, generative LLMs are quiet robust to noisy perturbations in text. This is a departure from pre-trained models like BERT or RoBERTa whose performance has been shown to be sensitive to deteriorating noisy text. Additionally, we test LLMs' resilience on multiple real-world benchmarks that closely mimic commonly found errors in the wild. With minimal prompting, LLMs achieve a new state-of-the-art on the benchmark tasks of Grammar Error Correction (GEC) and Lexical Semantic Change (LSC). To empower future research, we also release a dataset annotated by humans stating their preference for LLM vs. human-corrected outputs along with the code to reproduce our results.
Can GPT Redefine Medical Understanding? Evaluating GPT on Biomedical Machine Reading Comprehension
May 29, 2024

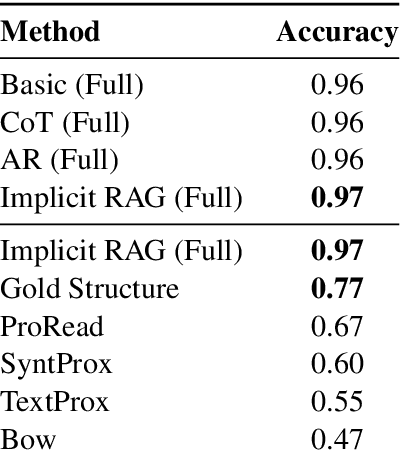

Large language models (LLMs) have shown remarkable performance on many tasks in different domains. However, their performance in closed-book biomedical machine reading comprehension (MRC) has not been evaluated in depth. In this work, we evaluate GPT on four closed-book biomedical MRC benchmarks. We experiment with different conventional prompting techniques as well as introduce our own novel prompting method. To solve some of the retrieval problems inherent to LLMs, we propose a prompting strategy named Implicit Retrieval Augmented Generation (RAG) that alleviates the need for using vector databases to retrieve important chunks in traditional RAG setups. Moreover, we report qualitative assessments on the natural language generation outputs from our approach. The results show that our new prompting technique is able to get the best performance in two out of four datasets and ranks second in rest of them. Experiments show that modern-day LLMs like GPT even in a zero-shot setting can outperform supervised models, leading to new state-of-the-art (SoTA) results on two of the benchmarks.
Can GPT Improve the State of Prior Authorization via Guideline Based Automated Question Answering?
Feb 28, 2024


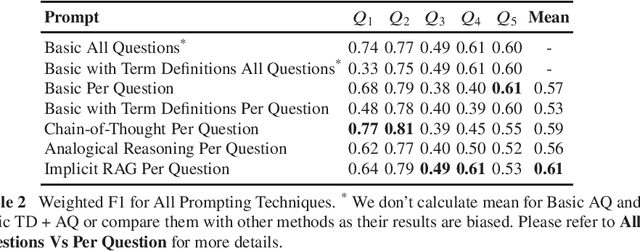
Health insurance companies have a defined process called prior authorization (PA) which is a health plan cost-control process that requires doctors and other healthcare professionals to get clearance in advance from a health plan before performing a particular procedure on a patient in order to be eligible for payment coverage. For health insurance companies, approving PA requests for patients in the medical domain is a time-consuming and challenging task. One of those key challenges is validating if a request matches up to certain criteria such as age, gender, etc. In this work, we evaluate whether GPT can validate numerous key factors, in turn helping health plans reach a decision drastically faster. We frame it as a question answering task, prompting GPT to answer a question from patient electronic health record. We experiment with different conventional prompting techniques as well as introduce our own novel prompting technique. Moreover, we report qualitative assessment by humans on the natural language generation outputs from our approach. Results show that our method achieves superior performance with the mean weighted F1 score of 0.61 as compared to its standard counterparts.
Emotion Classification in Low and Moderate Resource Languages
Feb 28, 2024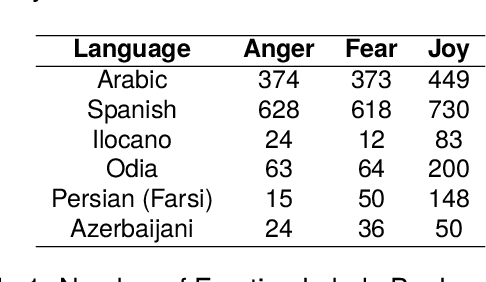

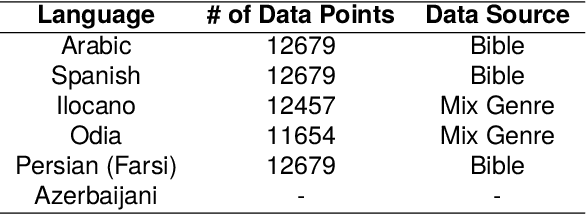

It is important to be able to analyze the emotional state of people around the globe. There are 7100+ active languages spoken around the world and building emotion classification for each language is labor intensive. Particularly for low-resource and endangered languages, building emotion classification can be quite challenging. We present a cross-lingual emotion classifier, where we train an emotion classifier with resource-rich languages (i.e. \textit{English} in our work) and transfer the learning to low and moderate resource languages. We compare and contrast two approaches of transfer learning from a high-resource language to a low or moderate-resource language. One approach projects the annotation from a high-resource language to low and moderate-resource language in parallel corpora and the other one uses direct transfer from high-resource language to the other languages. We show the efficacy of our approaches on 6 languages: Farsi, Arabic, Spanish, Ilocano, Odia, and Azerbaijani. Our results indicate that our approaches outperform random baselines and transfer emotions across languages successfully. For all languages, the direct cross-lingual transfer of emotion yields better results. We also create annotated emotion-labeled resources for four languages: Farsi, Azerbaijani, Ilocano and Odia.
Classification of US Supreme Court Cases using BERT-Based Techniques
Apr 17, 2023
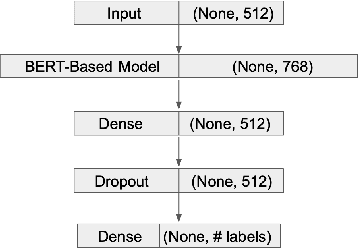
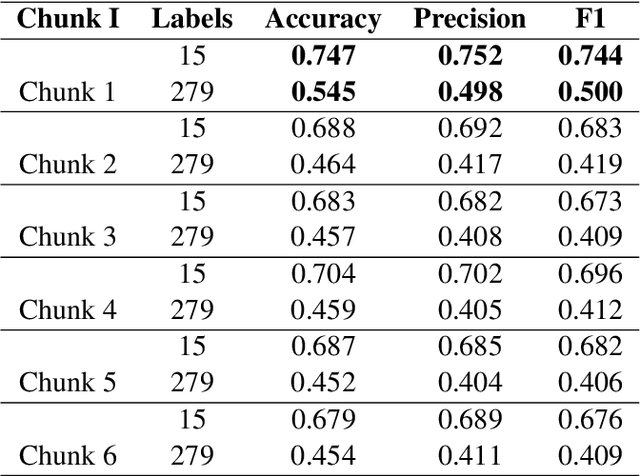
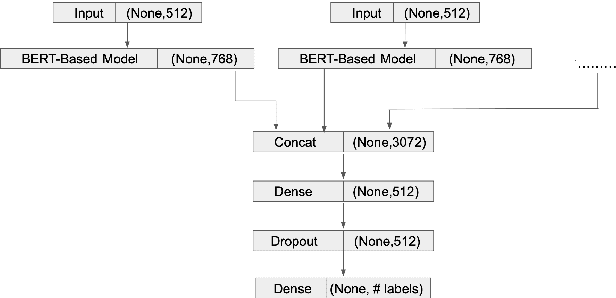
Models based on bidirectional encoder representations from transformers (BERT) produce state of the art (SOTA) results on many natural language processing (NLP) tasks such as named entity recognition (NER), part-of-speech (POS) tagging etc. An interesting phenomenon occurs when classifying long documents such as those from the US supreme court where BERT-based models can be considered difficult to use on a first-pass or out-of-the-box basis. In this paper, we experiment with several BERT-based classification techniques for US supreme court decisions or supreme court database (SCDB) and compare them with the previous SOTA results. We then compare our results specifically with SOTA models for long documents. We compare our results for two classification tasks: (1) a broad classification task with 15 categories and (2) a fine-grained classification task with 279 categories. Our best result produces an accuracy of 80\% on the 15 broad categories and 60\% on the fine-grained 279 categories which marks an improvement of 8\% and 28\% respectively from previously reported SOTA results.
Codeswitched Sentence Creation using Dependency Parsing
Dec 05, 2020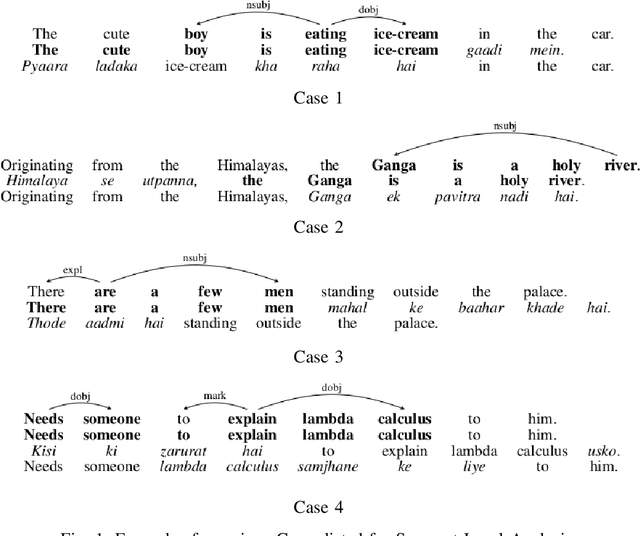
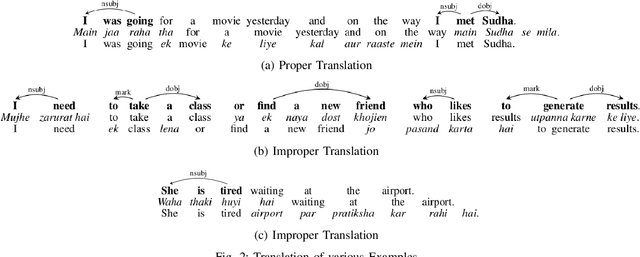

Codeswitching has become one of the most common occurrences across multilingual speakers of the world, especially in countries like India which encompasses around 23 official languages with the number of bilingual speakers being around 300 million. The scarcity of Codeswitched data becomes a bottleneck in the exploration of this domain with respect to various Natural Language Processing (NLP) tasks. We thus present a novel algorithm which harnesses the syntactic structure of English grammar to develop grammatically sensible Codeswitched versions of English-Hindi, English-Marathi and English-Kannada data. Apart from maintaining the grammatical sanity to a great extent, our methodology also guarantees abundant generation of data from a minuscule snapshot of given data. We use multiple datasets to showcase the capabilities of our algorithm while at the same time we assess the quality of generated Codeswitched data using some qualitative metrics along with providing baseline results for couple of NLP tasks.
On-Device Tag Generation for Unstructured Text
Dec 05, 2020



With the overwhelming transition to smart phones, storing important information in the form of unstructured text has become habitual to users of mobile devices. From grocery lists to drafts of emails and important speeches, users store a lot of data in the form of unstructured text (for eg: in the Notes application) on their devices, leading to cluttering of data. This not only prevents users from efficient navigation in the applications but also precludes them from perceiving the relations that could be present across data in those applications. This paper proposes a novel pipeline to generate a set of tags using world knowledge based on the keywords and concepts present in unstructured textual data. These tags can then be used to summarize, categorize or search for the desired information thus enhancing user experience by allowing them to have a holistic outlook of the kind of information stored in the form of unstructured text. In the proposed system, we use an on-device (mobile phone) efficient CNN model with pruned ConceptNet resource to achieve our goal. The architecture also presents a novel ranking algorithm to extract the top n tags from any given text.