 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Spatial Attention based Sequence Learning Approach for Scene Text Script Identification
Dec 01, 2021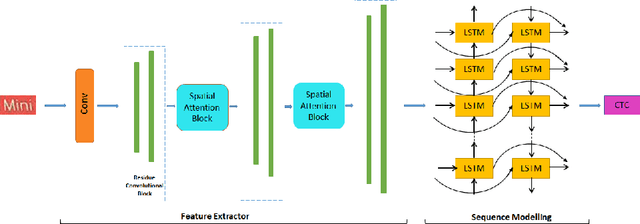
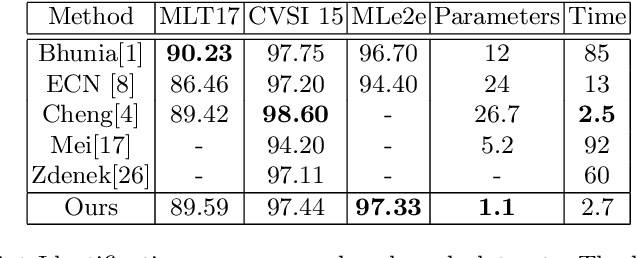
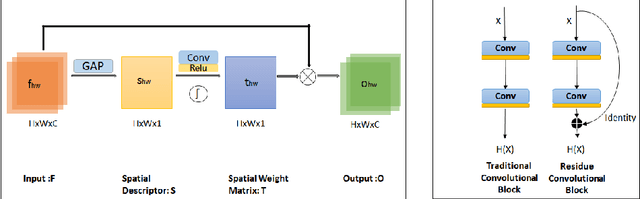
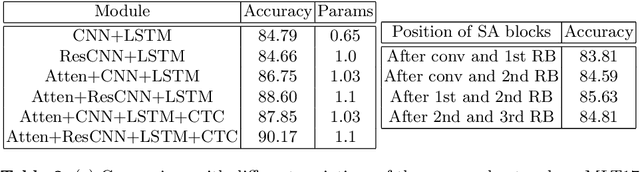
Automatic identification of script is an essential component of a multilingual OCR engine. In this paper, we present an efficient, lightweight, real-time and on-device spatial attention based CNN-LSTM network for scene text script identification, feasible for deployment on resource constrained mobile devices. Our network consists of a CNN, equipped with a spatial attention module which helps reduce the spatial distortions present in natural images. This allows the feature extractor to generate rich image representations while ignoring the deformities and thereby, enhancing the performance of this fine grained classification task. The network also employs residue convolutional blocks to build a deep network to focus on the discriminative features of a script. The CNN learns the text feature representation by identifying each character as belonging to a particular script and the long term spatial dependencies within the text are captured using the sequence learning capabilities of the LSTM layers. Combining the spatial attention mechanism with the residue convolutional blocks, we are able to enhance the performance of the baseline CNN to build an end-to-end trainable network for script identification. The experimental results on several standard benchmarks demonstrate the effectiveness of our method. The network achieves competitive accuracy with state-of-the-art methods and is superior in terms of network size, with a total of just 1.1 million parameters and inference time of 2.7 milliseconds.
STRIDE : Scene Text Recognition In-Device
May 17, 2021
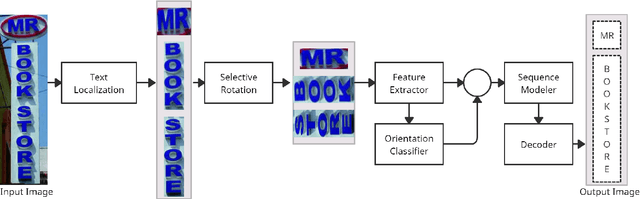
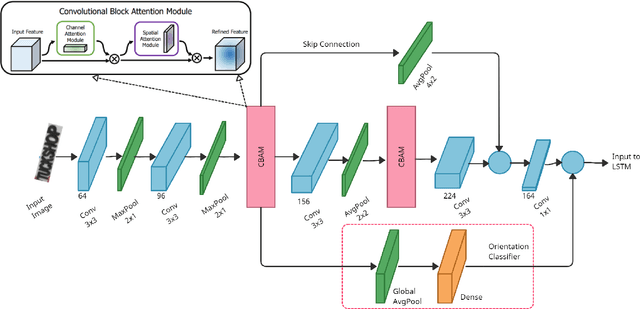

Optical Character Recognition (OCR) systems have been widely used in various applications for extracting semantic information from images. To give the user more control over their privacy, an on-device solution is needed. The current state-of-the-art models are too heavy and complex to be deployed on-device. We develop an efficient lightweight scene text recognition (STR) system, which has only 0.88M parameters and performs real-time text recognition. Attention modules tend to boost the accuracy of STR networks but are generally slow and not optimized for device inference. So, we propose the use of convolution attention modules to the text recognition networks, which aims to provide channel and spatial attention information to the LSTM module by adding very minimal computational cost. It boosts our word accuracy on ICDAR 13 dataset by almost 2\%. We also introduce a novel orientation classifier module, to support the simultaneous recognition of both horizontal and vertical text. The proposed model surpasses on-device metrics of inference time and memory footprint and achieves comparable accuracy when compared to the leading commercial and other open-source OCR engines. We deploy the system on-device with an inference speed of 2.44 ms per word on the Exynos 990 chipset device and achieve an accuracy of 88.4\% on ICDAR-13 dataset.
Codeswitched Sentence Creation using Dependency Parsing
Dec 05, 2020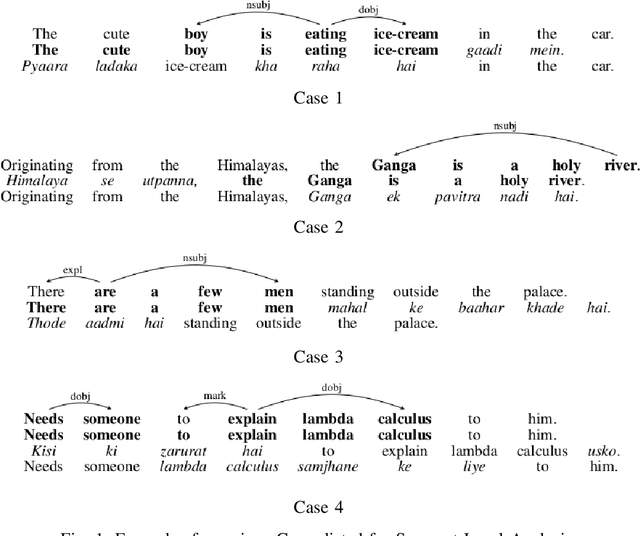
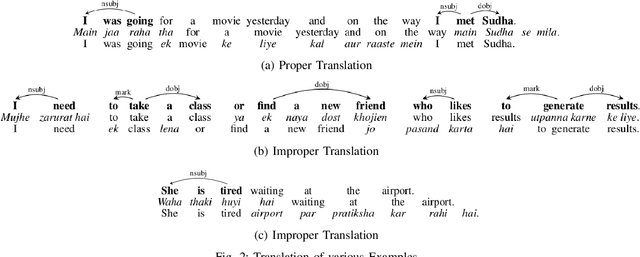

Codeswitching has become one of the most common occurrences across multilingual speakers of the world, especially in countries like India which encompasses around 23 official languages with the number of bilingual speakers being around 300 million. The scarcity of Codeswitched data becomes a bottleneck in the exploration of this domain with respect to various Natural Language Processing (NLP) tasks. We thus present a novel algorithm which harnesses the syntactic structure of English grammar to develop grammatically sensible Codeswitched versions of English-Hindi, English-Marathi and English-Kannada data. Apart from maintaining the grammatical sanity to a great extent, our methodology also guarantees abundant generation of data from a minuscule snapshot of given data. We use multiple datasets to showcase the capabilities of our algorithm while at the same time we assess the quality of generated Codeswitched data using some qualitative metrics along with providing baseline results for couple of NLP tasks.
On-Device Sentence Similarity for SMS Dataset
Dec 04, 2020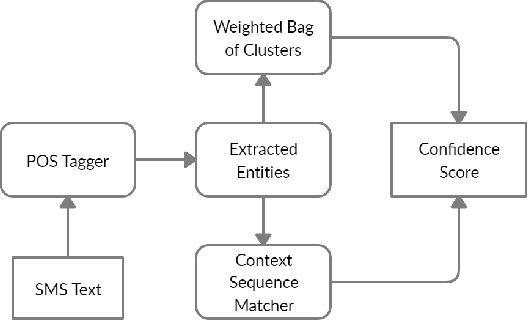

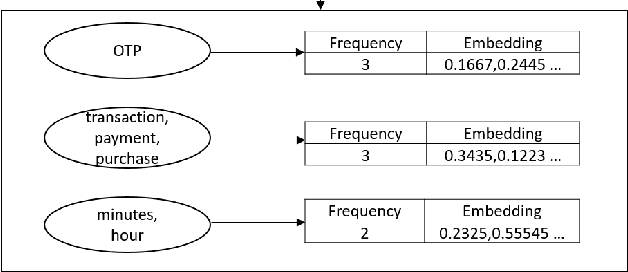
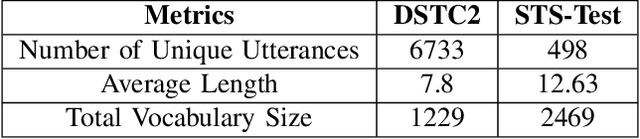
Determining the sentence similarity between Short Message Service (SMS) texts/sentences plays a significant role in mobile device industry. Gauging the similarity between SMS data is thus necessary for various applications like enhanced searching and navigation, clubbing together SMS of similar type when given a custom label or tag is provided by user irrespective of their sender etc. The problem faced with SMS data is its incomplete structure and grammatical inconsistencies. In this paper, we propose a unique pipeline for evaluating the text similarity between SMS texts. We use Part of Speech (POS) model for keyword extraction by taking advantage of the partial structure embedded in SMS texts and similarity comparisons are carried out using statistical methods. The proposed pipeline deals with major semantic variations across SMS data as well as makes it effective for its application on-device (mobile phone). To showcase the capabilities of our work, our pipeline has been designed with an inclination towards one of the possible applications of SMS text similarity discussed in one of the following sections but nonetheless guarantees scalability for other applications as well.
On-Device Text Image Super Resolution
Nov 20, 2020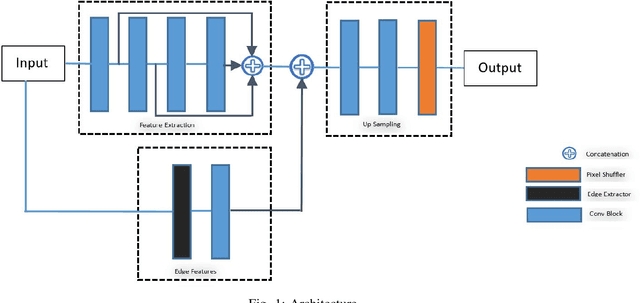

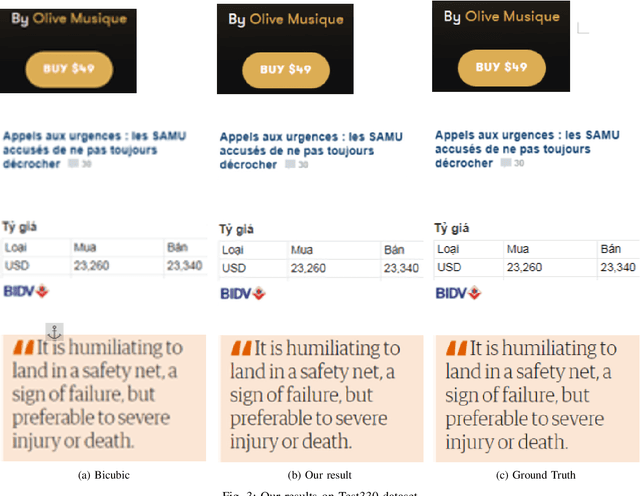

Recent research on super-resolution (SR) has witnessed major developments with the advancements of deep convolutional neural networks. There is a need for information extraction from scenic text images or even document images on device, most of which are low-resolution (LR) images. Therefore, SR becomes an essential pre-processing step as Bicubic Upsampling, which is conventionally present in smartphones, performs poorly on LR images. To give the user more control over his privacy, and to reduce the carbon footprint by reducing the overhead of cloud computing and hours of GPU usage, executing SR models on the edge is a necessity in the recent times. There are various challenges in running and optimizing a model on resource-constrained platforms like smartphones. In this paper, we present a novel deep neural network that reconstructs sharper character edges and thus boosts OCR confidence. The proposed architecture not only achieves significant improvement in PSNR over bicubic upsampling on various benchmark datasets but also runs with an average inference time of 11.7 ms per image. We have outperformed state-of-the-art on the Text330 dataset. We also achieve an OCR accuracy of 75.89% on the ICDAR 2015 TextSR dataset, where ground truth has an accuracy of 78.10%.