 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic galaxy image simulation via score-based generative models
Nov 02, 2021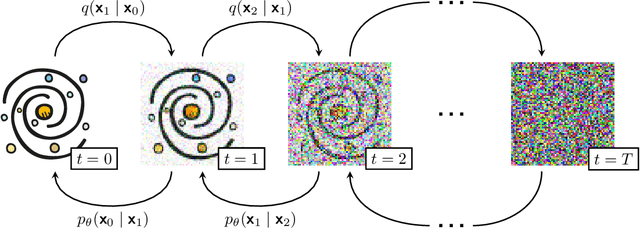

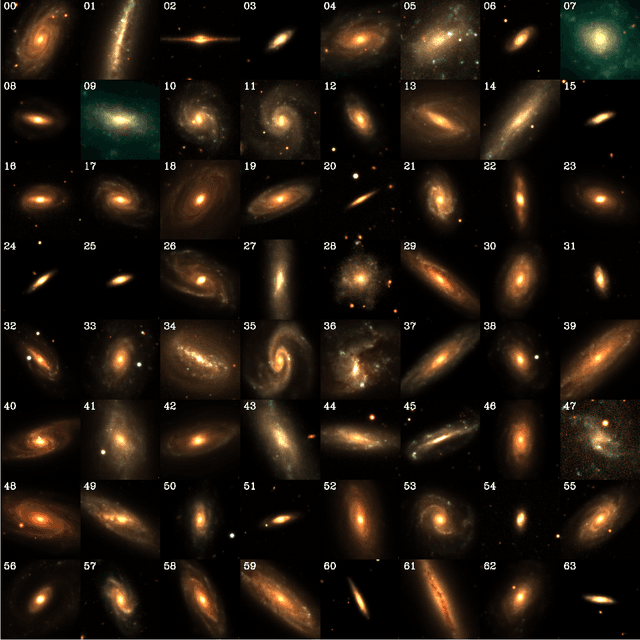

We show that a Denoising Diffusion Probabalistic Model (DDPM), a class of score-based generative model, can be used to produce realistic yet fake images that mimic observations of galaxies. Our method is tested with Dark Energy Spectroscopic Instrument grz imaging of galaxies from the Photometry and Rotation curve OBservations from Extragalactic Surveys (PROBES) sample and galaxies selected from the Sloan Digital Sky Survey. Subjectively, the generated galaxies are highly realistic when compared with samples from the real dataset. We quantify the similarity by borrowing from the deep generative learning literature, using the `Fr\'echet Inception Distance' to test for subjective and morphological similarity. We also introduce the `Synthetic Galaxy Distance' metric to compare the emergent physical properties (such as total magnitude, colour and half light radius) of a ground truth parent and synthesised child dataset. We argue that the DDPM approach produces sharper and more realistic images than other generative methods such as Adversarial Networks (with the downside of more costly inference), and could be used to produce large samples of synthetic observations tailored to a specific imaging survey. We demonstrate two potential uses of the DDPM: (1) accurate in-painting of occluded data, such as satellite trails, and (2) domain transfer, where new input images can be processed to mimic the properties of the DDPM training set. Here we `DESI-fy' cartoon images as a proof of concept for domain transfer. Finally, we suggest potential applications for score-based approaches that could motivate further research on this topic within the astronomical community.
STRIDE : Scene Text Recognition In-Device
May 17, 2021
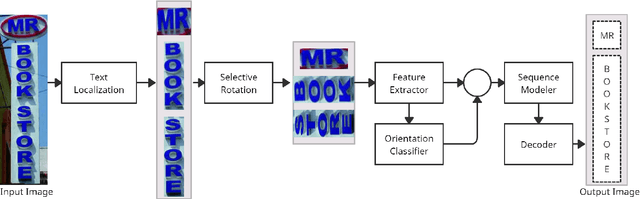
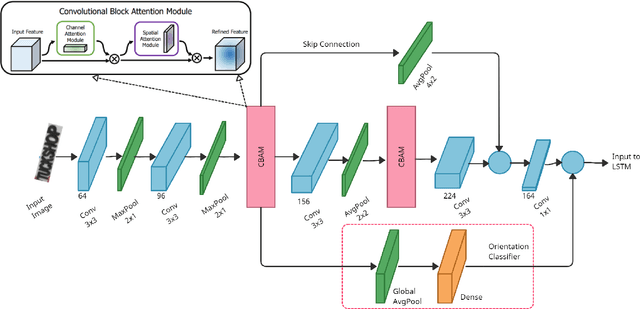

Optical Character Recognition (OCR) systems have been widely used in various applications for extracting semantic information from images. To give the user more control over their privacy, an on-device solution is needed. The current state-of-the-art models are too heavy and complex to be deployed on-device. We develop an efficient lightweight scene text recognition (STR) system, which has only 0.88M parameters and performs real-time text recognition. Attention modules tend to boost the accuracy of STR networks but are generally slow and not optimized for device inference. So, we propose the use of convolution attention modules to the text recognition networks, which aims to provide channel and spatial attention information to the LSTM module by adding very minimal computational cost. It boosts our word accuracy on ICDAR 13 dataset by almost 2\%. We also introduce a novel orientation classifier module, to support the simultaneous recognition of both horizontal and vertical text. The proposed model surpasses on-device metrics of inference time and memory footprint and achieves comparable accuracy when compared to the leading commercial and other open-source OCR engines. We deploy the system on-device with an inference speed of 2.44 ms per word on the Exynos 990 chipset device and achieve an accuracy of 88.4\% on ICDAR-13 dataset.
On-Device Sentence Similarity for SMS Dataset
Dec 04, 2020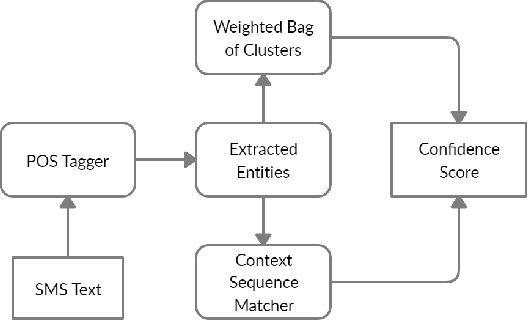

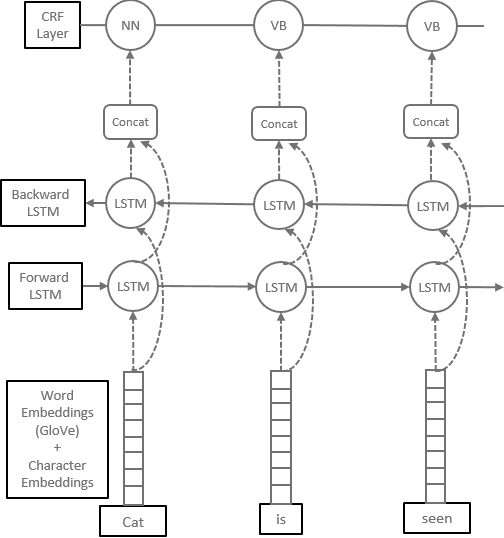
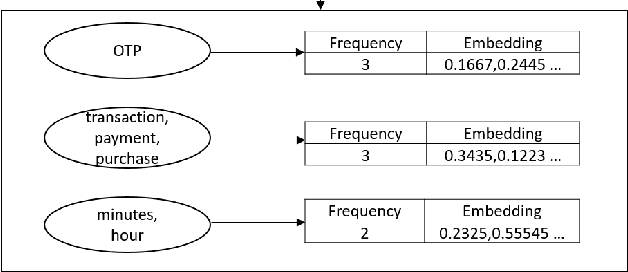
Determining the sentence similarity between Short Message Service (SMS) texts/sentences plays a significant role in mobile device industry. Gauging the similarity between SMS data is thus necessary for various applications like enhanced searching and navigation, clubbing together SMS of similar type when given a custom label or tag is provided by user irrespective of their sender etc. The problem faced with SMS data is its incomplete structure and grammatical inconsistencies. In this paper, we propose a unique pipeline for evaluating the text similarity between SMS texts. We use Part of Speech (POS) model for keyword extraction by taking advantage of the partial structure embedded in SMS texts and similarity comparisons are carried out using statistical methods. The proposed pipeline deals with major semantic variations across SMS data as well as makes it effective for its application on-device (mobile phone). To showcase the capabilities of our work, our pipeline has been designed with an inclination towards one of the possible applications of SMS text similarity discussed in one of the following sections but nonetheless guarantees scalability for other applications as well.
On-Device Language Identification of Text in Images using Diacritic Characters
Nov 10, 2020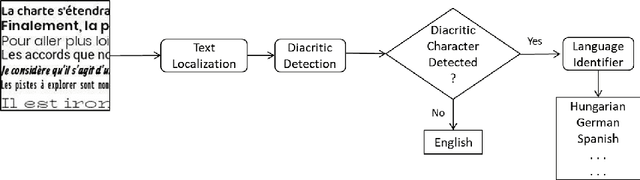


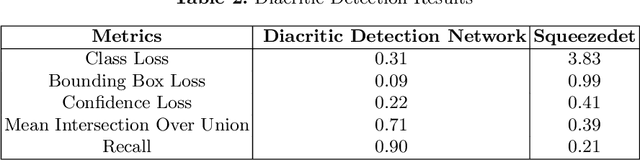
Diacritic characters can be considered as a unique set of characters providing us with adequate and significant clue in identifying a given language with considerably high accuracy. Diacritics, though associated with phonetics often serve as a distinguishing feature for many languages especially the ones with a Latin script. In this proposed work, we aim to identify language of text in images using the presence of diacritic characters in order to improve Optical Character Recognition (OCR) performance in any given automated environment. We showcase our work across 13 Latin languages encompassing 85 diacritic characters. We use an architecture similar to Squeezedet for object detection of diacritic characters followed by a shallow network to finally identify the language. OCR systems when accompanied with identified language parameter tends to produce better results than sole deployment of OCR systems. The discussed work apart from guaranteeing an improvement in OCR results also takes on-device (mobile phone) constraints into consideration in terms of model size and inference time.
Pix2Prof: fast extraction of sequential information from galaxy imagery via deep learning
Oct 01, 2020
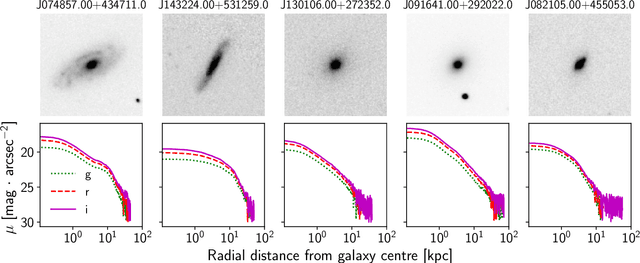
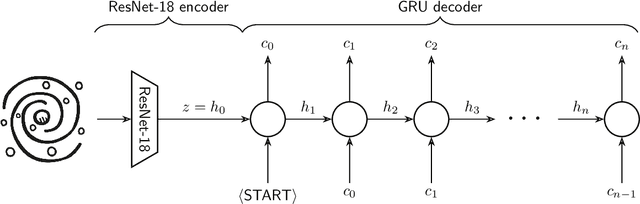
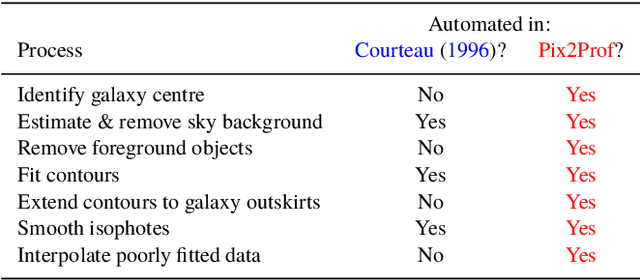
We present "Pix2Prof", a deep learning model that eliminates manual steps in the measurement of galaxy surface brightness (SB) profiles. We argue that a galaxy "profile" of any sort is conceptually similar to an image caption. This idea allows us to leverage image captioning methods from the field of natural language processing, and so we design Pix2Prof as a float sequence "captioning" model suitable for SB profile inferral. We demonstrate the technique by approximating the galaxy SB fitting method described by Courteau (1996), an algorithm with several manual steps. We use g, r, and i-band images from the Sloan Digital Sky Survey (SDSS) Data Release 10 (DR10) to train Pix2Prof on 5367 image--SB profile pairs. We test Pix2Prof on 300 SDSS DR10 galaxy image--SB profile pairs in each of the g, r, and i bands to calibrate the mean SB deviation between interactive manual measurements and automated extractions, and demonstrate the effectiveness of Pix2Prof in mirroring the manual method. Pix2Prof processes $\sim1$ image per second on an Intel Xeon E5-2650 v3 and $\sim2$ images per second on a NVIDIA TESLA V100, improving on the speed of the manual interactive method by more than two orders of magnitude. Crucially, Pix2Prof requires no manual interaction, and since galaxy profile estimation is an embarrassingly parallel problem, we can further increase the throughput by running many Pix2Prof instances simultaneously. In perspective, Pix2Prof would take under an hour to infer profiles for $10^5$ galaxies on a single NVIDIA DGX-2 system. A single human expert would take approximately two years to complete the same task. Automated methodology such as this will accelerate the analysis of the next generation of large area sky surveys expected to yield hundreds of millions of targets. In such instances, all manual approaches -- even those involving a large number of experts -- would be impractical.