 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Labeling Refinement for Robust Representation Learning with Bootstrap Your Own Latent
Apr 09, 2022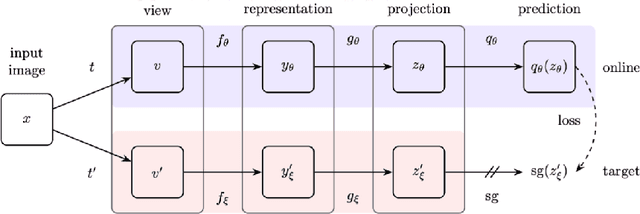
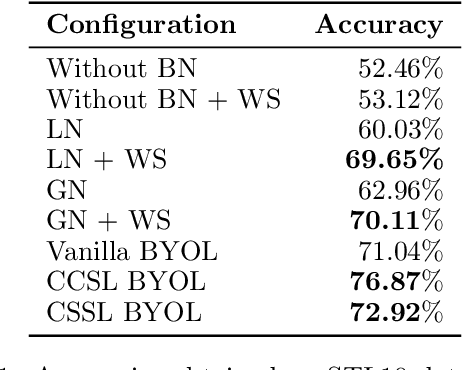
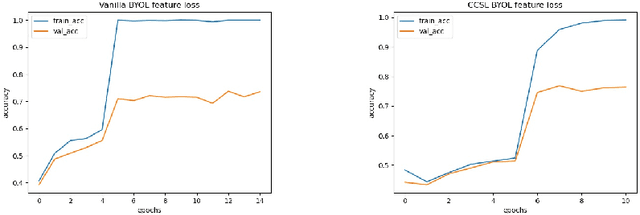
In this work, we have worked towards two major goals. Firstly, we have investigated the importance of Batch Normalisation (BN) layers in a non-contrastive representation learning framework called Bootstrap Your Own Latent (BYOL). We conducted several experiments to conclude that BN layers are not necessary for representation learning in BYOL. Moreover, BYOL only learns from the positive pairs of images but ignores other semantically similar images in the same input batch. For the second goal, we have introduced two new loss functions to determine the semantically similar pairs in the same input batch of images and reduce the distance between their representations. These loss functions are Cross-Cosine Similarity Loss (CCSL) and Cross-Sigmoid Similarity Loss (CSSL). Using the proposed loss functions, we are able to surpass the performance of Vanilla BYOL (71.04%) by training the BYOL framework using CCSL loss (76.87%) on the STL10 dataset. BYOL trained using CSSL loss performs comparably with Vanilla BYOL.
Codeswitched Sentence Creation using Dependency Parsing
Dec 05, 2020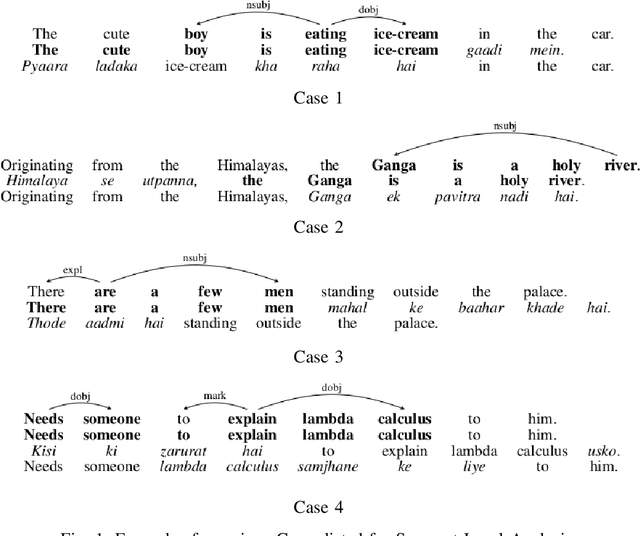
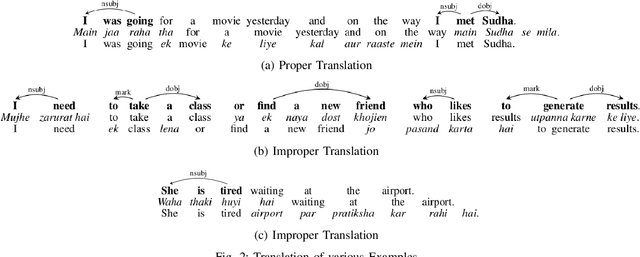

Codeswitching has become one of the most common occurrences across multilingual speakers of the world, especially in countries like India which encompasses around 23 official languages with the number of bilingual speakers being around 300 million. The scarcity of Codeswitched data becomes a bottleneck in the exploration of this domain with respect to various Natural Language Processing (NLP) tasks. We thus present a novel algorithm which harnesses the syntactic structure of English grammar to develop grammatically sensible Codeswitched versions of English-Hindi, English-Marathi and English-Kannada data. Apart from maintaining the grammatical sanity to a great extent, our methodology also guarantees abundant generation of data from a minuscule snapshot of given data. We use multiple datasets to showcase the capabilities of our algorithm while at the same time we assess the quality of generated Codeswitched data using some qualitative metrics along with providing baseline results for couple of NLP tasks.
On-Device Text Image Super Resolution
Nov 20, 2020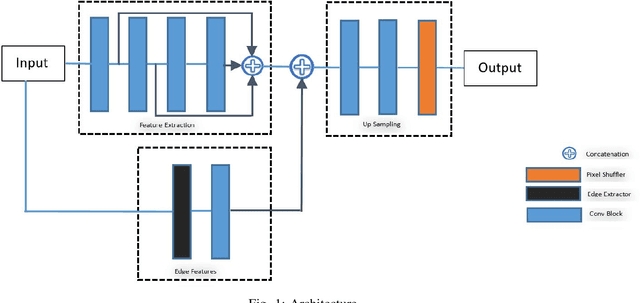

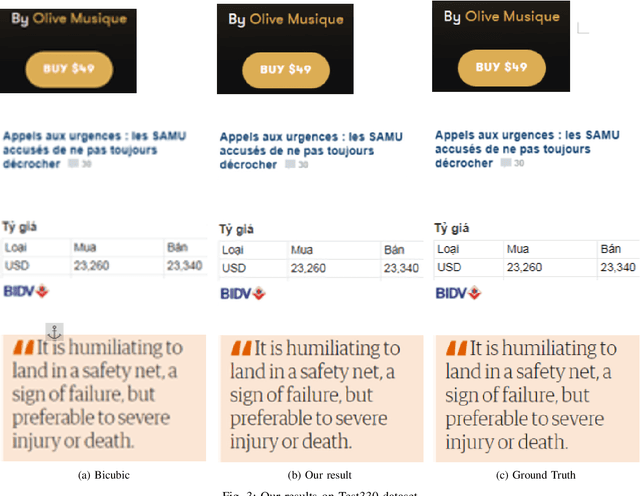

Recent research on super-resolution (SR) has witnessed major developments with the advancements of deep convolutional neural networks. There is a need for information extraction from scenic text images or even document images on device, most of which are low-resolution (LR) images. Therefore, SR becomes an essential pre-processing step as Bicubic Upsampling, which is conventionally present in smartphones, performs poorly on LR images. To give the user more control over his privacy, and to reduce the carbon footprint by reducing the overhead of cloud computing and hours of GPU usage, executing SR models on the edge is a necessity in the recent times. There are various challenges in running and optimizing a model on resource-constrained platforms like smartphones. In this paper, we present a novel deep neural network that reconstructs sharper character edges and thus boosts OCR confidence. The proposed architecture not only achieves significant improvement in PSNR over bicubic upsampling on various benchmark datasets but also runs with an average inference time of 11.7 ms per image. We have outperformed state-of-the-art on the Text330 dataset. We also achieve an OCR accuracy of 75.89% on the ICDAR 2015 TextSR dataset, where ground truth has an accuracy of 78.10%.
On-Device Language Identification of Text in Images using Diacritic Characters
Nov 10, 2020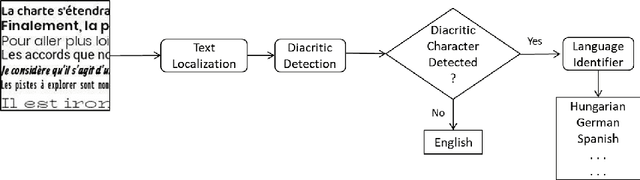


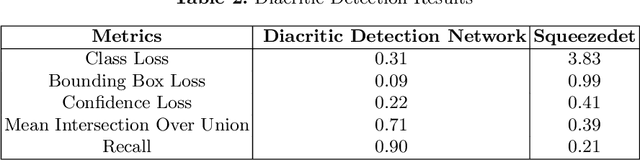
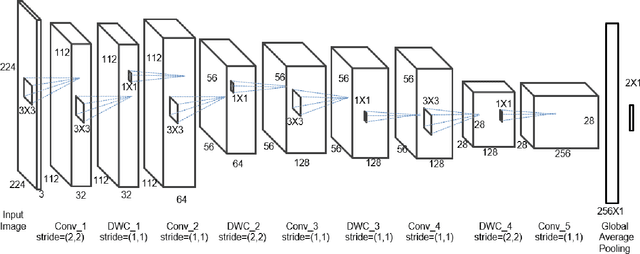
Diacritic characters can be considered as a unique set of characters providing us with adequate and significant clue in identifying a given language with considerably high accuracy. Diacritics, though associated with phonetics often serve as a distinguishing feature for many languages especially the ones with a Latin script. In this proposed work, we aim to identify language of text in images using the presence of diacritic characters in order to improve Optical Character Recognition (OCR) performance in any given automated environment. We showcase our work across 13 Latin languages encompassing 85 diacritic characters. We use an architecture similar to Squeezedet for object detection of diacritic characters followed by a shallow network to finally identify the language. OCR systems when accompanied with identified language parameter tends to produce better results than sole deployment of OCR systems. The discussed work apart from guaranteeing an improvement in OCR results also takes on-device (mobile phone) constraints into consideration in terms of model size and inference time.
On-device Filtering of Social Media Images for Efficient Storage
Apr 06, 2020


Artificially crafted images such as memes, seasonal greetings, etc are flooding the social media platforms today. These eventually start occupying a lot of internal memory of smartphones and it gets cumbersome for the user to go through hundreds of images and delete these synthetic images. To address this, we propose a novel method based on Convolutional Neural Networks (CNNs) for the on-device filtering of social media images by classifying these synthetic images and allowing the user to delete them in one go. The custom model uses depthwise separable convolution layers to achieve low inference time on smartphones. We have done an extensive evaluation of our model on various camera image datasets to cover most aspects of images captured by a camera. Various sorts of synthetic social media images have also been tested. The proposed solution achieves an accuracy of 98.25% on the Places-365 dataset and 95.81% on the Synthetic image dataset that we have prepared containing 30K instances.