 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Retrieval Complexity in Question Answering Systems
Jun 05, 2024In this paper, we investigate which questions are challenging for retrieval-based Question Answering (QA). We (i) propose retrieval complexity (RC), a novel metric conditioned on the completeness of retrieved documents, which measures the difficulty of answering questions, and (ii) propose an unsupervised pipeline to measure RC given an arbitrary retrieval system. Our proposed pipeline measures RC more accurately than alternative estimators, including LLMs, on six challenging QA benchmarks. Further investigation reveals that RC scores strongly correlate with both QA performance and expert judgment across five of the six studied benchmarks, indicating that RC is an effective measure of question difficulty. Subsequent categorization of high-RC questions shows that they span a broad set of question shapes, including multi-hop, compositional, and temporal QA, indicating that RC scores can categorize a new subset of complex questions. Our system can also have a major impact on retrieval-based systems by helping to identify more challenging questions on existing datasets.
SQUARE: Automatic Question Answering Evaluation using Multiple Positive and Negative References
Sep 21, 2023



Evaluation of QA systems is very challenging and expensive, with the most reliable approach being human annotations of correctness of answers for questions. Recent works (AVA, BEM) have shown that transformer LM encoder based similarity metrics transfer well for QA evaluation, but they are limited by the usage of a single correct reference answer. We propose a new evaluation metric: SQuArE (Sentence-level QUestion AnsweRing Evaluation), using multiple reference answers (combining multiple correct and incorrect references) for sentence-form QA. We evaluate SQuArE on both sentence-level extractive (Answer Selection) and generative (GenQA) QA systems, across multiple academic and industrial datasets, and show that it outperforms previous baselines and obtains the highest correlation with human annotations.
Learning Answer Generation using Supervision from Automatic Question Answering Evaluators
May 24, 2023



Recent studies show that sentence-level extractive QA, i.e., based on Answer Sentence Selection (AS2), is outperformed by Generation-based QA (GenQA) models, which generate answers using the top-k answer sentences ranked by AS2 models (a la retrieval-augmented generation style). In this paper, we propose a novel training paradigm for GenQA using supervision from automatic QA evaluation models (GAVA). Specifically, we propose three strategies to transfer knowledge from these QA evaluation models to a GenQA model: (i) augmenting training data with answers generated by the GenQA model and labelled by GAVA (either statically, before training, or (ii) dynamically, at every training epoch); and (iii) using the GAVA score for weighting the generator loss during the learning of the GenQA model. We evaluate our proposed methods on two academic and one industrial dataset, obtaining a significant improvement in answering accuracy over the previous state of the art.
Context-Aware Transformer Pre-Training for Answer Sentence Selection
May 24, 2023



Answer Sentence Selection (AS2) is a core component for building an accurate Question Answering pipeline. AS2 models rank a set of candidate sentences based on how likely they answer a given question. The state of the art in AS2 exploits pre-trained transformers by transferring them on large annotated datasets, while using local contextual information around the candidate sentence. In this paper, we propose three pre-training objectives designed to mimic the downstream fine-tuning task of contextual AS2. This allows for specializing LMs when fine-tuning for contextual AS2. Our experiments on three public and two large-scale industrial datasets show that our pre-training approaches (applied to RoBERTa and ELECTRA) can improve baseline contextual AS2 accuracy by up to 8% on some datasets.
Structured Pruning for Multi-Task Deep Neural Networks
Apr 13, 2023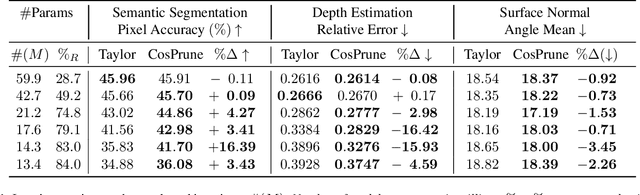
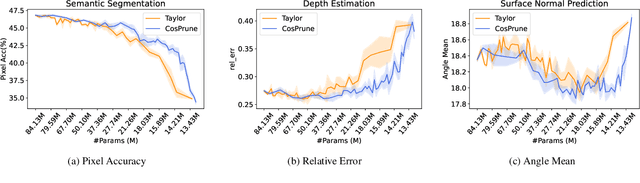
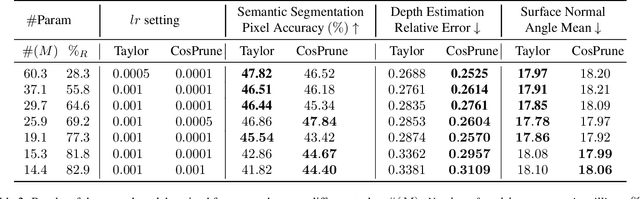
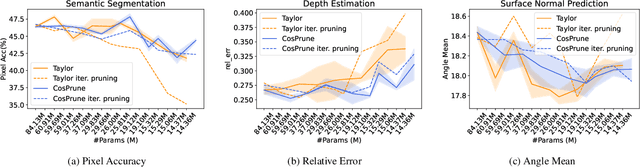
Although multi-task deep neural network (DNN) models have computation and storage benefits over individual single-task DNN models, they can be further optimized via model compression. Numerous structured pruning methods are already developed that can readily achieve speedups in single-task models, but the pruning of multi-task networks has not yet been extensively studied. In this work, we investigate the effectiveness of structured pruning on multi-task models. We use an existing single-task filter pruning criterion and also introduce an MTL-based filter pruning criterion for estimating the filter importance scores. We prune the model using an iterative pruning strategy with both pruning methods. We show that, with careful hyper-parameter tuning, architectures obtained from different pruning methods do not have significant differences in their performances across tasks when the number of parameters is similar. We also show that iterative structure pruning may not be the best way to achieve a well-performing pruned model because, at extreme pruning levels, there is a high drop in performance across all tasks. But when the same models are randomly initialized and re-trained, they show better results.
Knowledge Transfer from Answer Ranking to Answer Generation
Oct 23, 2022Recent studies show that Question Answering (QA) based on Answer Sentence Selection (AS2) can be improved by generating an improved answer from the top-k ranked answer sentences (termed GenQA). This allows for synthesizing the information from multiple candidates into a concise, natural-sounding answer. However, creating large-scale supervised training data for GenQA models is very challenging. In this paper, we propose to train a GenQA model by transferring knowledge from a trained AS2 model, to overcome the aforementioned issue. First, we use an AS2 model to produce a ranking over answer candidates for a set of questions. Then, we use the top ranked candidate as the generation target, and the next k top ranked candidates as context for training a GenQA model. We also propose to use the AS2 model prediction scores for loss weighting and score-conditioned input/output shaping, to aid the knowledge transfer. Our evaluation on three public and one large industrial datasets demonstrates the superiority of our approach over the AS2 baseline, and GenQA trained using supervised data.
SeRP: Self-Supervised Representation Learning Using Perturbed Point Clouds
Sep 13, 2022
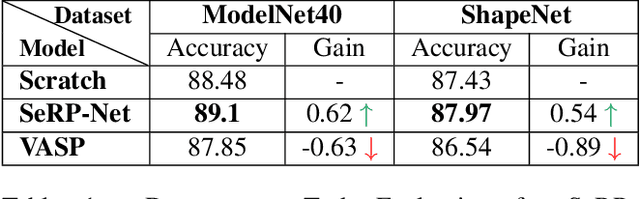
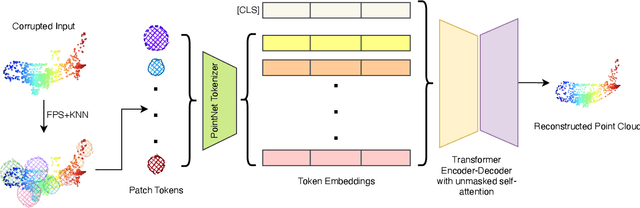
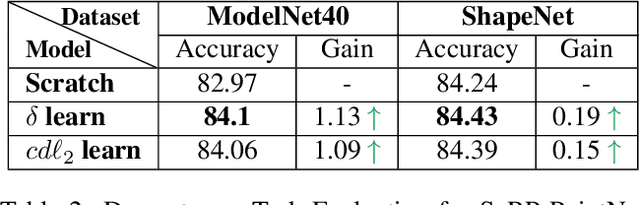
We present SeRP, a framework for Self-Supervised Learning of 3D point clouds. SeRP consists of encoder-decoder architecture that takes perturbed or corrupted point clouds as inputs and aims to reconstruct the original point cloud without corruption. The encoder learns the high-level latent representations of the points clouds in a low-dimensional subspace and recovers the original structure. In this work, we have used Transformers and PointNet-based Autoencoders. The proposed framework also addresses some of the limitations of Transformers-based Masked Autoencoders which are prone to leakage of location information and uneven information density. We trained our models on the complete ShapeNet dataset and evaluated them on ModelNet40 as a downstream classification task. We have shown that the pretrained models achieved 0.5-1% higher classification accuracies than the networks trained from scratch. Furthermore, we also proposed VASP: Vector-Quantized Autoencoder for Self-supervised Representation Learning for Point Clouds that employs Vector-Quantization for discrete representation learning for Transformer-based autoencoders.
Pre-training Transformer Models with Sentence-Level Objectives for Answer Sentence Selection
May 20, 2022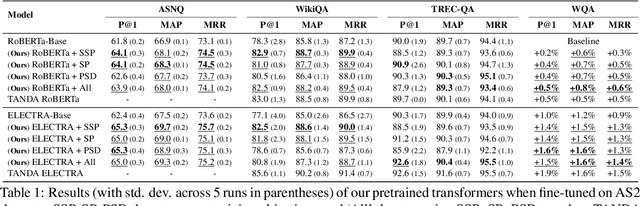
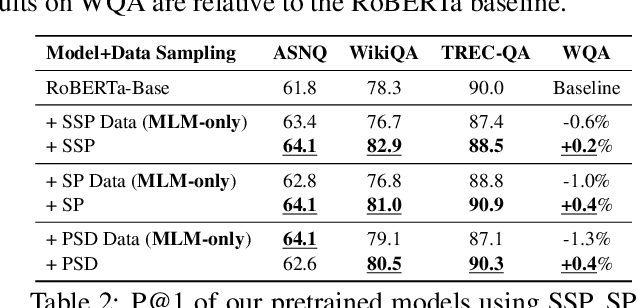
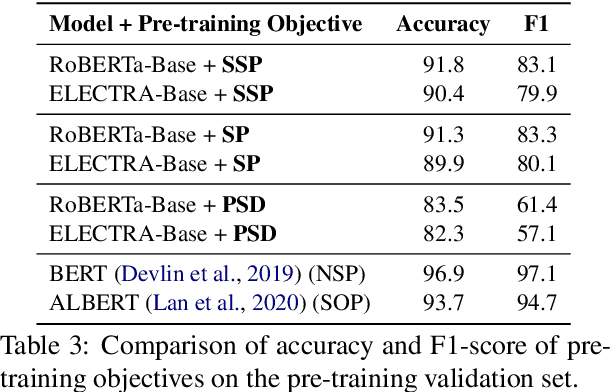
An important task for designing QA systems is answer sentence selection (AS2): selecting the sentence containing (or constituting) the answer to a question from a set of retrieved relevant documents. In this paper, we propose three novel sentence-level transformer pre-training objectives that incorporate paragraph-level semantics within and across documents, to improve the performance of transformers for AS2, and mitigate the requirement of large labeled datasets. Our experiments on three public and one industrial AS2 datasets demonstrate the empirical superiority of our pre-trained transformers over baseline models such as RoBERTa and ELECTRA for AS2.
Paragraph-based Transformer Pre-training for Multi-Sentence Inference
May 02, 2022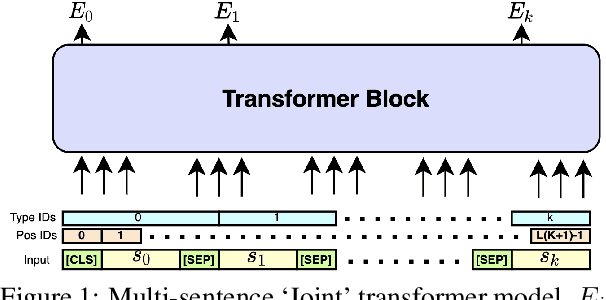
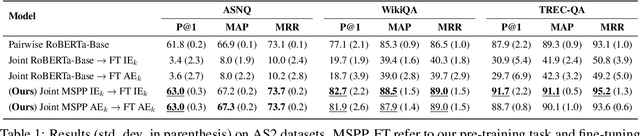
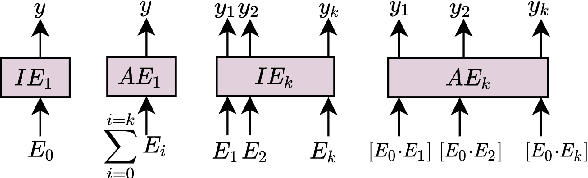
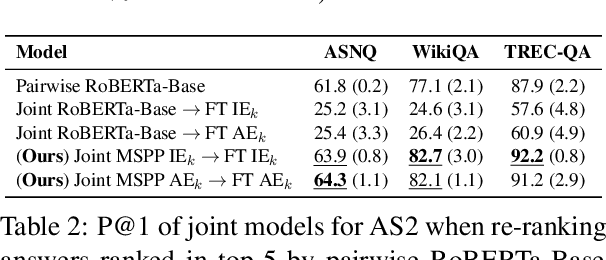
Inference tasks such as answer sentence selection (AS2) or fact verification are typically solved by fine-tuning transformer-based models as individual sentence-pair classifiers. Recent studies show that these tasks benefit from modeling dependencies across multiple candidate sentences jointly. In this paper, we first show that popular pre-trained transformers perform poorly when used for fine-tuning on multi-candidate inference tasks. We then propose a new pre-training objective that models the paragraph-level semantics across multiple input sentences. Our evaluation on three AS2 and one fact verification datasets demonstrates the superiority of our pre-training technique over the traditional ones for transformers used as joint models for multi-candidate inference tasks, as well as when used as cross-encoders for sentence-pair formulations of these tasks.
Self-Labeling Refinement for Robust Representation Learning with Bootstrap Your Own Latent
Apr 09, 2022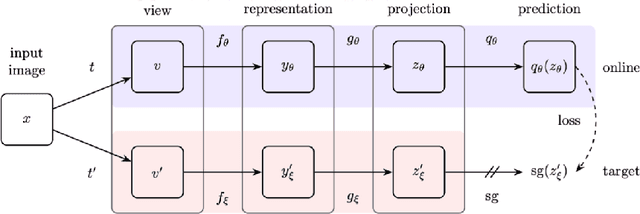
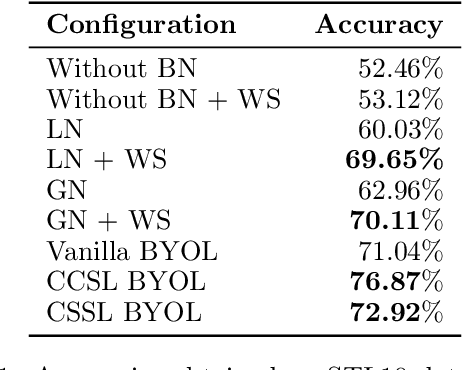
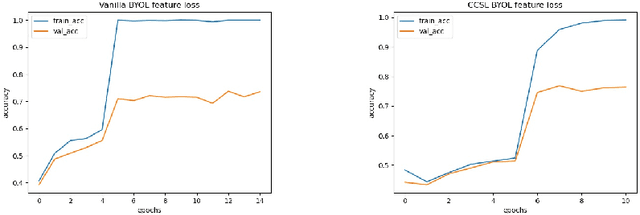
In this work, we have worked towards two major goals. Firstly, we have investigated the importance of Batch Normalisation (BN) layers in a non-contrastive representation learning framework called Bootstrap Your Own Latent (BYOL). We conducted several experiments to conclude that BN layers are not necessary for representation learning in BYOL. Moreover, BYOL only learns from the positive pairs of images but ignores other semantically similar images in the same input batch. For the second goal, we have introduced two new loss functions to determine the semantically similar pairs in the same input batch of images and reduce the distance between their representations. These loss functions are Cross-Cosine Similarity Loss (CCSL) and Cross-Sigmoid Similarity Loss (CSSL). Using the proposed loss functions, we are able to surpass the performance of Vanilla BYOL (71.04%) by training the BYOL framework using CCSL loss (76.87%) on the STL10 dataset. BYOL trained using CSSL loss performs comparably with Vanilla BYOL.