 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Loss Functions for Neuro-Symbolic Structured Prediction
May 12, 2024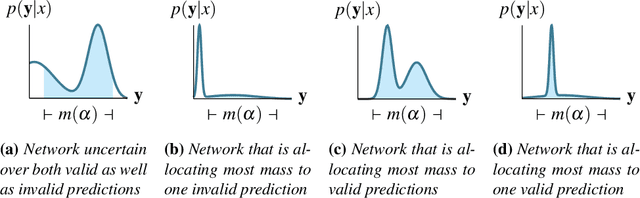
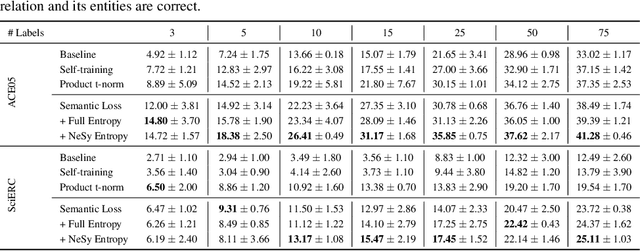
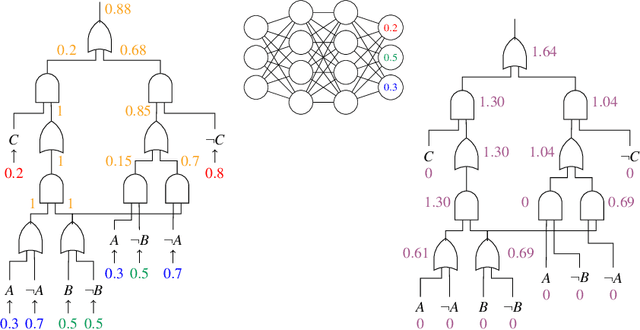
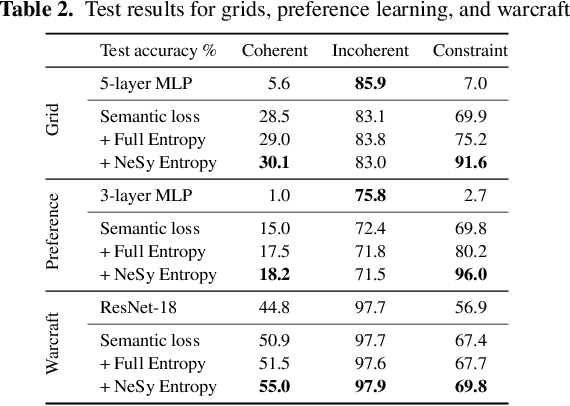
Structured output prediction problems are ubiquitous in machine learning. The prominent approach leverages neural networks as powerful feature extractors, otherwise assuming the independence of the outputs. These outputs, however, jointly encode an object, e.g. a path in a graph, and are therefore related through the structure underlying the output space. We discuss the semantic loss, which injects knowledge about such structure, defined symbolically, into training by minimizing the network's violation of such dependencies, steering the network towards predicting distributions satisfying the underlying structure. At the same time, it is agnostic to the arrangement of the symbols, and depends only on the semantics expressed thereby, while also enabling efficient end-to-end training and inference. We also discuss key improvements and applications of the semantic loss. One limitations of the semantic loss is that it does not exploit the association of every data point with certain features certifying its membership in a target class. We should therefore prefer minimum-entropy distributions over valid structures, which we obtain by additionally minimizing the neuro-symbolic entropy. We empirically demonstrate the benefits of this more refined formulation. Moreover, the semantic loss is designed to be modular and can be combined with both discriminative and generative neural models. This is illustrated by integrating it into generative adversarial networks, yielding constrained adversarial networks, a novel class of deep generative models able to efficiently synthesize complex objects obeying the structure of the underlying domain.
Structural Self-Supervised Objectives for Transformers
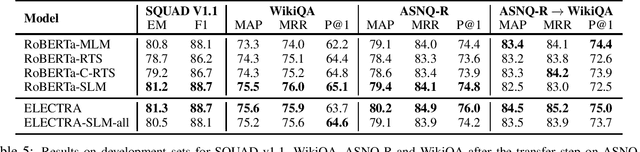
Sep 15, 2023This thesis focuses on improving the pre-training of natural language models using unsupervised raw data to make them more efficient and aligned with downstream applications. In the first part, we introduce three alternative pre-training objectives to BERT's Masked Language Modeling (MLM), namely Random Token Substitution (RTS), Cluster-based Random Token Substitution (C-RTS), and Swapped Language Modeling (SLM). These objectives involve token swapping instead of masking, with RTS and C-RTS aiming to predict token originality and SLM predicting the original token values. Results show that RTS and C-RTS require less pre-training time while maintaining performance comparable to MLM. Surprisingly, SLM outperforms MLM on certain tasks despite using the same computational budget. In the second part, we proposes self-supervised pre-training tasks that align structurally with downstream applications, reducing the need for labeled data. We use large corpora like Wikipedia and CC-News to train models to recognize if text spans originate from the same paragraph or document in several ways. By doing continuous pre-training, starting from existing models like RoBERTa, ELECTRA, DeBERTa, BART, and T5, we demonstrate significant performance improvements in tasks like Fact Verification, Answer Sentence Selection, and Summarization. These improvements are especially pronounced when limited annotation data is available. The proposed objectives also achieve state-of-the-art results on various benchmark datasets, including FEVER (dev set), ASNQ, WikiQA, and TREC-QA, as well as enhancing the quality of summaries. Importantly, these techniques can be easily integrated with other methods without altering the internal structure of Transformer models, making them versatile for various NLP applications.
Context-Aware Transformer Pre-Training for Answer Sentence Selection
May 24, 2023



Answer Sentence Selection (AS2) is a core component for building an accurate Question Answering pipeline. AS2 models rank a set of candidate sentences based on how likely they answer a given question. The state of the art in AS2 exploits pre-trained transformers by transferring them on large annotated datasets, while using local contextual information around the candidate sentence. In this paper, we propose three pre-training objectives designed to mimic the downstream fine-tuning task of contextual AS2. This allows for specializing LMs when fine-tuning for contextual AS2. Our experiments on three public and two large-scale industrial datasets show that our pre-training approaches (applied to RoBERTa and ELECTRA) can improve baseline contextual AS2 accuracy by up to 8% on some datasets.
Effective Pre-Training Objectives for Transformer-based Autoencoders
Oct 24, 2022In this paper, we study trade-offs between efficiency, cost and accuracy when pre-training Transformer encoders with different pre-training objectives. For this purpose, we analyze features of common objectives and combine them to create new effective pre-training approaches. Specifically, we designed light token generators based on a straightforward statistical approach, which can replace ELECTRA computationally heavy generators, thus highly reducing cost. Our experiments also show that (i) there are more efficient alternatives to BERT's MLM, and (ii) it is possible to efficiently pre-train Transformer-based models using lighter generators without a significant drop in performance.
Pre-training Transformer Models with Sentence-Level Objectives for Answer Sentence Selection
May 20, 2022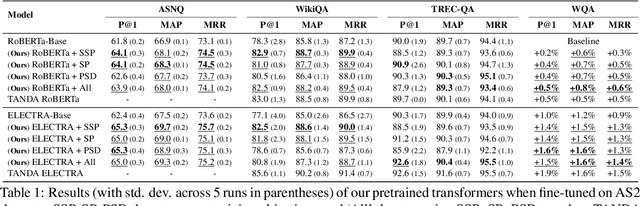
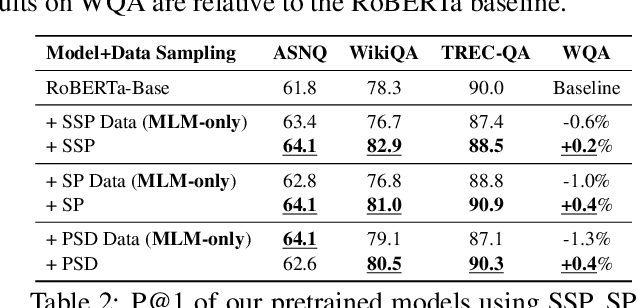
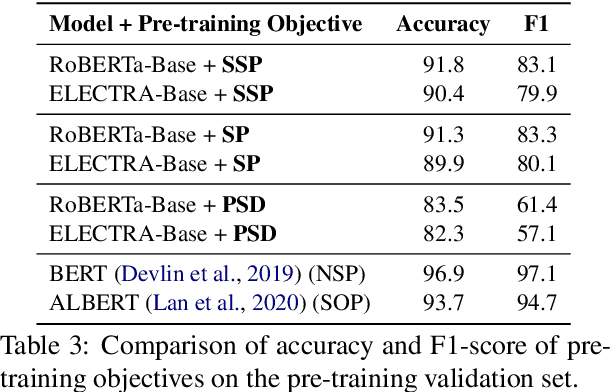
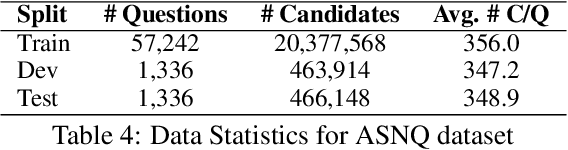
An important task for designing QA systems is answer sentence selection (AS2): selecting the sentence containing (or constituting) the answer to a question from a set of retrieved relevant documents. In this paper, we propose three novel sentence-level transformer pre-training objectives that incorporate paragraph-level semantics within and across documents, to improve the performance of transformers for AS2, and mitigate the requirement of large labeled datasets. Our experiments on three public and one industrial AS2 datasets demonstrate the empirical superiority of our pre-trained transformers over baseline models such as RoBERTa and ELECTRA for AS2.
Paragraph-based Transformer Pre-training for Multi-Sentence Inference
May 02, 2022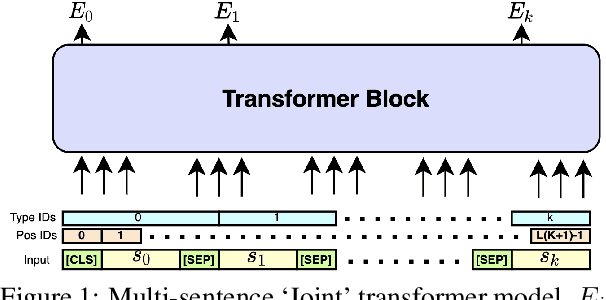
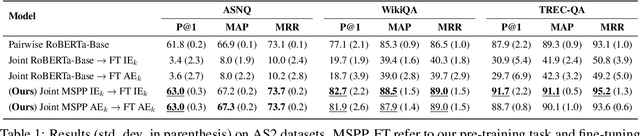
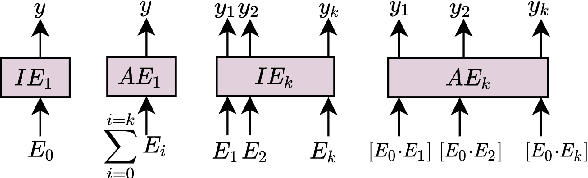
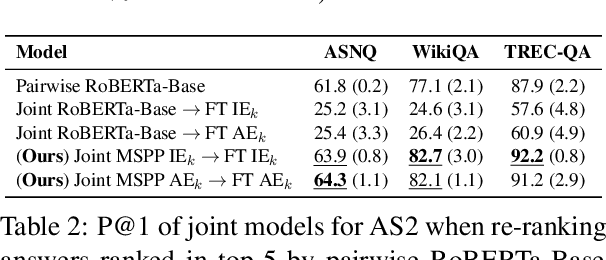
Inference tasks such as answer sentence selection (AS2) or fact verification are typically solved by fine-tuning transformer-based models as individual sentence-pair classifiers. Recent studies show that these tasks benefit from modeling dependencies across multiple candidate sentences jointly. In this paper, we first show that popular pre-trained transformers perform poorly when used for fine-tuning on multi-candidate inference tasks. We then propose a new pre-training objective that models the paragraph-level semantics across multiple input sentences. Our evaluation on three AS2 and one fact verification datasets demonstrates the superiority of our pre-training technique over the traditional ones for transformers used as joint models for multi-candidate inference tasks, as well as when used as cross-encoders for sentence-pair formulations of these tasks.
Efficient pre-training objectives for Transformers
Apr 20, 2021


The Transformer architecture deeply changed the natural language processing, outperforming all previous state-of-the-art models. However, well-known Transformer models like BERT, RoBERTa, and GPT-2 require a huge compute budget to create a high quality contextualised representation. In this paper, we study several efficient pre-training objectives for Transformers-based models. By testing these objectives on different tasks, we determine which of the ELECTRA model's new features is the most relevant. We confirm that Transformers pre-training is improved when the input does not contain masked tokens and that the usage of the whole output to compute the loss reduces training time. Moreover, inspired by ELECTRA, we study a model composed of two blocks; a discriminator and a simple generator based on a statistical model with no impact on the computational performances. Besides, we prove that eliminating the MASK token and considering the whole output during the loss computation are essential choices to improve performance. Furthermore, we show that it is possible to efficiently train BERT-like models using a discriminative approach as in ELECTRA but without a complex generator, which is expensive. Finally, we show that ELECTRA benefits heavily from a state-of-the-art hyper-parameters search.
Efficient Generation of Structured Objects with Constrained Adversarial Networks
Jul 26, 2020


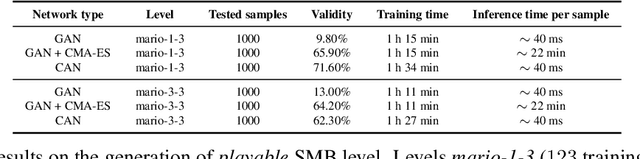
Generative Adversarial Networks (GANs) struggle to generate structured objects like molecules and game maps. The issue is that structured objects must satisfy hard requirements (e.g., molecules must be chemically valid) that are difficult to acquire from examples alone. As a remedy, we propose Constrained Adversarial Networks (CANs), an extension of GANs in which the constraints are embedded into the model during training. This is achieved by penalizing the generator proportionally to the mass it allocates to invalid structures. In contrast to other generative models, CANs support efficient inference of valid structures (with high probability) and allows to turn on and off the learned constraints at inference time. CANs handle arbitrary logical constraints and leverage knowledge compilation techniques to efficiently evaluate the disagreement between the model and the constraints. Our setup is further extended to hybrid logical-neural constraints for capturing very complex constraints, like graph reachability. An extensive empirical analysis shows that CANs efficiently generate valid structures that are both high-quality and novel.