 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Document Retrieval Coherence for Semantically Equivalent Queries
Aug 11, 2025Dense Retrieval (DR) models have proven to be effective for Document Retrieval and Information Grounding tasks. Usually, these models are trained and optimized for improving the relevance of top-ranked documents for a given query. Previous work has shown that popular DR models are sensitive to the query and document lexicon: small variations of it may lead to a significant difference in the set of retrieved documents. In this paper, we propose a variation of the Multi-Negative Ranking loss for training DR that improves the coherence of models in retrieving the same documents with respect to semantically similar queries. The loss penalizes discrepancies between the top-k ranked documents retrieved for diverse but semantic equivalent queries. We conducted extensive experiments on various datasets, MS-MARCO, Natural Questions, BEIR, and TREC DL 19/20. The results show that (i) models optimizes by our loss are subject to lower sensitivity, and, (ii) interestingly, higher accuracy.
Tuning-Free Personalized Alignment via Trial-Error-Explain In-Context Learning
Feb 13, 2025Language models are aligned to the collective voice of many, resulting in generic outputs that do not align with specific users' styles. In this work, we present Trial-Error-Explain In-Context Learning (TICL), a tuning-free method that personalizes language models for text generation tasks with fewer than 10 examples per user. TICL iteratively expands an in-context learning prompt via a trial-error-explain process, adding model-generated negative samples and explanations that provide fine-grained guidance towards a specific user's style. TICL achieves favorable win rates on pairwise comparisons with LLM-as-a-judge up to 91.5% against the previous state-of-the-art and outperforms competitive tuning-free baselines for personalized alignment tasks of writing emails, essays and news articles. Both lexical and qualitative analyses show that the negative samples and explanations enable language models to learn stylistic context more effectively and overcome the bias towards structural and formal phrases observed in their zero-shot outputs. By front-loading inference compute to create a user-specific in-context learning prompt that does not require extra generation steps at test time, TICL presents a novel yet simple approach for personalized alignment.
Datasets for Multilingual Answer Sentence Selection
Jun 14, 2024



Answer Sentence Selection (AS2) is a critical task for designing effective retrieval-based Question Answering (QA) systems. Most advancements in AS2 focus on English due to the scarcity of annotated datasets for other languages. This lack of resources prevents the training of effective AS2 models in different languages, creating a performance gap between QA systems in English and other locales. In this paper, we introduce new high-quality datasets for AS2 in five European languages (French, German, Italian, Portuguese, and Spanish), obtained through supervised Automatic Machine Translation (AMT) of existing English AS2 datasets such as ASNQ, WikiQA, and TREC-QA using a Large Language Model (LLM). We evaluated our approach and the quality of the translated datasets through multiple experiments with different Transformer architectures. The results indicate that our datasets are pivotal in producing robust and powerful multilingual AS2 models, significantly contributing to closing the performance gap between English and other languages.
Measuring Retrieval Complexity in Question Answering Systems
Jun 05, 2024In this paper, we investigate which questions are challenging for retrieval-based Question Answering (QA). We (i) propose retrieval complexity (RC), a novel metric conditioned on the completeness of retrieved documents, which measures the difficulty of answering questions, and (ii) propose an unsupervised pipeline to measure RC given an arbitrary retrieval system. Our proposed pipeline measures RC more accurately than alternative estimators, including LLMs, on six challenging QA benchmarks. Further investigation reveals that RC scores strongly correlate with both QA performance and expert judgment across five of the six studied benchmarks, indicating that RC is an effective measure of question difficulty. Subsequent categorization of high-RC questions shows that they span a broad set of question shapes, including multi-hop, compositional, and temporal QA, indicating that RC scores can categorize a new subset of complex questions. Our system can also have a major impact on retrieval-based systems by helping to identify more challenging questions on existing datasets.
SQUARE: Automatic Question Answering Evaluation using Multiple Positive and Negative References
Sep 21, 2023



Evaluation of QA systems is very challenging and expensive, with the most reliable approach being human annotations of correctness of answers for questions. Recent works (AVA, BEM) have shown that transformer LM encoder based similarity metrics transfer well for QA evaluation, but they are limited by the usage of a single correct reference answer. We propose a new evaluation metric: SQuArE (Sentence-level QUestion AnsweRing Evaluation), using multiple reference answers (combining multiple correct and incorrect references) for sentence-form QA. We evaluate SQuArE on both sentence-level extractive (Answer Selection) and generative (GenQA) QA systems, across multiple academic and industrial datasets, and show that it outperforms previous baselines and obtains the highest correlation with human annotations.
Cross-Lingual Knowledge Distillation for Answer Sentence Selection in Low-Resource Languages
May 25, 2023



While impressive performance has been achieved on the task of Answer Sentence Selection (AS2) for English, the same does not hold for languages that lack large labeled datasets. In this work, we propose Cross-Lingual Knowledge Distillation (CLKD) from a strong English AS2 teacher as a method to train AS2 models for low-resource languages in the tasks without the need of labeled data for the target language. To evaluate our method, we introduce 1) Xtr-WikiQA, a translation-based WikiQA dataset for 9 additional languages, and 2) TyDi-AS2, a multilingual AS2 dataset with over 70K questions spanning 8 typologically diverse languages. We conduct extensive experiments on Xtr-WikiQA and TyDi-AS2 with multiple teachers, diverse monolingual and multilingual pretrained language models (PLMs) as students, and both monolingual and multilingual training. The results demonstrate that CLKD either outperforms or rivals even supervised fine-tuning with the same amount of labeled data and a combination of machine translation and the teacher model. Our method can potentially enable stronger AS2 models for low-resource languages, while TyDi-AS2 can serve as the largest multilingual AS2 dataset for further studies in the research community.
Learning Answer Generation using Supervision from Automatic Question Answering Evaluators
May 24, 2023



Recent studies show that sentence-level extractive QA, i.e., based on Answer Sentence Selection (AS2), is outperformed by Generation-based QA (GenQA) models, which generate answers using the top-k answer sentences ranked by AS2 models (a la retrieval-augmented generation style). In this paper, we propose a novel training paradigm for GenQA using supervision from automatic QA evaluation models (GAVA). Specifically, we propose three strategies to transfer knowledge from these QA evaluation models to a GenQA model: (i) augmenting training data with answers generated by the GenQA model and labelled by GAVA (either statically, before training, or (ii) dynamically, at every training epoch); and (iii) using the GAVA score for weighting the generator loss during the learning of the GenQA model. We evaluate our proposed methods on two academic and one industrial dataset, obtaining a significant improvement in answering accuracy over the previous state of the art.
Context-Aware Transformer Pre-Training for Answer Sentence Selection
May 24, 2023



Answer Sentence Selection (AS2) is a core component for building an accurate Question Answering pipeline. AS2 models rank a set of candidate sentences based on how likely they answer a given question. The state of the art in AS2 exploits pre-trained transformers by transferring them on large annotated datasets, while using local contextual information around the candidate sentence. In this paper, we propose three pre-training objectives designed to mimic the downstream fine-tuning task of contextual AS2. This allows for specializing LMs when fine-tuning for contextual AS2. Our experiments on three public and two large-scale industrial datasets show that our pre-training approaches (applied to RoBERTa and ELECTRA) can improve baseline contextual AS2 accuracy by up to 8% on some datasets.
QUADRo: Dataset and Models for QUestion-Answer Database Retrieval
Mar 30, 2023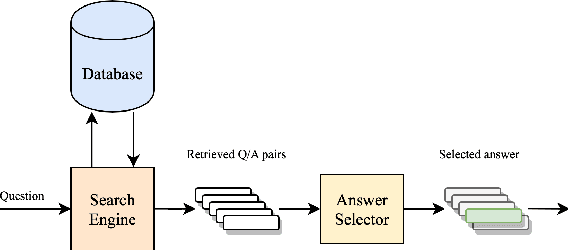
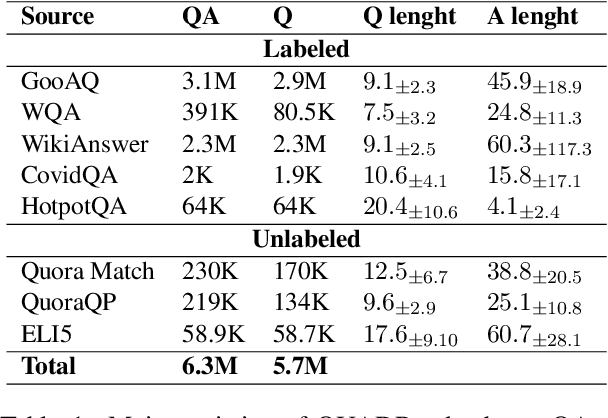
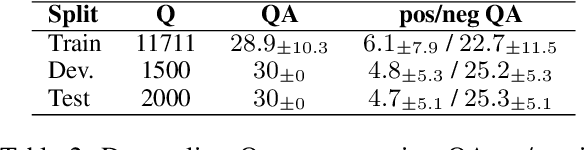
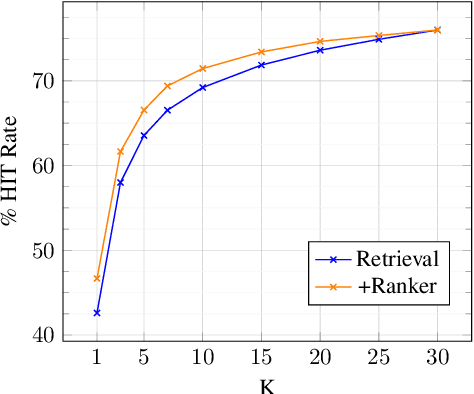
An effective paradigm for building Automated Question Answering systems is the re-use of previously answered questions, e.g., for FAQs or forum applications. Given a database (DB) of question/answer (q/a) pairs, it is possible to answer a target question by scanning the DB for similar questions. In this paper, we scale this approach to open domain, making it competitive with other standard methods, e.g., unstructured document or graph based. For this purpose, we (i) build a large scale DB of 6.3M q/a pairs, using public questions, (ii) design a new system based on neural IR and a q/a pair reranker, and (iii) construct training and test data to perform comparative experiments with our models. We demonstrate that Transformer-based models using (q,a) pairs outperform models only based on question representation, for both neural search and reranking. Additionally, we show that our DB-based approach is competitive with Web-based methods, i.e., a QA system built on top the BING search engine, demonstrating the challenge of finding relevant information. Finally, we make our data and models available for future research.
Effective Pre-Training Objectives for Transformer-based Autoencoders
Oct 24, 2022In this paper, we study trade-offs between efficiency, cost and accuracy when pre-training Transformer encoders with different pre-training objectives. For this purpose, we analyze features of common objectives and combine them to create new effective pre-training approaches. Specifically, we designed light token generators based on a straightforward statistical approach, which can replace ELECTRA computationally heavy generators, thus highly reducing cost. Our experiments also show that (i) there are more efficient alternatives to BERT's MLM, and (ii) it is possible to efficiently pre-train Transformer-based models using lighter generators without a significant drop in performance.